

1.5 哈夫曼树及哈夫曼编码
1.5.1 基本概念
结点间路径:从一个结点到另一个结点所经历的结点和分支序列。
结点的路径长度:从根节点到该结点的路径上分支的数目。
结点的权:在实际应用中,人们往往会给树中的每一个结点赋予一个具有某种实际意义的数值,这个数值被称为该结点的权值。
结点的带权路径长度:该结点的路径长度与该结点的权值的乘积。
树的带权路径长度:树中所有叶结点的带权路径长度之和。
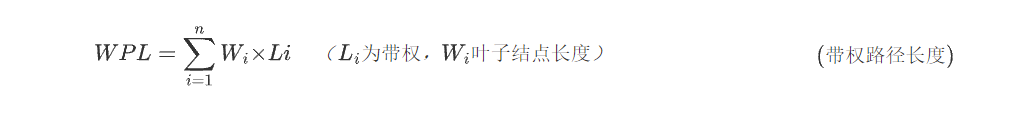
1.5.2 最优二叉树(哈夫曼树)【重点】
给定n个权值并作为n个叶结点,按一定规则构造一颗二叉树,使其带权路径长度达到最小值,则这棵二叉树被称为最优二叉树,也称为哈夫曼树。
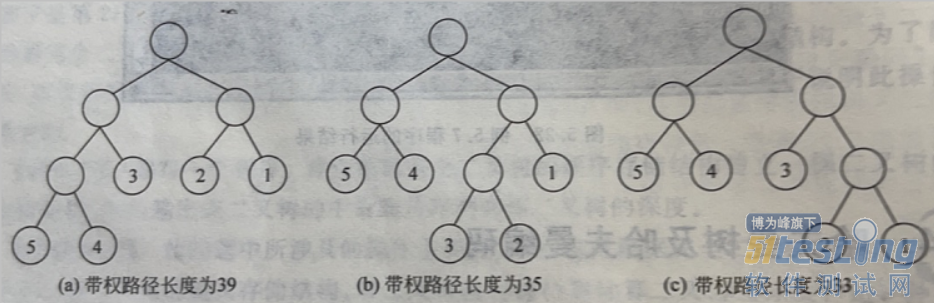
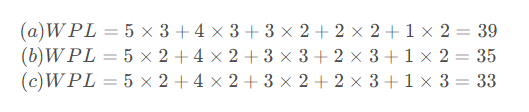
同一组数据的最优二叉树不唯一,因为没有限定左右子树,并且有权值重复时,可能树的高度都不唯一,唯一的只是带权路径长度之和最小。 构建哈夫曼树的时候即可以推导出。
1.5.3 构建哈夫曼树【重点】

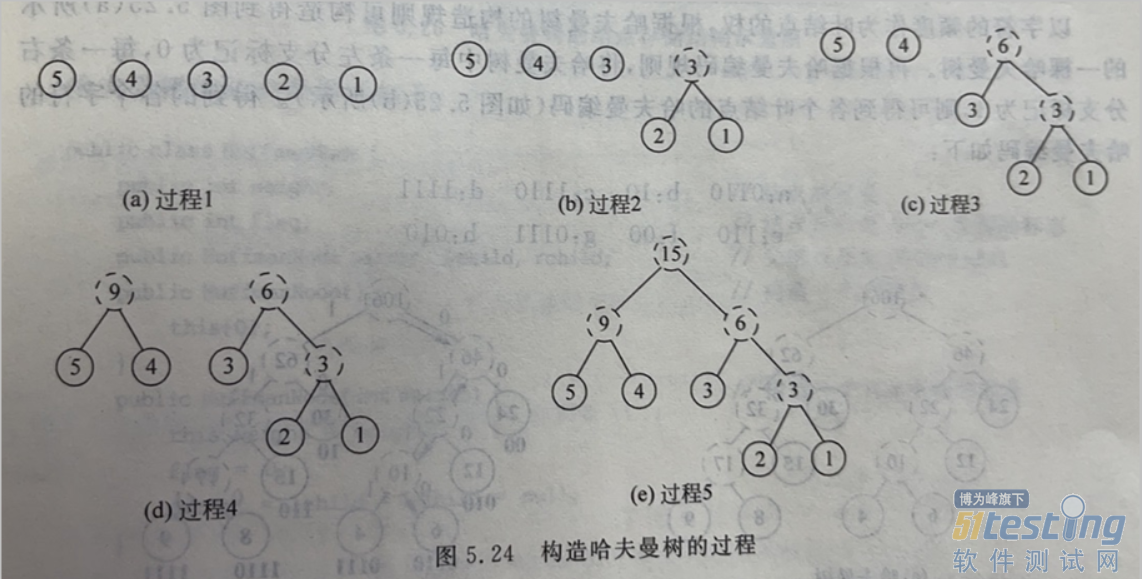
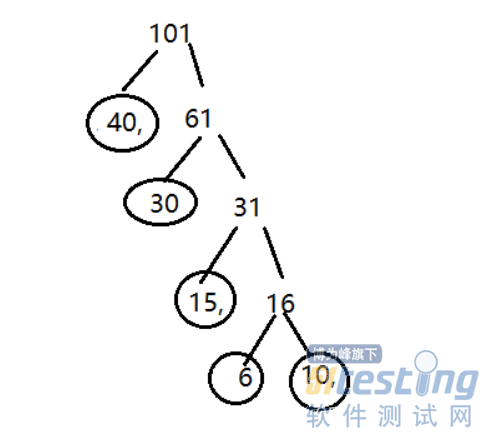
练习:
有5个带权结点 {A,B,C,D,E},其权值分别为W={10,30,40,15,6},权值作为结点数据,绘制一颗哈夫曼。
1.5.4 哈夫曼编码【重点】
编码诉求:对字符集进行二进制编码,使得信息的传输量最小。如果能对每一个字符用不同的长度的二进制编码,并且尽可能减少出现次数最多的字符的编码位数,则信息传送的总长度便可以达到最小。
哈夫曼编码:用电文中各个字符使用的频度作为叶结点的权,构造一颗具有最小带权路径长度的哈夫曼树,若对树中的每个左分支赋予标记0,右分支赋予标记1,则从根节点到每个叶结点的路径上的标记连接起来就构成一个二进制串,该二进制串被称为哈夫曼编码。
