

一、背景引入
首先简单介绍一下项目背景,公司对合作商家提供一个付费级产品,这个商业产品背后涉及到数百人的研发团队协作开发,包括各种业务系统来提供很多强大的业务功能,同时在整个平台中包含了一个至关重要的核心数据产品,这个数据产品的定位是全方位支持用户的业务经营和快速决策。
因为整套系统规模过于庞大,涉及研发人员很多,持续时间很长,文章难以表述出其中各种详细的技术细节以及方案,因此本文主要从整体架构演进的角度来阐述。
至于选择这个商家数据平台项目来聊架构演进过程,是因为这个平台基本跟业务耦合度较低,不像我们负责过的C端类的电商平台以及其他业务类平台有那么重的业务在里面,文章可以专注阐述技术架构的演进,不需要牵扯太多的业务细节。
此外,这个平台项目在笔者带的团队负责过的众多项目中,相对算比较简单的,但是前后又涉及到各种架构的演进过程,因此很适合通过文字的形式来展现出来。
二、商家数据平台的业务流程
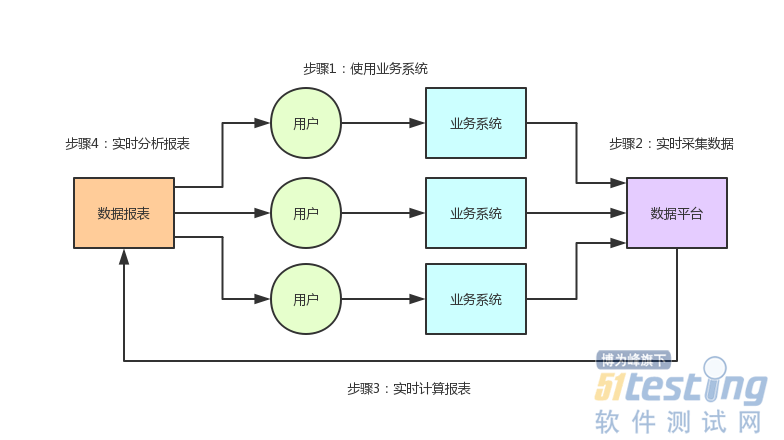
下面几点,是这个数据产品最核心的业务流程:
·每天从用户使用的大量业务系统中实时的采集过来各种业务数据。
· 接着存储在自己的数据中心里。
· 然后实时的运算大量的几百行~上千行的SQL来生成各种数据报表。
· 最后就可以提供这些数据报表给用户来分析。
基本上用户在业务系统使用过程中,只要数据一有变动,立马就反馈到各种数据报表中,用户立马就可以看到数据报表中的各种变化,进而快速的指导自己的决策和管理。
整个过程,大家看看下面的图就明白了。
三、从0到1的过程中上线的最low版本
看着上面那张图好像非常的简单,是不是?
看整个过程,似乎数据平台只要想个办法把业务系统的数据采集过来,接着放在MySQL的各种表里,直接咔嚓一下运行100多个几百行的大SQL,然后SQL运行结果再写到另外一些MySQL的表里作为报表数据,接着用户直接点击报表页面查询MySQL里的报表数据,就可以了!
其实任何一个系统从0到1的过程,都是比较low的,刚开始为了快速开发出来这个数据平台,还真的就是用了这种架构来开发,大家看下面的图。
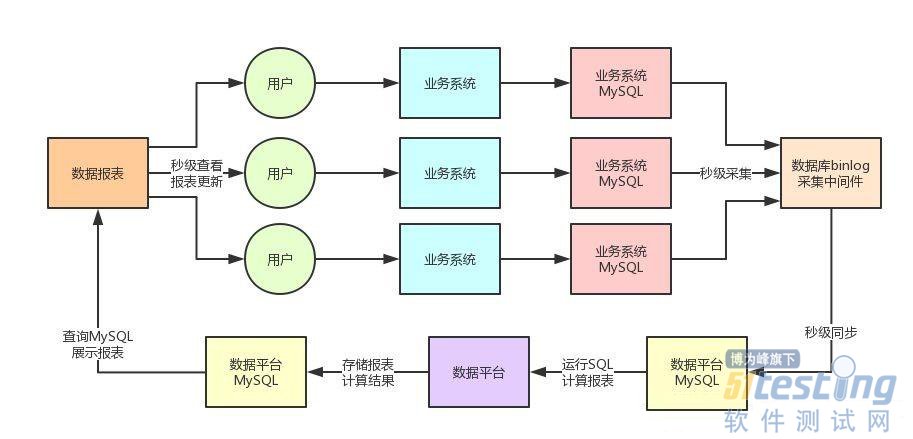
其实在刚开始业务量很小,请求量很小,数据量很小的时候,上面那种架构也没啥问题,还挺简单的。
我们直接基于自己研发的数据库binlog采集中间件(这个是另外一套复杂系统了,不在本文讨论的范围里,以后有机会可以聊聊),感知各个业务系统的数据库中的数据变更,毫秒级同步到数据平台自己的MySQL库里。
接着数据平台里做一些定时调度任务,每隔几秒钟就运行上百个复杂大SQL,计算各种报表的数据并将结果存储到MySQL库中。
最后用户只要对报表刷新一下,立马就可以从MySQL库里查到最新的报表数据。
基本上在无任何技术挑战的前提下,这套简易架构运行的会很顺畅,效果很好。然而,事情往往不是我们想的那么简单的,因为大家都知道国内那些互联网巨头公司最大的优势和资源之一,就是有丰富以及海量的C端用户以及B端的合作商家。
对C端用户,任何一个互联网巨头推出一个新的C端产品,很可能迅速就是上亿用户量。
对B端商家,任何一个互联网巨头如果打B端市场,凭借巨大的影响力以及合作资源,很可能迅速就可以聚拢数十万,乃至上百万的付费B端用户。
因此,很不幸,接下来的一两年内,这套系统将要面临业务的高速增长带来的巨大技术挑战和压力。
四、海量数据存储和计算的技术挑战
其实跟很多大型系统遇到的第一个技术挑战一样,这套系统遇到的第一个大问题,就是海量数据的存储。
你一个系统刚开始上线也许就几十个商家用,接着随着你们产品的销售持续大力推广,可能几个月内就会聚拢起来十万级别的用户。
这些用户每天都会大量的使用你提供的产品,进而每天都会产生大量的数据,大家可以想象一下,在数十万规模的商家用户使用场景下,每天你新增的数据量大概会是几千万条数据,记住,这可是每天新增的数据!这将会给上面你看到的那个很low的架构带来巨大的压力。
如果你在负责上面那套系统,结果慢慢的发现,每天都要涌入MySQL几千万条数据,这种现象是令人感到崩溃的,因为你的MySQL中的单表数据量会迅速膨胀,很快就会达到单表几亿条数据,甚至是数十亿条数据,然后你对那些怪兽一样的大表运行几百行乃至上千行的SQL?其中包含了N层嵌套查询以及N个各种多表连接?
