

随着字节跳动旗下业务的快速发展,数据急剧膨胀,原有的大数据架构在面临日趋复杂的业务需求时逐渐显现疲态。而伴随着大数据架构向云原生演进的行业趋势,字节跳动也对大数据体系进行了云原生改造。本文将详细介绍字节跳动大数据容器化的演进与实践。
字节跳动大数据业务发展现状
从2017年起,字节跳动陆续推出多款广为人知的热门应用,如抖音、今日头条、西瓜视频、剪映、番茄小说、懂车帝等。随着行业的快速发展和业务的高速迭代,数据量也呈爆炸式增长,海量的数据规模、愈加复杂的场景使得各大业务对字节底层大数据运算能力的要求不断提高。以抖音的实时推荐为例。系统需要从亿万级别的内容库中选出用户可能感兴趣的内容,运用复杂的模型对内容进行打分排序,再通过广告系统的处理,最后呈现给用户,整个过程需要在300毫秒内完成。这就对背后的计算能力提出了很高的要求,只有庞大的计算资源和极致的性能优化,才能达到这一业务需求。目前字节跳动的大数据集群已经支持了 EB 级的海量存储空间和千万级 Core 的计算资源调度能力。
大数据业务容器化
传统大数据组件繁多,安装运维复杂,在生产使用中需要大量的人力支持,不仅集群搭建费时费力,还容易形成运维孤岛和数据孤岛现象。同时在资源利用、可观测性等方面也存在诸多不足,已经越来越无法适应当下的发展需求。在此情况下,业界逐渐开始往云原生大数据方案发展。
云原生大数据是大数据平台新一代架构和运行形态,是一种以平台云原生化部署、计算云原生调度、存储统一负载为特点,可以支持多种计算负载,计算调度更弹性,存储效能更高的大数据处理和分析平台。云原生大数据带来了大数据在使用和运维方面的巨大变化,从以下两个角度来看:
·业务层面:传统模式下,业务独立占用资源,在低谷时段资源占用率可能只有20%-30%;云原生模式下的业务是混部的,比如在线和离线业务,它可以按分时复用的方式来调用资源,以此来提高集群利用率。
· 运维层面:传统的大数据架构通常是基于物理硬件的,每个集群都需要单独管理,扩展和升级非常困难。当需要增加更多的节点或更改硬件配置时,需要进行繁琐的人工操作,而且很容易出现错误。云原生模式将平台组件容器化后,可以利用弹性伸缩、自动化管理等特性,可以更好的进行集群的运维工作。
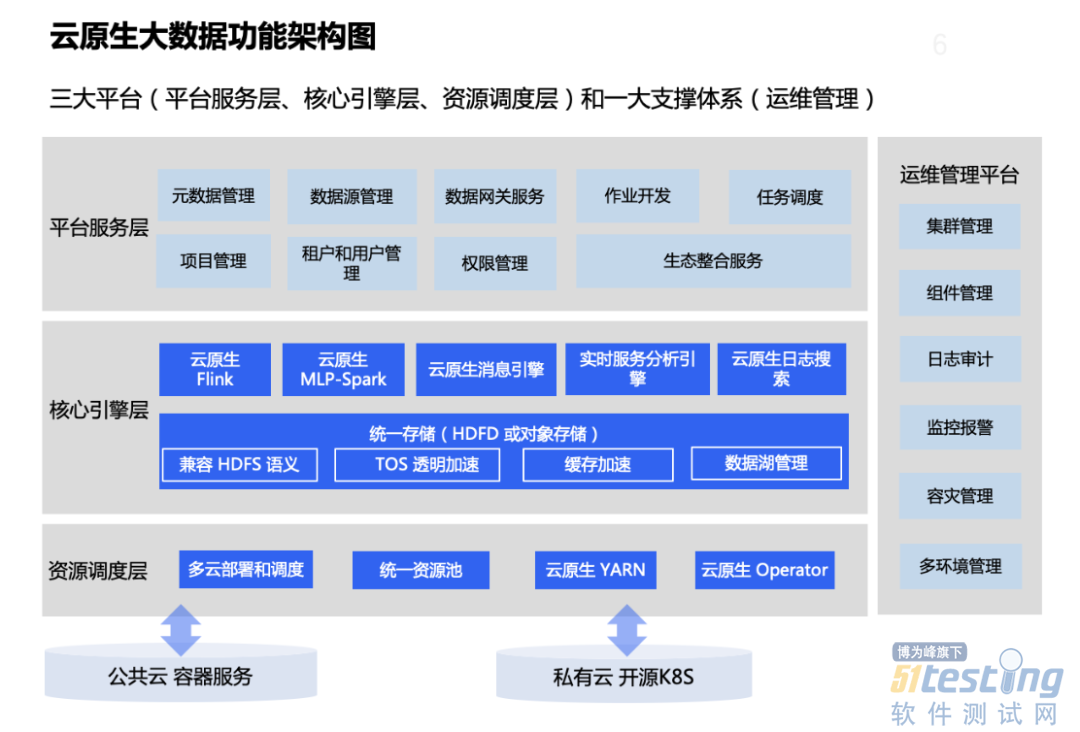
目前,新一代的字节跳动大数据平台已全面拥抱云原生,支持“三大平台和一大支撑体系”的功能架构:
· 平台服务层:由开源组件插件化集成,支持灵活配置选用;