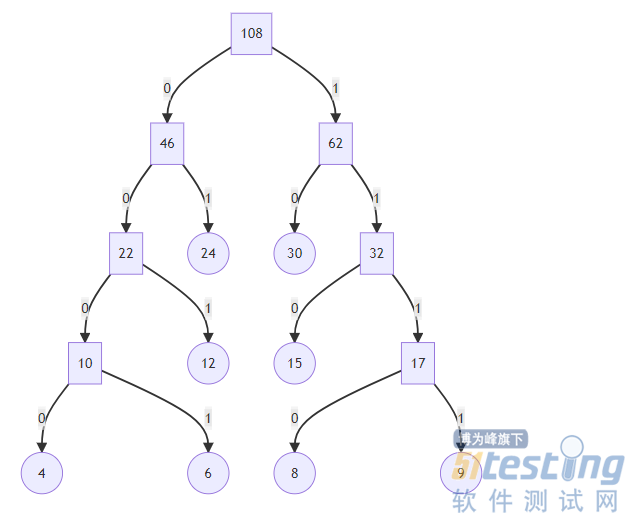
练习:p176
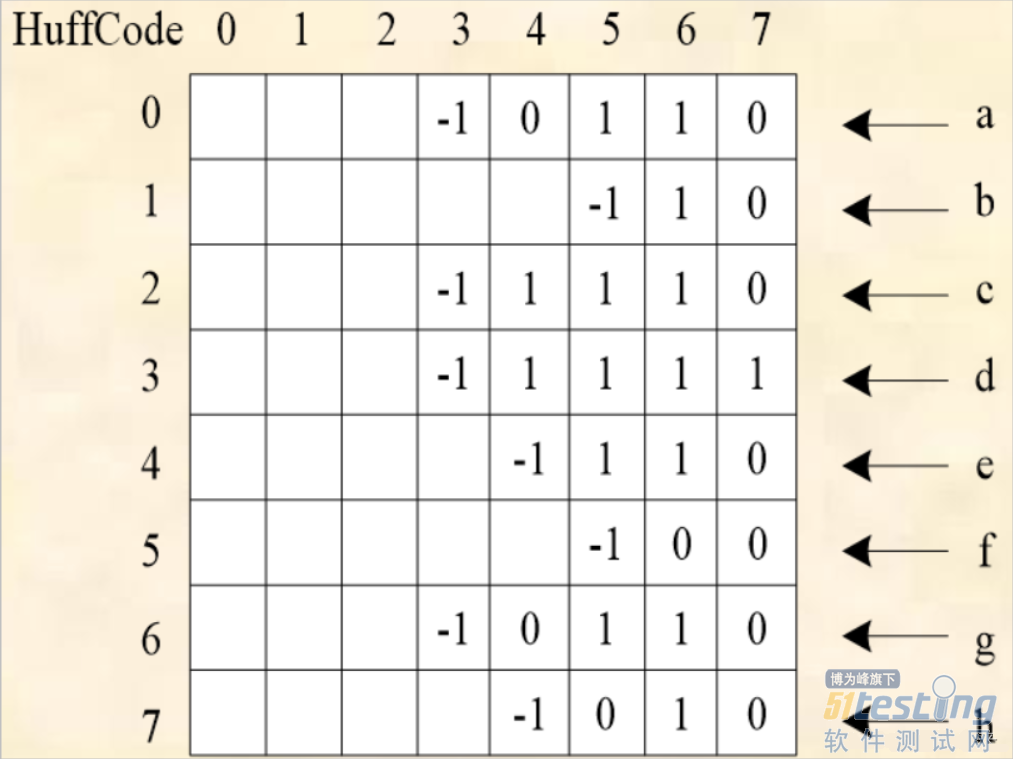
已知在一个信息通信联络中使用了8个字符:a、b、c、d、e、f、g和h,每个字符的使用频度分别为:6、30、8、9、15、24、4、12,试设计各个字符的哈夫曼编码。
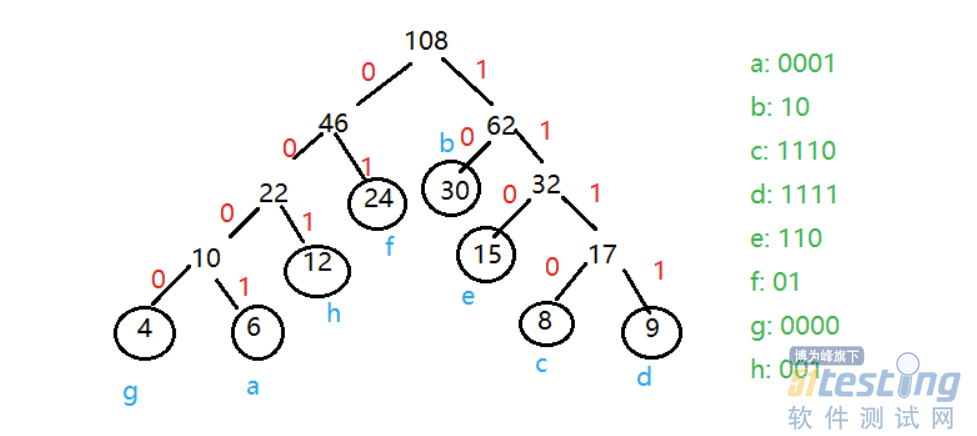
· 哈夫曼树进行译码
哈夫曼编码是一种前缀码,任何一个字符的编码都不是同一个字符集中另一个字符的编码的前缀。
译码过程时编码过程的逆过程。从哈夫曼树的根开始,从左到右把二进制编码的每一位进行判别,若遇到0,则选择左分支走向下一个结点;若遇到1,则选择右分支走向下一个结点,直至到达一个树叶结点,便求得响应字符。
· 练习
有5个带权结点 {A,B,C,D,E},其权值分别为W={10,30,40,15,6},权值作为结点数据,绘制一颗哈夫曼,并编写哈夫曼编码。
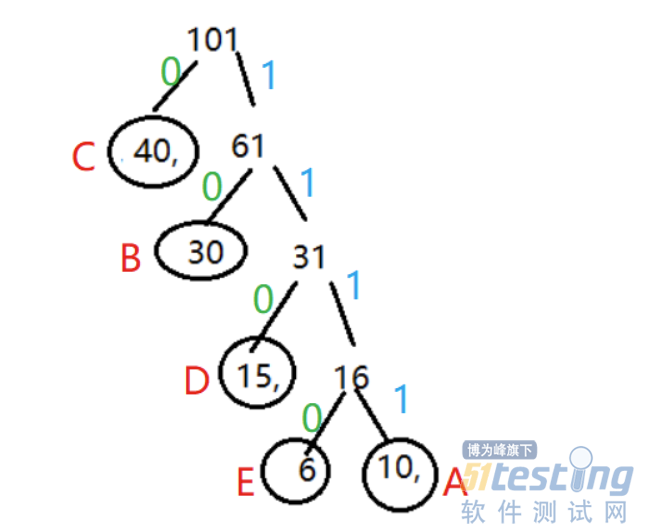
A:1111
B:10
C:0
D:110
E:1110
编码:编码字符串 AABBEDCC–>111111111010111011000
1.5.5 哈夫曼编码类
· n个权值,组成哈夫曼树节点个数:2n-1
· 哈夫曼结点类
public class HuffmanNode {
public int weight;// 权值
public int flag; // 节点是否加入哈夫曼树的标志
public HuffmanNode parent,lchild,rchild; // 父节点及左右孩子节点
// 构造一个空节点
public HuffmanNode(){
this(0);
}
// 构造一个具有权值的节点
public HuffmanNode(int weight){