我跟你打赌,如果你愿意试一下,你会发现你的数据平台系统直接卡死,因为一个大SQL可能都要几个小时才能跑完。然后MySQL的cpu负载压力直接100%,弄不好就把MySQL数据库服务器给搞宕机了。
所以这就是第一个技术挑战,数据量越来越大,SQL跑的越来越慢,MySQL服务器压力越来越大。
我们当时而言,已经看到了业务的快速增长,因此绝对要先业务一步来重构系统架构,不能让上述情况发生,第一次架构重构,势在必行!
五、离线计算与实时计算的拆分
其实在几年前我们做这个项目的时候,大数据技术已经在国内开始运用的不错了,而且尤其在一些大型互联网公司内,我们基本上都运用大数据技术支撑过很多生产环境的项目了,在大数据这块技术的经验积累,也是足够的。
针对这个数据产品的需求,我们完全可以做到,将昨天以及昨天以前的数据都放在大数据存储中,进行离线存储和离线计算,然后只有今天的数据是实时的采集的。
因此在这种技术挑战下,第一次架构重构的核心要义,就是将离线计算与实时计算进行拆分。
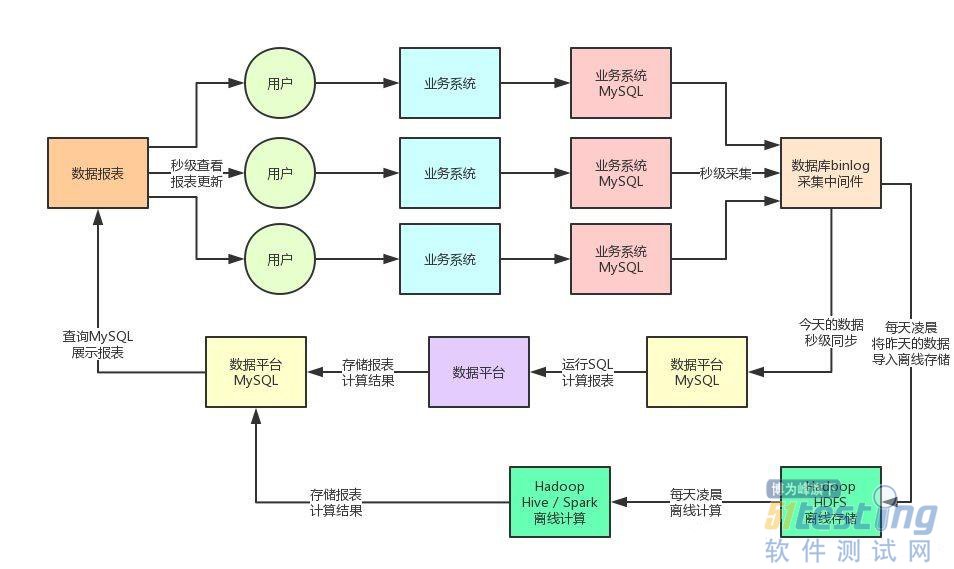
大家看上面那张图,新的架构之下,分为了离线与实时两条计算链路。
一条是离线计算链路:每天凌晨,我们将业务系统MySQL库中的昨天以前的数据,作为离线数据导入Hadoop HDFS中进行离线存储,然后凌晨就基于Hive / Spark对离线存储中的数据进行离线计算。
在离线计算链路全面采用大数据相关技术来支撑过后,完美解决了海量数据的存储,哪怕你一天进来上亿条数据都没事,分布式存储可以随时扩容,同时基于分布式计算技术天然适合海量数据的离线计算。
即使是每天凌晨耗费几个小时将昨天以前的数据完成计算,这个也没事,因为凌晨一般是没人看这个数据的,所以主要在人家早上8点上班以前,完成数据计算就可以了。
另外一条是实时计算链路:每天零点过后,当天最新的数据变更,全部还是走之前的老路子,秒级同步业务库的数据到数据平台存储中,接着就是数据平台系统定时运行大量的SQL进行计算。同时在每天零点的时候,还会从数据平台的存储中清理掉昨天的数据,仅仅保留当天一天的数据而已。
实时计算链路最大的改变,就是仅仅在数据平台的本地存储中保留当天一天的数据而已,这样就大幅度降低了要放在MySQL中的数据量了。
举个例子:比如一天就几千万条数据放在MySQL里,那么单表数据量被维持在了千万的级别上,此时如果对SQL对应索引以及优化到极致之后,勉强还是可以在几十秒内完成所有报表的计算。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












