

实时数据对于企业快速做出决策非常重要。企业高管可以直观地看到这些数据帮助他们更快地做出决策,可以使用各种数据应用程序或仪表板创建数据的可视化表示。Dash是一个开源Python库,它提供了广泛的内置组件,用于创建交互式图表、图形、表格和其他用户界面(UI)元素。RisingWave是一个基于SQL的流数据库,用于实时数据处理。本文将对如何使用Python、Dash开源库和RisingWave对实时数据实现可视化进行了介绍。
如何实时可视化数据
实时数据是指立即生成和处理的数据,因为它是从不同的数据源收集的。源可以是典型的数据库(例如Postgres或MySQL),也可以是消息代理(例如Kafka)。实时数据的可视化包括几个步骤:首先摄取,然后处理,最后在仪表板中显示这些数据。
在订单交付数据的情况下,实时可视化这些数据可以为餐厅或配送服务的绩效提供有价值的见解。例如,可以使用实时数据来监控订单交付所需的时间,识别交付过程中的瓶颈,并跟踪随着时间变化的订单量。在处理不断变化的数据时,很难跟踪正在发生的一切并识别模式或趋势。使用Dash和RisingWave等免费工具,可以创建交互式可视化,使用户能够探索和分析这些不断变化的数据。
说到处理数据,人们可能首先想到的编程语言是Python,因为Python有一系列库。Dash是其中之一,它允许用户仅使用Python代码创建具有丰富和可定制用户界面的数据应用程序。Dash是在Flask、Plotly.js和React.js之上构建的,这些都是流行的Web开发工具,所以用户不需要知道HTML、CSS或其他JavaScript框架。
RisingWave可以使用来自各种来源的数据流,创建针对复杂查询进行优化的物化视图,并使用SQL查询实时数据。由于RisingWave与PostgreSQL是有线兼容的,可以使用Psycopg2 (Python中的PostgreSQL客户端库)驱动程序连接到RisingWave,并进行查询操作。
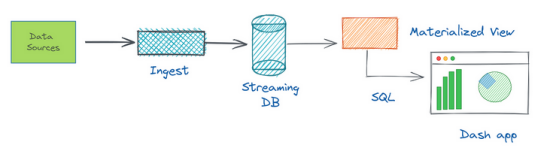
可视化订单交付数据演示
在这个演示教程中,将利用下面的GitHub存储库和RisingWave演示,假设所有必要的内容都是使用Docker Compose设置的。可以在官方网站上查看运行RisingWave的其他方法。在这里有一个名为delivery_orders的Kafka主题,其中包含在食品配送网站上放置的每个订单的事件。每个事件都包含有关订单的信息,例如订单ID、餐厅ID和交付状态。工作负载生成器(称为Datagen的Python脚本)模拟随机模拟数据的连续生成,并将其流式传输到Kafka主题中。实际上,这些模拟数据可以被来自Web应用程序或后端服务的数据所取代。
要完成这一教程,首先完成以下操作:
·确保环境中安装了Docker和Docker Compose。
· 确保环境中安装了PostgreSQL交互终端psql。详细说明请参见下载PostgreSQL。
· 为OS. pip命令下载并自动安装Python 3。
步骤1:设置RisingWave的演示集群
首先,将RisingWave示例存储库克隆到本地环境。
git clone <https://github.com/risingwavelabs/risingwave.git>
然后,进入integration_tests/delivery目录,并从docker compose文件启动演示集群。
cd risingwave/integration_tests/delivery
docker compose up -d
确保所有容器都已启动并运行。
步骤2:安装Dash和Psycopg2库
要安装Dash,也可以参考网站上的Dash安装指南。基本上,需要通过运行以下pip install命令来安装两个库(Dash本身和Pandas):
# This also brings along the Plotly graphing library.
# Plotly is known for its interactive charts
# Plotly Express requires Pandas to be installed too.
pip install dash pandas
还应该安装Psycopg2来与RisingWave流数据库交互:
pip install psycopg2-binary
步骤3:创建数据源
要使用RisingWave获取实时数据,首先需要设置一个数据源。在演示项目中,Kafka应该被定义为数据源。将创建一个名为create-a-source.py的新文件,与连接到RisingWave的Python脚本的integration_tests/delivery目录相同,并创建一个表来消费和持久化delivery_orders Kafka主题。可以简单地将以下代码复制并粘贴到新文件中。
import psycopg2
conn = psycopg2.connect(database="dev", user="root", password="", host="localhost", port="4566") # Connect to RisingWave.