this.weight = weight;
flag=0;
parent=lchild=rchild=null;
}
}
· 哈夫曼编码类
public class HuffmanTree {
// 求哈夫曼编码的算法,w存放n个字符的权值(均>0)
public int[][] huffmanCoding(int[] W){
int n = W.length; // 字符个数
int m = 2*n -1; //哈夫曼树的节点数
// 构造n个具有权值的节点
HuffmanNode[] HN = new HuffmanNode[m];
int i = 0;
for (; i<n ; i++) {
HN[i] = new HuffmanNode(W[i]);
}
// 创建哈夫曼树
for (i = n; i<m ; i++) {
// 在HN[0...1]选择不在哈夫曼树中,且权值weight最小的两个节点min1和min2
HuffmanNode min1 = selectMin(HN,i-1);
min1.flag = 1;
HuffmanNode min2 = selectMin(HN,i-1);
min2.flag = 1;
// 构造 min1和min2的父节点,并修改父节点的权值
HN[i] = new HuffmanNode();
min1.parent=HN[i];
min2.parent=HN[i];
HN[i].lchild = min1;
HN[i].rchild = min2;
HN[i].weight = min1.weight+min2.weight;
}
// 从叶子到根 逆向求每个字符的哈夫曼编码
int[][] HuffCode = new int[n][n]; // 分配n个字符编码存储空间
for (int j =0;j<n;j++){
// 编码的开始位置,初始化为数组的结尾
int start = n-1;
// 从叶子节点到根,逆向求编码
