

在很多实际工作情况下,通过python等工具进行内容爬取,爬取的数据到本地后并不可用,需要进行清洗,清洗后导入到mysql数据库进行数据分析。对于少量文件可以删除http头信息后,另存为json文件,通过mysql的一些客户端程序直接导入,但对于成百上千个,甚至超过10万的json文件处理就比较麻烦,本文基于超过数万json文件的批量处理进行探索,数分钟解决了数据清洗。
一、程序功能设计
1.3-用户列表目录存放burpsuite爬取的数据。
2.爬取数据的格式为json文件。
3.爬取的文件带有http头内容,通过记事本等编辑器打开显示头文件内容为15行。
4.需要删除每一个文件中的前15行。
5.对所有目录下的文件命名为txt文件,处理完毕后命名为json文件。
6.依次读取所有json文件,通过逗号分隔列名,保存为out.txt文件。
7.程序处理出错,继续运行,且保存出错信息。

二、实现编程
这是一个 Python 程序,可以将一个目录中的 JSON 文件转换成 CSV 格式,然后将其写入到一个名为 "3-用户列表.txt" 的文件中,并记录执行过程中的错误信息到 "error.log" 文件中。
程序的主要逻辑如下:
获取目录中所有的文件(只包括文件),如果没有任何文件,则抛出异常;
遍历文件,如果文件的后缀不是 ".txt",则重命名文件名字并改变文件名变量的值;
读取文件内容,将前 15 行保留在一个字符串中,剩余部分作为新内容;
将新内容写回文件中;
将文件后缀名从 ".txt" 改为 ".json" 并修改文件名变量的值;
读取 JSON 文件的内容,并获取其中 "data" 中 "list" 数组中的每个元素的 key 值,这些 key 值作为表格的列名,并将这些列名保存到数组 "columns" 中;
遍历 "list" 数组中的每个元素,将每一行的值存入一个数组 "row_values" 中,最后将 "row_values" 中的所有值拼接成一个字符串,以逗号为分隔符,将其保存到数组 "rows" 中;
将 "columns" 和 "rows" 写入到 "3-用户列表.txt" 文件中。如果该文件的大小为0,那么先写入 "columns";否则直接写入 "rows" 内容;
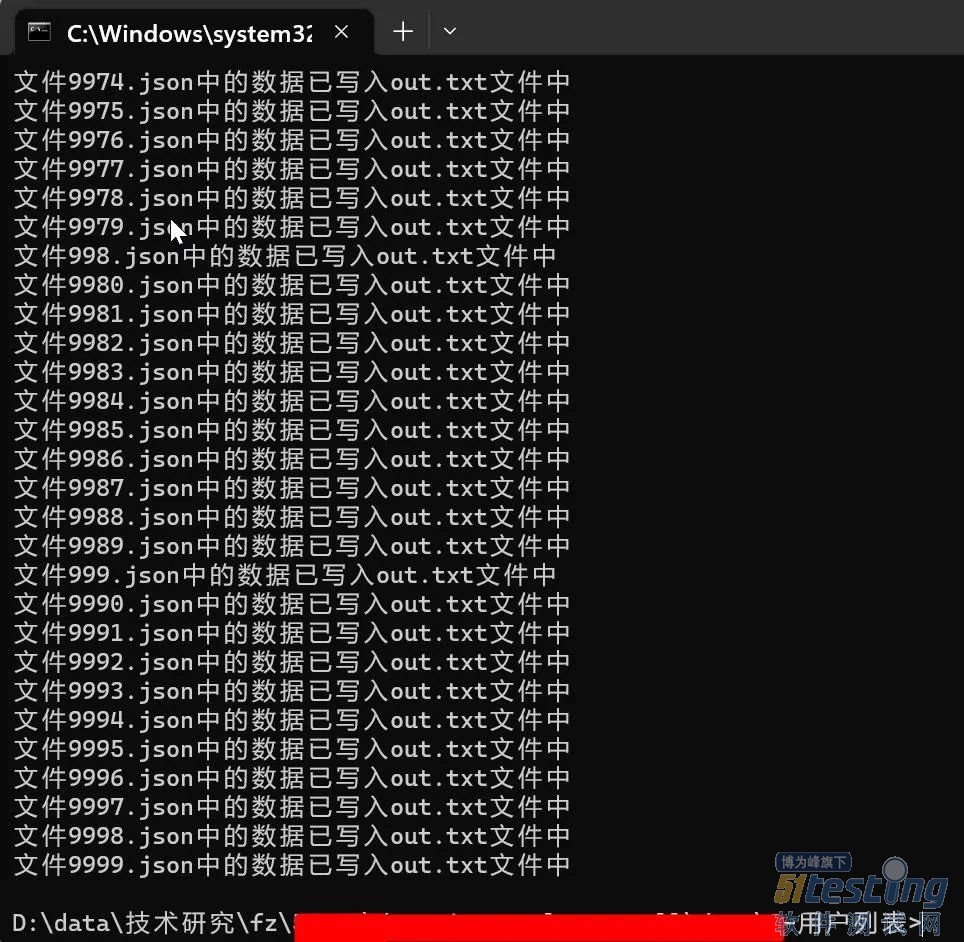
打印信息表明某个文件的数据被写入了 "out.txt" 文件中。
程序运行过程中出现错误,不会影响程序的整体执行,而是将错误信息记录到 "error.log" 文件中。
三、不断优化
优化内容:
增加了try-except语句,用于处理可能出现的异常情况;
增加了对目录下是否存在任何文件的判断,防止在空目录中运行程序;
增加了错误提示,如果程序出错会显示错误信息;
代码整体结构并没有变化,只是在原有的代码基础上增加了一些出错处理的逻辑。
import os
import json
dir = '3-用户列表'
try:
all_files = [f for f in os.listdir(dir) if os.path.isfile(os.path.join(dir, f))]
if not all_files:
raise Exception('该目录下不存在任何文件')
with open('error.log', 'a+', encoding='utf-8') as error_file:
for file in all_files:
try:
if not file.endswith('.txt'):
os.rename(os.path.join(dir, file), os.path.join(dir, os.path.splitext(file)[0] + '.txt'))
file = os.path.splitext(file)[0] + '.txt'
with open(os.path.join(dir, file), 'r', encoding='utf-8') as txt_file:
content = txt_file.readlines()
deleted_content = '\n'.join(content[:15])
new_content = ''.join(content[15:])
with open(os.path.join(dir, file), 'w', encoding='utf-8') as txt_file:
txt_file.write(new_content)
json_file = os.path.splitext(file)[0] + '.json'
os.rename(os.path.join(dir, file), os.path.join(dir, json_file))
with open(os.path.join(dir, json_file), 'r', encoding='utf-8') as j_file:
data = json.load(j_file)
columns = list(data['data']['list'][0].keys())
rows = []
for item in data['data']['list']:
row_values = []
for column in columns:
value = str(item[column]).replace('\n','').replace(',','')
row_values.append(value)
rows.append(','.join(row_values))
with open('3-用户列表.txt', 'a+', encoding='utf-8') as out_file:
if out_file.tell() == 0:
out_file.write(','.join(columns) + '\n')
out_file.write('\n'.join(rows)+'\n')
print("文件{}中的数据已写入out.txt文件中".format(json_file))
except Exception as e:
error_file.write('文件{}处理出错:{}\n'.format(file, e))
print('文件{}处理出错:{}'.format(file, e))
except Exception as e:
print("出错了:", e)
四、注意事项
1.需要看json数据格式:
data对应list不同的json文件中list不一样,需要在代码中进行修改。
2.处理后的文件内容可能存在重复,需要去重以及处理一些脏数据。
五、实际处理效果

本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