conn.autocommit = True # Set queries to be automatically committed.
with conn.cursor() as cur:
cur.execute("""
CREATE TABLE delivery_orders_source (
order_id BIGINT,
restaurant_id BIGINT,
order_state VARCHAR,
order_timestamp TIMESTAMP
) WITH (
connector = 'kafka',
topic = 'delivery_orders',
properties.bootstrap.server = 'message_queue:29092',
scan.startup.mode = 'earliest'
) ROW FORMAT JSON;""") # Execute the query.
conn.close() # Close the connection.
在创建文件之后,运行python create-a-source.py,它将在RisingWave中创建源表。
步骤4:创建物化视图
接下来,创建一个新的物化视图,类似于创建表的方式。在此创建一个名为create-a-materialized-view.py的新文件,并使用Psycopg2库运行SQL查询。也可以将上面的最后两个步骤合并到一个Python脚本文件中。
import psycopg2
conn = psycopg2.connect(database="dev", user="root", password="", host="localhost", port="4566")
conn.autocommit = True
with conn.cursor() as cur:
cur.execute("""CREATE MATERIALIZED VIEW restaurant_orders_view AS
SELECT
window_start,
restaurant_id,
COUNT(*) AS total_order
FROM
HOP(delivery_orders_source, order_timestamp, INTERVAL '1' MINUTE, INTERVAL '15' MINUTE)
WHERE
order_state = 'CREATED'
GROUP BY
restaurant_id,
window_start;""")
conn.close()
在上面的示例中,SQL查询实时计算特定餐厅在过去15分钟内创建的订单总数,并将结果缓存到物化视图中。如果发生任何数据更改或新的Kafka主题,RisingWave会自动增加和更新物化视图的结果。一旦设置了数据源,物化视图,就可以开始摄取数据,并使用Dash将这些数据可视化。
步骤5:构建Dash应用程序
现在构建Dash应用程序来查询和可视化RisingWave中的物化视图内容。可以在20分钟内跟随教程Dash来了解Dash的基本构建块。这一示例的应用程序代码以表格和图形两种格式显示餐厅订单数据。请参阅dash-example.py中的以下Python代码:
import psycopg2
import pandas as pd
import dash
from dash import dash_table
from dash import dcc
import dash_html_components as html
import plotly.express as px
# Connect to the PostgreSQL database
conn = psycopg2.connect(database="dev", user="root", password="", host="localhost", port="4566")
# Retrieve data from the materialized view using pandas
df = pd.read_sql_query("SELECT window_start, restaurant_id, total_order FROM restaurant_orders_view;", conn)
# Create a Dash application
app = dash.Dash(__name__)
# Define layout
app.layout = html.Div(children=[
html.H1("Restaurant Orders Table"),
dash_table.DataTable(id="restaurant_orders_table", columns=[{"name": i, "id": i} for i in df.columns], data=df.to_dict("records"), page_size=10),
html.H1("Restaurant Orders Graph"),
dcc.Graph(id="restaurant_orders_graph", figure=px.bar(df, x="window_start", y="total_order", color="restaurant_id", barmode="group"))
])
# Run the application
if __name__ == '__main__':
app.run_server(debug=True)
这一代码片段使用Pandas从restaurant_orders_view物化视图检索数据,并使用Dash_table.DataTable将其显示在Dash表中,使用dcc.Graph将数据显示在条形图中。该表和条形图的列与物化视图的列('window_start'、'total_order'和'restaurant_id')相对应,行与物化中的数据相对应。
步骤6:查看结果
可以通过运行上面的dash-example.py脚本并导航到http://localhost:8050/在网络浏览器中(用户会在终端收到一条消息,告诉转到这个链接)。
总结
总的来说,Dash是一个强大的工具,用于创建需要复杂用户界面和可视化功能的数据分析视图,所有这些都使用简单和优雅的Python编程语言。当将它与RisingWave流数据库一起使用时,可以深入了解实时数据,这可以帮助人们做出更明智的决策,并采取行动优化性能。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