for(HuffmanNode c = HN[j],p=c.parent;p!=null;c=p,p=p.parent){
if(p.lchild.equals(c)){
HuffCode[j][start--]=0;
}else{
HuffCode[j][start--]=1;
}
}
// 编码的开始标志为-1,编码是-1之后的01序列
HuffCode[j][start] = -1;
}
return HuffCode;
}
// 在HN[0...1]选择不在哈夫曼树中,且权值weight最小的两个节点min1和min2
private HuffmanNode selectMin(HuffmanNode[] HN, int end) {
// 求 不在哈夫曼树中, weight最小值的那个节点
HuffmanNode min = HN[end];
for (int i = 0; i < end; i++) {
HuffmanNode h = HN[i];
// 不在哈夫曼树中, weight最小值
if(h.flag == 0 && h.weight<min.weight){
min = h;
}
}
return min;
}
}
· 哈夫曼编码会用类似如下格式进行存储
测试类:
public class Demo02 {
public static void main(String[] args) {
// 一组权值
int[] W = {6,30,8,9,15,24,4,12};
// 创建哈夫曼树
HuffmanTree tree = new HuffmanTree();
// 求哈夫曼编码
int[][] HN = tree.huffmanCoding(W);
//打印编码
System.out.println("哈夫曼编码是: ");
for (int i = 0; i < HN.length; i++) {
System.out.print(W[i]+" ");
