

关于数据分析与可视化.
selenium的简介与安装
selenium是最广泛使用的开源Web UI自动化测试套件之一,它所支持的语言包括C++、Java、Perl、PHP、Python和Ruby,在数据抓取方面也是一把利器,能够解决大部分网页的反爬措施,当然它也并非是万能的,一个比较明显的一点就在于是它速度比较慢,如果每天数据采集的量并不是很高,倒是可以使用这个框架。
那么说到安装,可以直接使用pip在安装
pip install selenium
与此同时呢,我们还需要安装一个浏览器驱动,不同的浏览器需要安装不同的驱动,这边小编主要推荐的以下这两个
·Firefox浏览器驱动: geckodriver
· Chrome浏览器驱动: chromedriver
小编平常使用的是selenium+chromedriver比较多,所以这里就以Chrome浏览器为示例,由于要涉及到chromedriver的版本需要和浏览器的版本一致,因此我们先来确认一下浏览器的版本是多少?看下图:
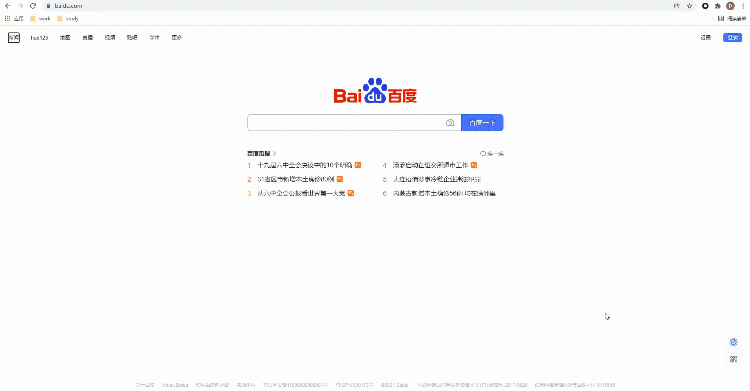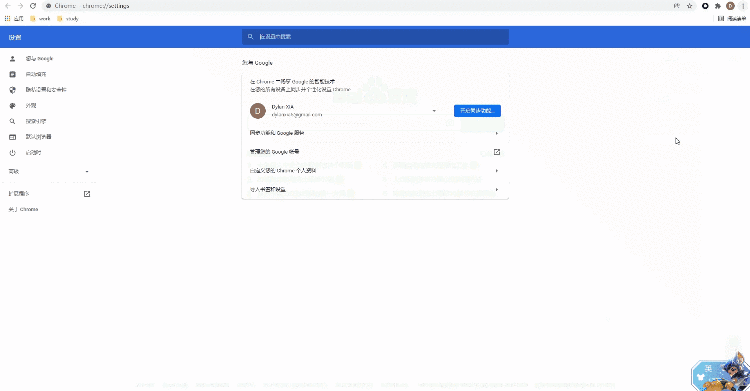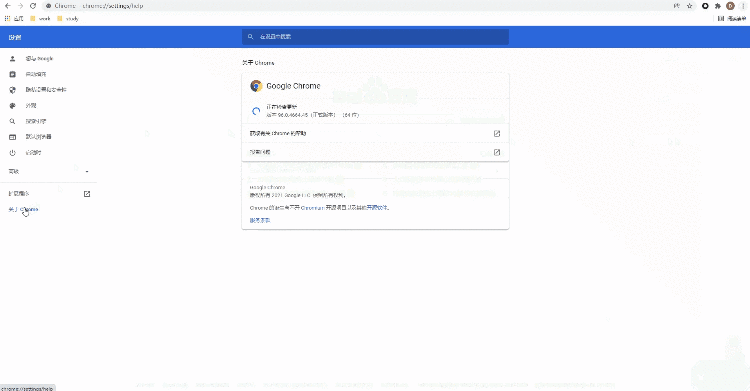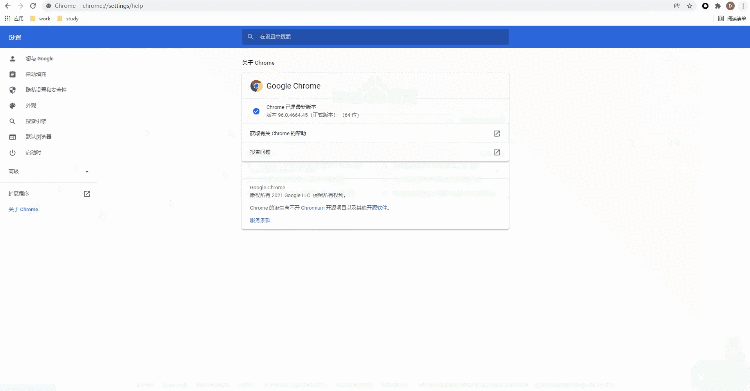
我们在“关于Chrome”当中找到浏览器的版本,然后下载对应版本的chromedriver,当然也要对应自己电脑的操作系统。

