

随着大数据领域的不断发展,新的数据处理和分析工具不断涌现。在这些工具中,DuckDB 是个亮点,它是一个开源的数据库管理系统,使用 SQL 作为查询语言,旨在提供内存中分析的高性能解决方案。DuckDB 还支持与 pandas DataFrame 的无缝集成,可以便捷地与 pandas 等工具进行数据处理和分析。因此,DuckDB 是一个非常值得关注和探索的数据库管理系统。
1 DuckDB的崛起
DuckDB 是个正在快速崛起非常受欢迎的内置 SQL 分析引擎。统计数据如下:
·每月在 PyPI 上有 170 万次下载
· 在 GitHub 上有 13,800 个星标,在短短几年内已与 Postgres 达到了同样的欢迎程度

DuckDB 与 Postgres 的比较 - GitHub Star Rating
在可比的两年时间内,DuckDB 的增长速度与 Snowflake 相当,据 DB-Engines 趋势报告显示,DuckDB很可能在未来几年内成为主流,并至少取代目前在传统数据仓库中处理的一些负载。
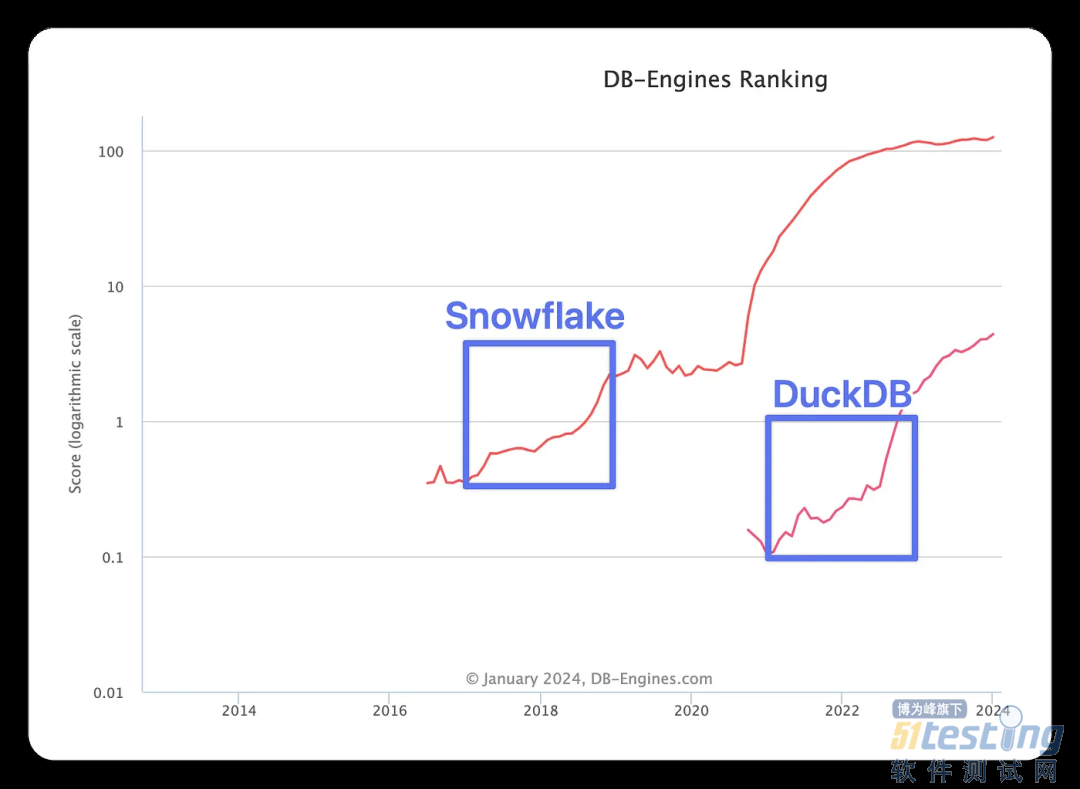
DuckDB 与 Snowflake 的比较 - DB Engines 排名
DuckDB 的 MIT 许可证保证其永久开源,这也增加了它的吸引力。
2 DuckDB 的优势
·易于安装:运行 DuckDB 只需执行一行命令brew install duckdb。
· 低复杂性:由于没有服务器(DuckDB 只是一个二进制文件),因此不需要处理凭证、访问控制列表、防火墙配置等问题。
· 通用兼容性:DuckDB 几乎没有依赖性,可以在浏览器中运行。
· 与 Pandas DataFrame 集成:DuckDB 的 Python 库具有查询 Pandas DataFrames 的能力。这种集成还使 DuckDB 能够在自己和其他无法直接查询的系统之间起到统一层或 "粘合剂" 的作用,促进了数据处理中的转换步骤。
· 扩展:DuckDB 具有灵活的扩展机制,这对于直接从 JSON 和 Parquet 或直接从 S3 读取数据特别重要,能够大大提高开发人员的体验。
· 稳定性和效率:DuckDB 旨在处理超出内存限制(虽然有一些限制)的工作负载。这在分析数据集大于可用 RAM 但小于磁盘容量的情况下特别重要,这使得分析工作可以使用 "便宜"且随时可用的硬件(如笔记本电脑)来完成。
3 DuckDB:实际数据流中的高效数据处理引擎
与基于云的系统相比,DuckDB 更具吸引力,因为它对硬件的要求较低且成本效益较高。从开发人员的笔记本电脑到生产设置,DuckDB 在各种环境中都保持一致,这与基于云的解决方案形成了鲜明对比,后者往往会随着时间的推移、数据的陈旧或无效而发生漂移。
DuckDB 可以在几乎任何地方轻松运行,有效地绕过分布式系统中常见的挑战,例如将数据移动到计算节点、VM/作业编排和故障处理。现代机器(基于云或由苹果公司 M1 SoC 驱动的机器)的能力进一步增强了 DuckDB 的实用性,可以在单机处理场景下处理大量数据集。尽管只有少数客户每天需要处理 TB 级别的数据,但实际上所需的计算能力超出了所有公有云现有的能力。
4 SQL "语法糖"
DuckDB 的相对新颖性使其能够灵活地引入新的 SQL 语法增强功能,如GROUP BY ALL、SELECT * EXCLUDE、ASOF JOINS等。这些新增功能使 SQL 查询更直观、更易读;请看下面的代码段:
-- 在 ANSI SQL 中按多个字段分组
SELECT country, city, region, postal_code, AVG(price) AS avg_price
FROM customers
-- 这里需要重复非分组字段
GROUP BY country, city, region, postal_code;
-- 在 DuckDB 中按所有字段分组
SELECT country, city, region, postal_code, AVG(price) AS avg_price
-- Fields are only listed once; maintaining the code becomes easier
GROUP BY ALL;
-- 在 ANSI SQL 中查询除 'email' 字段外的所有字段
SELECT country, city, region, postal_code, address, phone_number
/*, email*/
FROM customers;
-- 在 DuckDB 中查询除 'email' 字段外的所有字段