for (int j = 0; j < HN[i].length; j++) {
if(HN[i][j] == -1){
for (int k = j+1; k <HN[i].length ; k++) {
System.out.print(HN[i][k]);
}
break;
}
}
System.out.println();
}
}
}
1.6 树与森林
1.6.1 转换概述
树与二叉树之间、森林与二叉树之间可以相互转换,而且这种转换是一一对应的。
1.6.2 树转换成二叉树
树转换成二叉树可归纳3步骤:加线、删线、旋转。
加线:将树中所有相邻的兄弟之间加一条连线。
删线:对树中的每一个结点,只保留它与第1个孩子结点之间的连线,删去它与其他孩子结点之间的连线。
旋转:以树的根结点为轴心,将树平面顺时针旋转一定角度并做适当的调整,使得转化后所得二叉树看起来比较规整。
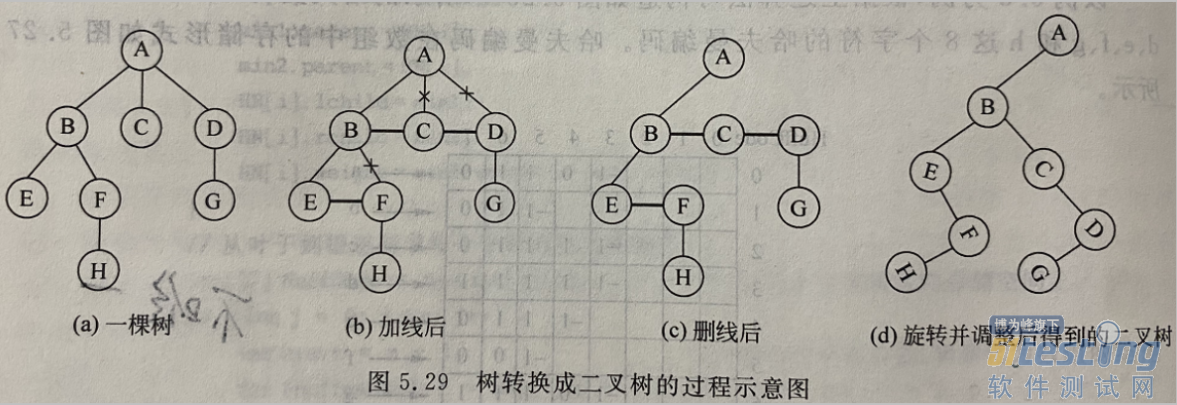
由树转换成的二叉树永远是一棵根结点的右子树为空的二叉树。
1.6.3 二叉树转换成树
二叉树转换成树是树转换二叉树的逆过程。
树转换成二叉树可归纳3步骤:加线、删线、旋转
加线:若某结点是双亲结点的左孩子,则将该结点沿着右分支向下的所有结点与该结点的双亲结点用线连接。
删除:将树中所有双亲结点与右孩子结点的连线删除。
旋转:对经过(1)、(2)粮补后所得的树以根结点为轴心,按逆时针方向旋转一定的角度,并做适当调整,使得转化后所得的树看起来比较规整。
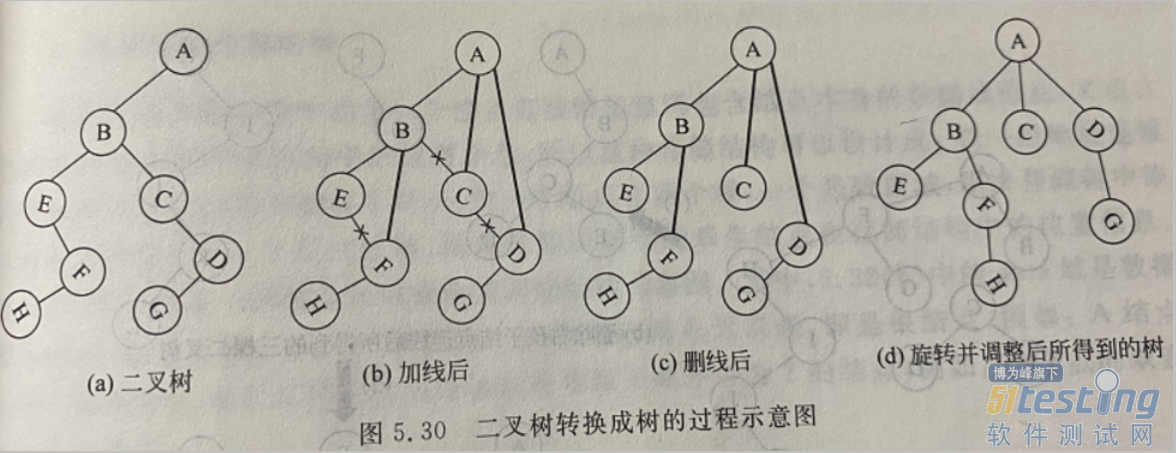
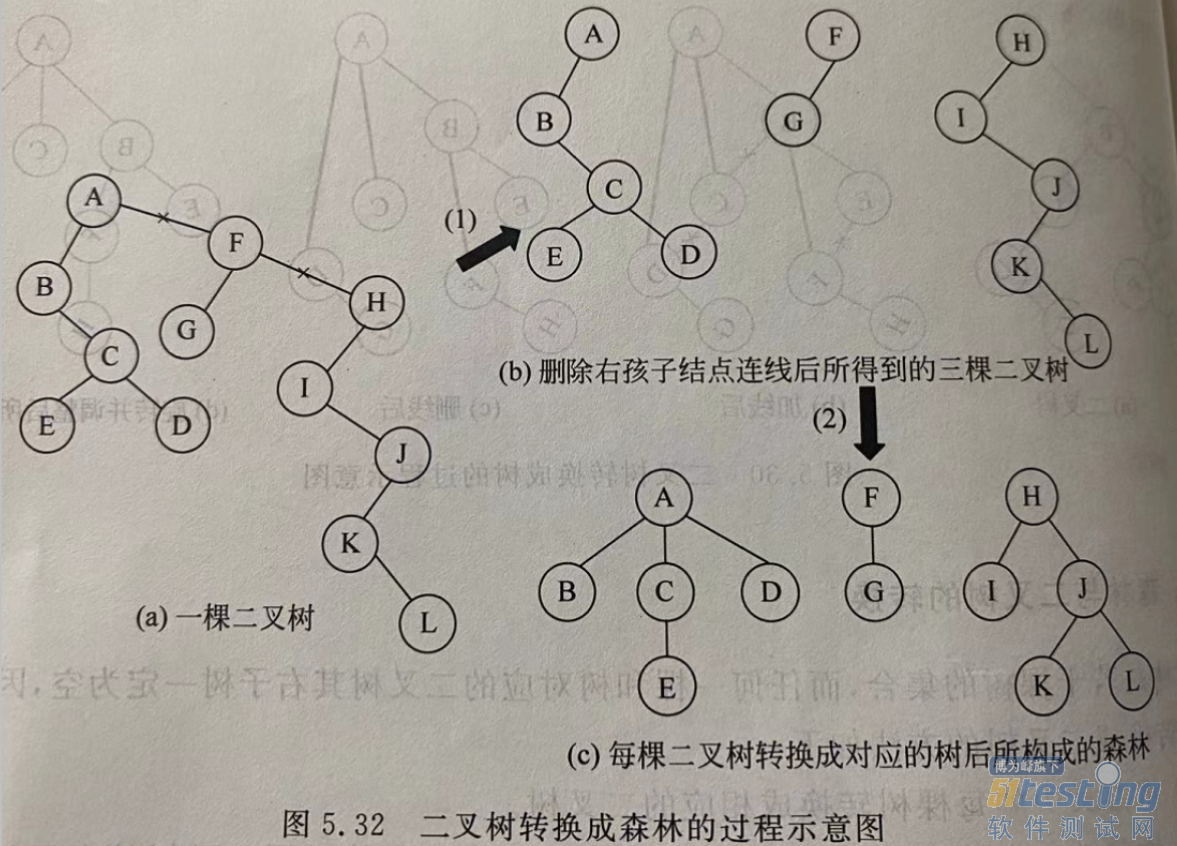
1.6.4 森林与二叉树互转
森林是由若干树组成,任何一棵树和树对应的二叉树其右子树一定是空的。
根据这个规律可以得到森林转化成二叉树的方法:
将森林中每棵树转化成二叉树。
按照森林的先后顺序,将一颗二叉树视为前一棵二叉树的右子树依次链接起来,从而构成一颗二叉树。