页面元素的定位
在谈到页面元素的定位时,小编默认读者朋友具备了最最基本的前端知识,例如HTML,CSS等。
ID标签的定位
在HTML当中,ID属性是唯一标识一个元素的属性,因此在selenium当中,通过ID来进行元素的定位也作为首选,我们以百度首页为例,搜索框的HTML代码如下,其ID为“kw”,而“百度一下”这个按钮的ID为“su”,我们用Python脚本通过ID的标签来进行元素的定位。
driver.find_element_by_id("kw")
driver.find_element_by_id("su")
NAME标签的定位
在HTML当中,Name属性和ID属性的功能基本相同,只是Name属性并不是唯一的,如果遇到没有ID标签的时候,我们可以考虑通过Name标签来进行定位,代码如下:
driver.find_element_by_name("wd")
Xpath定位
使用Xpath方式来定位几乎涵盖了页面上的任意元素,那什么是Xpath呢?Xpath是一种在XML和HTML文档中查找信息的语言,当然通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。
绝对路径是以单号/来表示,相对路径是以//来表示,而涉及到Xpath路径的编写,小编这里偷个懒,直接选择复制/粘贴的方式,例如针对下面的HTML代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Test</title>
</head>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
</html>
我们可以这么来做,打开浏览器的开发者工具,鼠标移到我们选中的元素,然后右击检查,具体看下图:
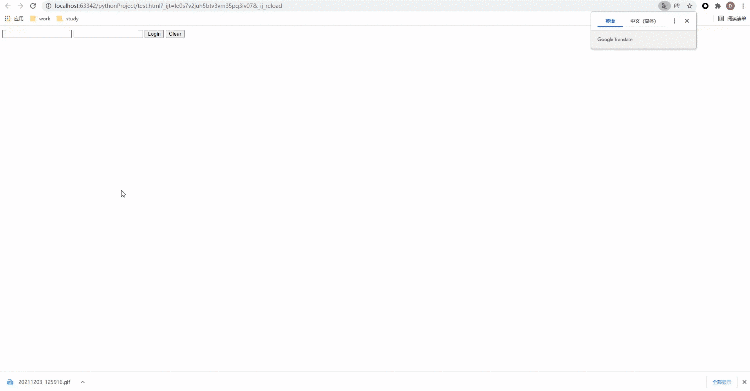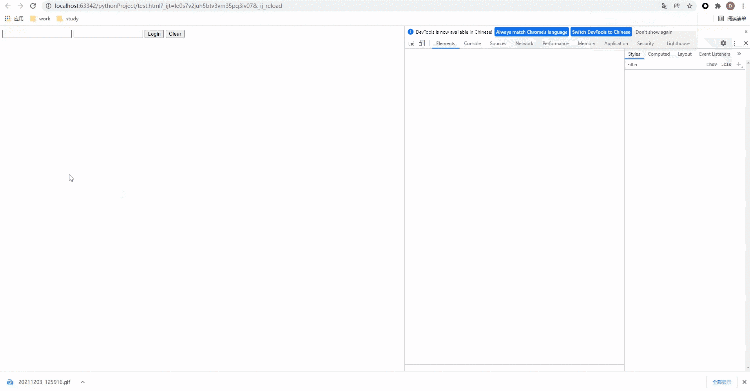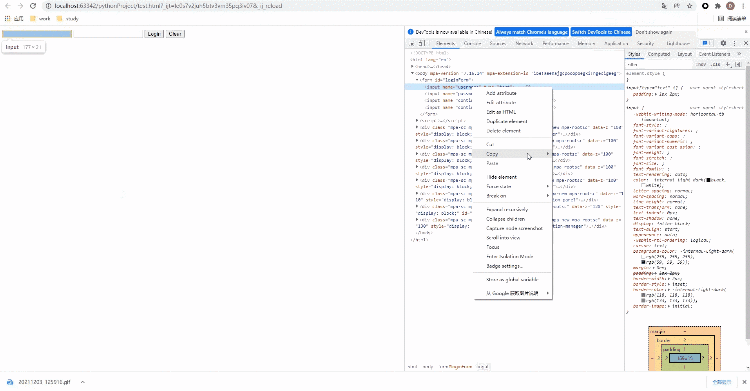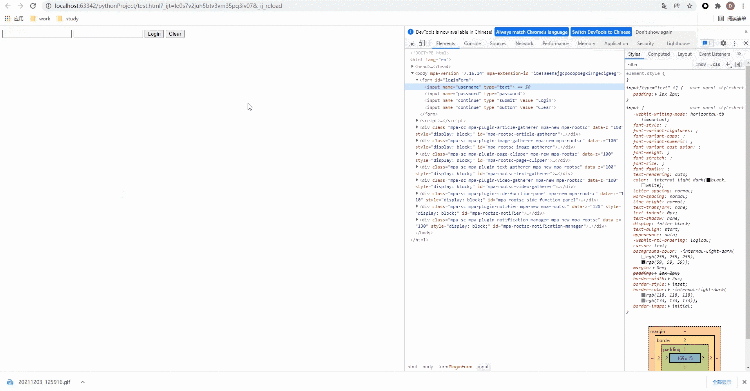
我们还是以百度首页为例,看一下如何通过Xpath来进行页面元素的定位,代码如下:
driver.find_element_by_xpath('//*[@id="kw"]')
className标签定位
我们也可以基于class属性来定位元素,尤其是当我们看到有多个并列的元素如list表单,class用的都是共用同一个,如:
driver.find_element_by_class_name("classname")
这个时候,我们就可以通过class属性来定位元素,该方法返回的是一个list列表,而当我们想要定位列表当中的第n个元素时,则可以这样来安排
driver.find_elements_by_class_name("classname")[n]
需要注意的是,这里使用的是find_elements_by_class_name()方法而不是find_element_by_class_name()方法,这里我们还是通过百度首页的例子,通过className标签来定位搜索框这个元素。
driver.find_element_by_class_name('s_ipt')
CssSelector()方法定位
其实在Selenium官网当中是更加推荐CssSelector()方法来进行页面元素的定位的,原因在于相比较于Xpath定位速度更快,Css定位分为四类:ID值、Class属性、TagName值等等,我们依次来看。
·ID方式来定位
大概有两种方式,一种是在ID值前面添加TagName的值,另外一种则是不加,代码如下:
driver.find_element_by_css_selector("#id_value") # 不添加前面的`TagName`值
driver.find_element_by_css_selector("tag_name.class_value") # 不添加前面的`TagName`值
当然有时候这个TagName的值非常的冗长,中间可能还有空格,那么这当中的空格就需要用点“.”来替换。
driver.find_element_by_css_selector("tag_name.class_value1.calss_value2.class_value3") # 不添加前面的`TagName`值
我们仍然以百度首页的搜索框为例,它的HTML代码如下:

要是用CssSelector的.class()方式来实现元素的定位的话,Python代码该这样来实现,和上面Xpath()的方法一样,可以稍微偷点懒,通过复制/粘贴的方式从开发者工具当中来获取元素的位置。

代码如下:
driver.find_element_by_css_selector('#kw')
linkText()方式来定位
这个方法直接通过链接上面的文字来定位元素,案例如下:
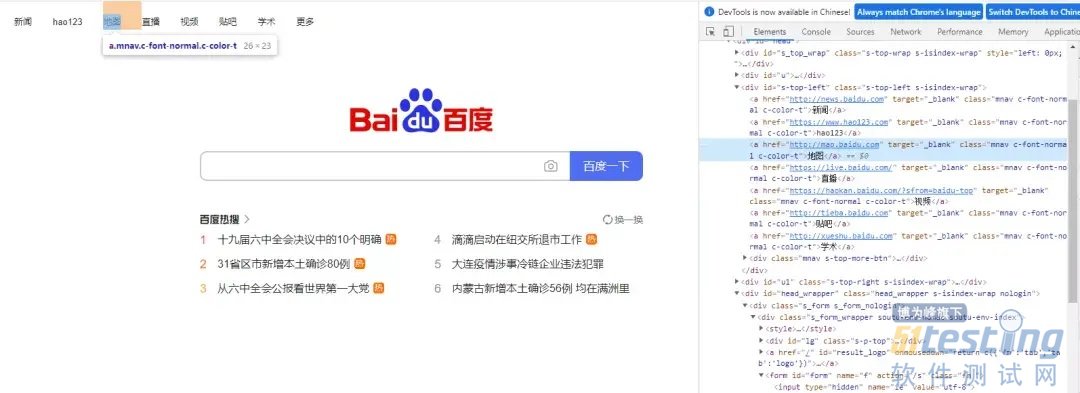
通过linkText()方法来定位“地图”这个元素,代码如下:
driver.find_element_by_link_text("地图").click()
浏览器的控制
修改浏览器窗口的大小
我们可以通过使用set_window_size()这个方法来修改浏览器窗口的大小,代码如下:
# 修改浏览器的大小
driver.set_window_size(500, 900)
同时还有maxmize_window()方法是用来实现浏览器全屏显示,代码如下:
# 全屏显示
driver.maximize_window()
浏览器的前进与后退
前进与后退用到的方法分别是forward()和back(),代码如下:
# 前进与后退
driver.forward()
driver.back()
浏览器的刷新
刷新用到的方法是refresh(),代码如下:
# 刷新页面
driver.refresh()
除了上面这些,webdriver的常见操作还有:
·关闭浏览器:get()
· 清除文本:clear()
· 单击元素:click()
· 提交表单:submit()
· 模拟输入内容:send_keys()
我们可以尝试着用上面提到的一些方法来写段程序:
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get("https://www.baidu.com")
sleep(3)
driver.maximize_window()
sleep(1)
driver.find_element_by_xpath('//*[@id="s-top-loginbtn"]').click()
sleep(3)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__userName"]').send_keys('12121212')
sleep(1)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__password"]').send_keys('testtest')
sleep(2)
driver.refresh()
sleep(3)
driver.quit()
output

本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