SELECT * EXCLUDE (email) FROM customers;
-- 考虑将“接近”的时间戳连接在一起。
-- 在 ANSI SQL 中,通常需要将它们分成桶
-- 在 DuckDB 中,可以使用 ASOF JOIN 来实现相同的结果,更简单、更高效。
SELECT events.id, events.ts, events.val, metadata.details
FROM events
ASOF JOIN metadata USING(id, ts);
5 与Pandas Dataframes集成
DuckDB 的一个明显优势(尤其在 Python 生态系统中)就是与 Pandas Dataframes 的无缝集成。这个特性简化了合并不同来源数据集的过程,使数据分析和转换任务变得更加简单。
例如,在 Jupyter Notebook 中,可以执行以下操作(基于电影推荐系统数据集https://www.kaggle.com/datasets/bandikarthik/movie-recommendation-system):
# 安装依赖
%pip install --quiet duckdb
%pip install --quiet jupysql
%pip install --quiet duckdb-engine
%pip install --quiet pandas
%pip install --quiet matplotlib
%pip install --quiet psycopg2-binary
%pip install --quiet dash
%pip install --quiet plotly
import duckdb
import pandas as pd
# 加载并配置 jupysql
%load_ext sql
%config SqlMagic.autopandas = True
%config SqlMagic.feedback = False
%config SqlMagic.displaycon = False
%config SqlMagic.named_parameters=True
# 连接到本地 DuckDB 实例
%sql duckdb:///
# 启用 DuckDB 查询远程文件(例如 S3)
%%sql
INSTALL httpfs;
LOAD httpfs;
# 配置 S3 访问密钥
SET s3_region = '...';
SET s3_access_key_id = '...';
SET s3_secret_access_key = '...';
# 连接到远程 Postgres 数据库
ATTACH 'dbname=DATABASE user=USER host=HOST password=PASSWORD connect_timeout=10' AS postgres (TYPE postgres, READ_ONLY);
# 执行查询并将结果存储在 dataframe 中
%%sql
df << SELECT
t1.movieId,
t1.title,
t1.genres,
t2.userId,
t2.rating,
t3.tag
# 查询 Postgres 中的表
FROM postgres.public.movies AS t1
# 与 DuckDB 中的表连接
INNER JOIN ratings AS t2 USING (movieId)
# 与 S3 中的 JSON 数据集连接
INNER JOIN 's3://S3-BUCKET/tags.json' AS t3 USING (userId, movieId)
# 最后,从另一个查询中引用 dataframe
%%sql
by_genres << SELECT genres, COUNT(*) AS cnt
FROM df
GROUP BY ALL
ORDER BY 2 DESC
LIMIT 5;
# 或者绘制转换后的数据集
import plotly.express as px
fig = px.pie(by_genres,
values='cnt',
names='genres',
title='Top 5 movie genres')
fig.show()
6 结语
本文关于 DuckDB 的概述强调了它作为大数据领域多功能、高效和用户友好型工具的潜力。作为一个相对较新的工具,DuckDB 具有独特的优势,可以弥合差距,为数据工程师和软件开发人员提供与不断变化的需求相符的解决方案。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