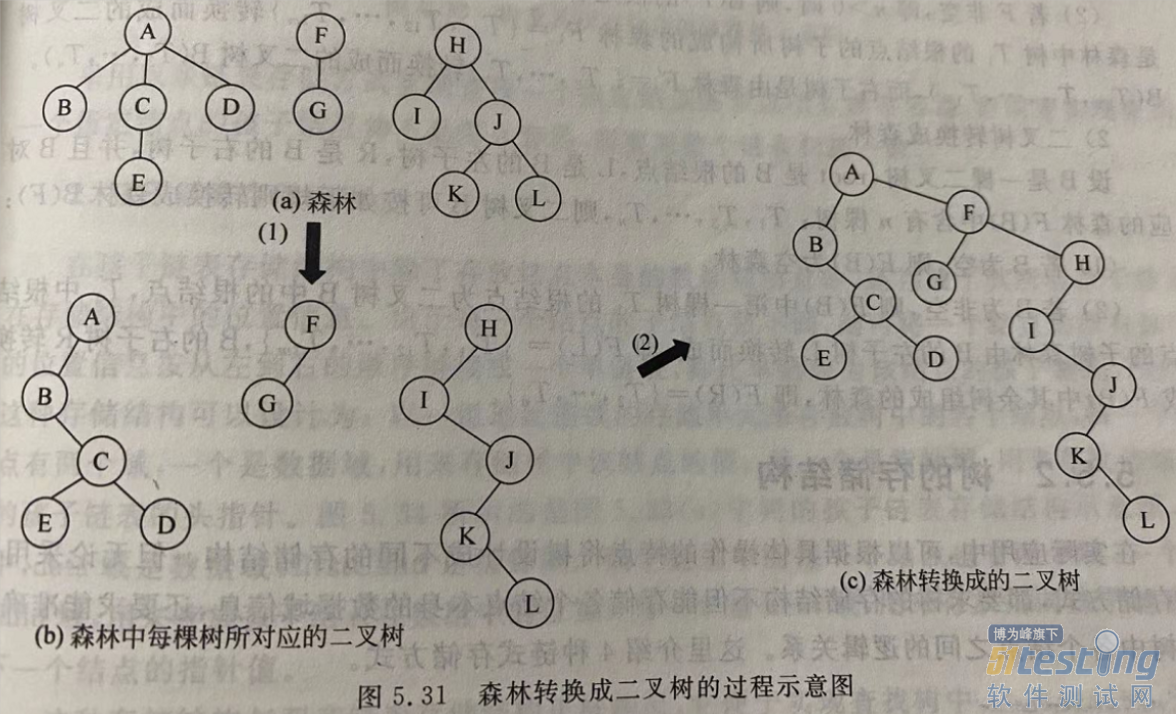
将二叉树转化成森林正好是这个过程相反。
1.6.5 树的存储结构
树的4种链式存放方式:
1. 双亲链表存储结构
2. 孩子链表存储结构
3. 双亲孩子链表存储结构
4. 孩子兄弟链表存储结构(重点掌握)
1)双亲链表存储结构
以一组地址连续的存储单元存放树中的各个结点,每个结点有两个域:
数据域:用于存放树中该结点的值。
指针域:用于存放该结点的双亲结点在存储结构中的位置。
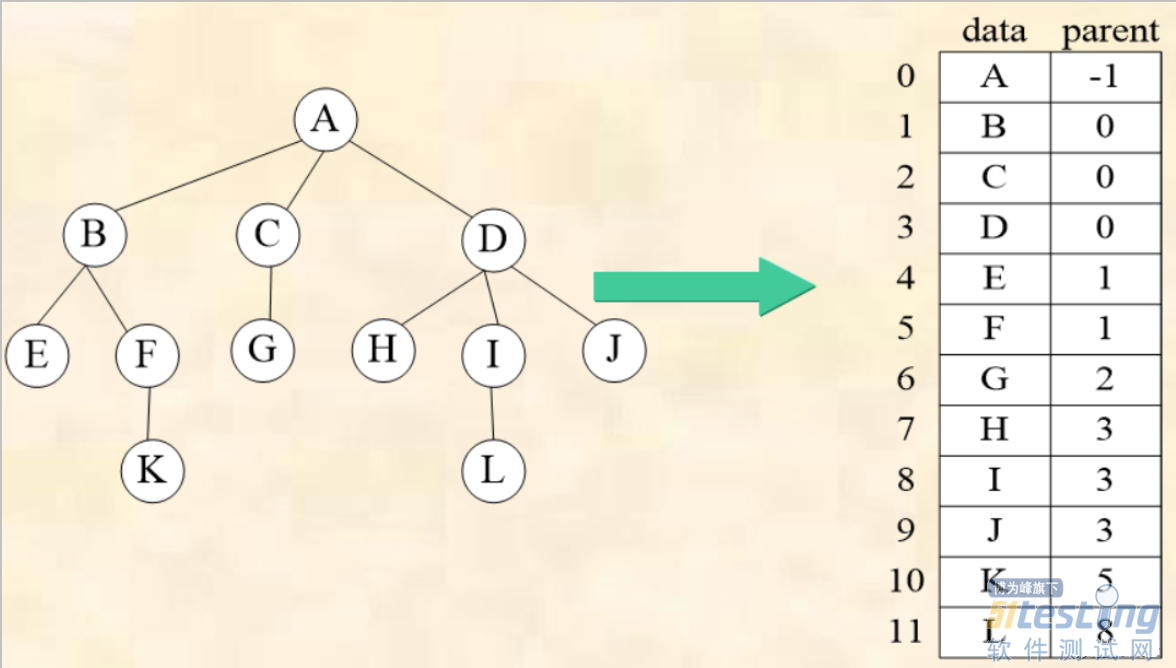
优点:查找一个指定结点的双亲结点非常容易。
缺点:查找指定结点的孩子结点,需要扫描整个链表。
2)孩子链表存储结构
以一组地址连续的存储单元来存放树中的各个结点,每一个结点有两个域
数据域:存放该结点的值
指针域:用于存放该结点的孩子链表的头指针。
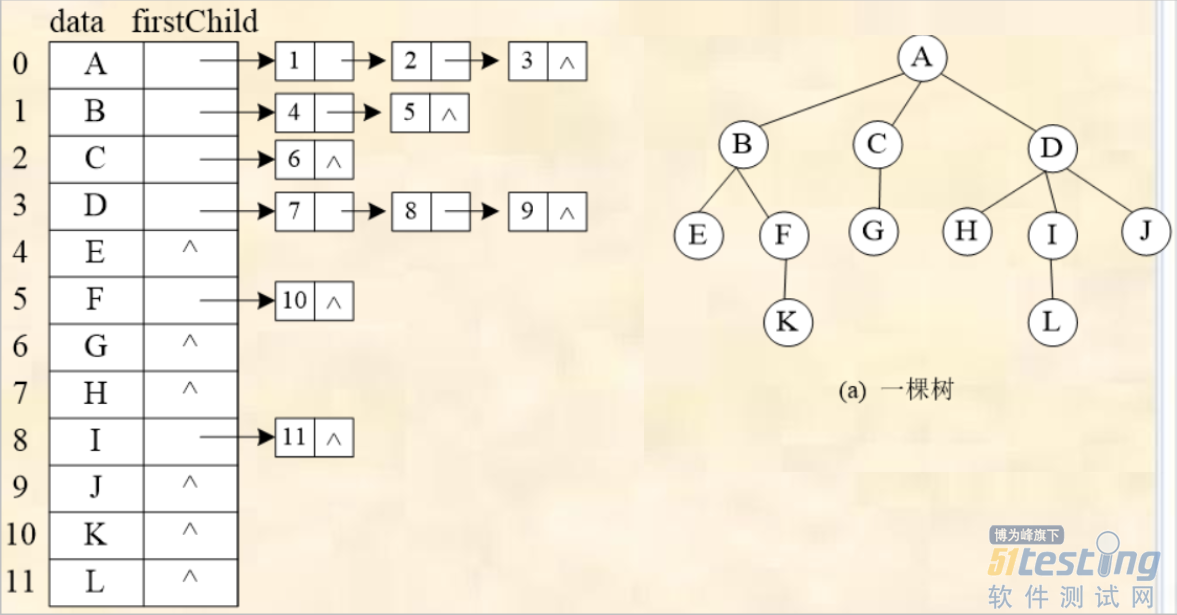
优点:便于实现查找树中指定结点的孩子结点。
缺点:不便于查找指定结点的双亲结点。
3)双亲孩子链表存储结构
与孩子链表存储结构类似,以一组地址连续的存储单元来存放树中的各个结点,每一个结点有三个域
数据域:存放该结点的值
父指针域:用于存放双亲结点在数组中的位置
子指针域:用于存放该结点的孩子链表的头指针。
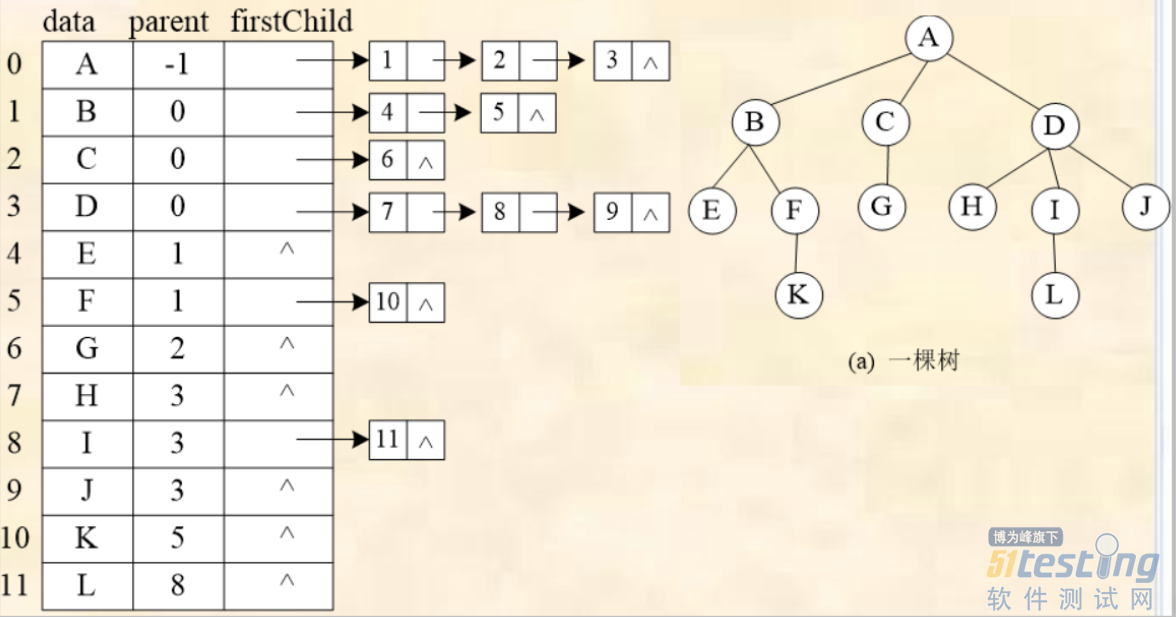
4)孩子兄弟链表存储结构(重点掌握)
孩子兄弟链表存放,又称为“左子/右兄”二叉链式存储结构。
左指针:指向该结点的第一个孩子
右指针:指向该结点的右邻兄弟
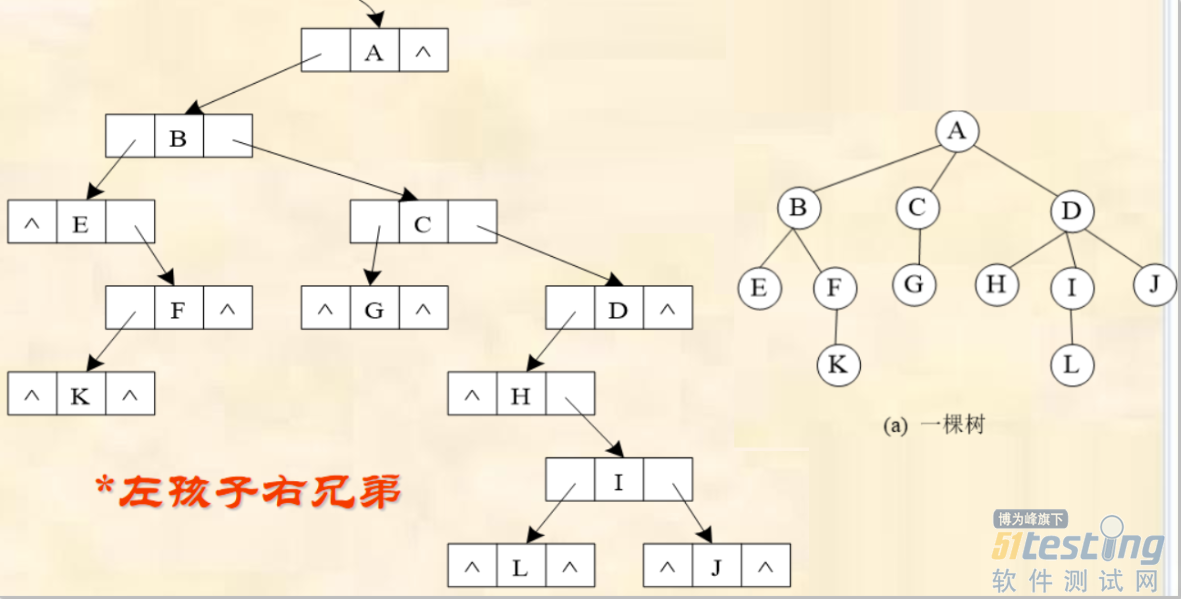
结点类:
public class CSTreeNode {
public Object data; //结点的数据域