· 核心引擎层:包括 Flink、Spark、云原生消息引擎、实时服务分析引擎、云原生日志搜索和统一存储 HDFS 等核心组件,支持存算分离和自动调优;
· 资源调度层:支持统一计算资源调度和统一引擎云原生生命周期管理。
· 运维管理平台 : 是集开源组件、服务生命周期、集群、容灾、可观测性于一体的一站式管理平台。
大数据业务容器化实践与探索
比较幸运的是,开源的大数据组件大部分将容器化基本做好了,如开源的 HDFS 其实已经可以直接基于 K8s 进行部署,像 Flink/Spark 这样的计算引擎也早就支持了 on K8s 部署和运行。因此在大数据业务容器化的过程中,我们要解决的问题是如何更好地运行和管理这些大数据任务。由此延伸,在此过程中会遇到以下几个主要问题:
·容器化平台不具备与 YARN 队列类似的资源管控能力;
· 调度器吞吐能力差,不适用于任务量大且运行时间较短的大数据作业;
· 调度器不存在“作业”概念,不具备作业排队能力,不具备作业级调度策略;
· 原生的大数据作业在容器化提交后,往往状态信息获取不准确;
· 大数据作业容器化部署后导致日志收集、监控告警变得复杂。
为了解决以上问题,字节跳动云原生大数据平台引入大数据作业调度器 GRO 封装 YARN 队列,提升大数据作业吞吐能力,并抽象作业支持企业级调度;引入云原生大数据 Operator Arcee,用于解决状态信息获取不准确的问题;构建统一运维平台,支持统一监控/日志等能力。以下我们将对这三部分进行展开介绍。

大数据作业的 Scheduler — — GRO
在大数据作业中,特别是批式计算的作业通常只会占用资源一段时间,在运行结束后即归还资源。而用户通常会提交多个作业,这就导致部分作业不能立即获得资源,而需要排队等待直到有作业结束退出后才能获得资源开始运行。但原生 Kubernetes 调度器最初是针对在线服务设计的,没有“队列”和“作业”这两个概念。为了更好地支持大数据场景资源分配,我们自研了高性能资源管理调度器 GRO,用于管控集群资源,并且新增了以下两个重要概念:
·Queue CRD:描述了一个“队列”,即 Quota(资源配额)的抽象;
· PodGroup CRD:描述了一个“作业”,用于标识多个 Pod 属于同一个集合,从而可以把多个 Pod 看作整体进行调度。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