publicCSTreeNode firstChild, nextsibling; //左孩子、右兄弟
}
1.6.6 树的遍历
树的遍历主要有:先根遍历、后根遍历、层次遍历。
1)先根遍历
若树为非空,则
1. 访问根节点。
2. 从左到右依次先根遍历根节点的每一颗子树。
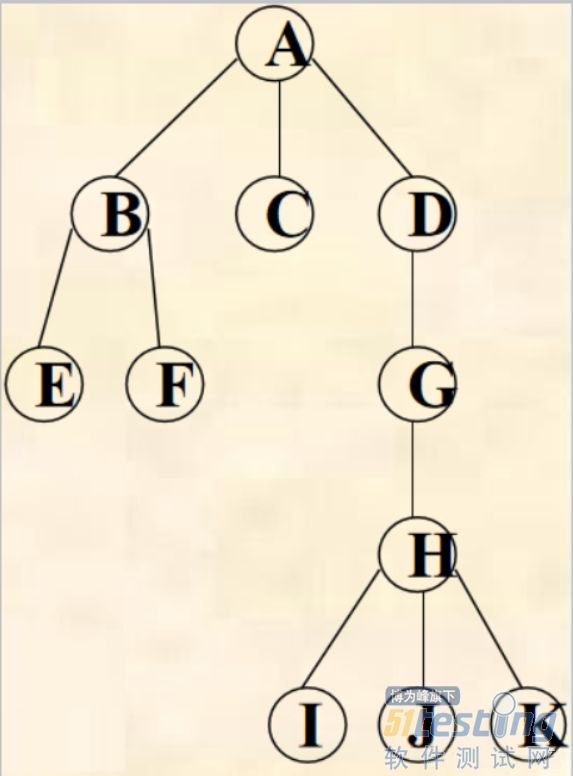
先根遍历序列:
ABEFCDGHIJK
public void preRootTraverse(CSTreeNode T) {
if(T != null) {
System.out.print(T.data);
preRootTraverse(T.firstChild); //先根遍历树中根节点的第一个子树
preRootTraverse(T.nextsibling); //先根遍历树中根节点的其他子树
}
}
2)后根遍历
若树为非空,则
1. 从左到右依次后根遍历根节点的每一棵子树
2. 访问根节点
后根遍历序列:
EFBCIJKHGDA

使用孩子兄弟链表存储的树,与遍历二叉树的中序序列相同。
public void postRootTraverse(CSTreeNode t) {
if(T != null) {
postRootTraverse(T.firstChild); //后根遍历树中根节点的第一个子树
System.out.print(T.data); //访问数的根节点
postRootTraverse(T.nextsibling); //后根遍历树中根节点的其他子树
}
}
3)层次遍历
若树为非空,则从根节点开始,从上到下依次访问每一层的各个结点,在同一层中的结点,则按从左到右的顺序依次进行访问。
ABCDEFGHIJK
public void levelTraverse(CSTreeNode T) {
if(T != null) {
LinkQueue L = new LinkQueue(); //构建队列
L.offer(T); //根节点入队列
while(!L.isEmpty()) { //队列不为空,处理根结点和左孩子
for(T = L.poll() ; T != null ; T = T.nextsibling) {//依次处理兄弟(右子树)
System.out.print(T.data + " ");
if(T.firstChild != null) { //第一个孩子结点非空入队列
L.offer(T.firstchild);
}
}
}
}
}
1.6.7 森林的遍历
· 森林由3部分组成:
1. 森林中第一棵树的根节点
2. 森林中第一棵树的子树森林
3. 森林中其他树构成的森林。
· 森林的3中遍历:
1. 先根遍历
2. 后根遍历
3. 层次遍历
1)先根遍历
若森林不空,则可依下列次序进行遍历
1. 访问森林中第一棵树的根节点
2. 先序遍历第一课树中的子树森林
3. 先序遍历除去第一棵树之后剩余的树构成的森林。
也就是说:依次从左到右对森林中的每一颗树进行先根遍历。
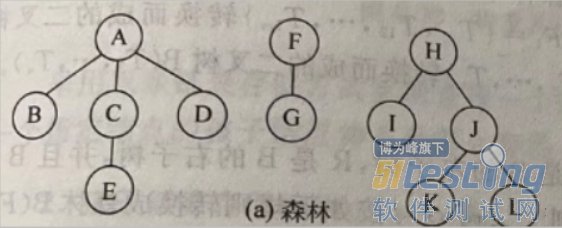
先跟遍历顺序是:
ABCEDFGHIJKL
2)后根遍历
若森林不空,则可依下列次序进行遍历
1. 后根遍历第一棵树中的子树森林
2. 访问森林中第一棵树的根节点
3. 后根遍历除去第一棵树之后剩余的树构成的森林。
也就是说:依次从左至右对森林中的每一棵树进行后根遍历。
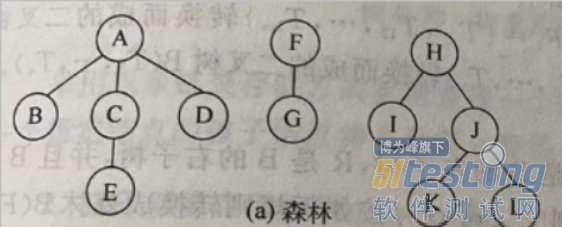
后根遍历序列是:
BECDAGFIKLJH
3)层次遍历
若森林为非空,则按从左到右的顺序对森林中每一颗树进行层次遍历。
也就是说:依次从左至右对森林中的每一棵树进行层次遍历。

层次遍历序列:
ABCDEFGHIJKL
后记
好啦,以上就是本期全部内容,能看到这里的人呀,都是能人。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理











