

|
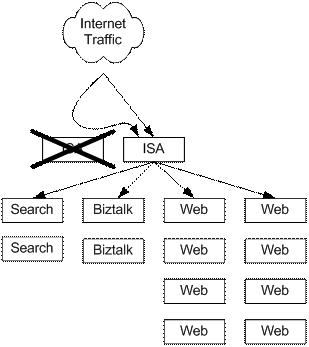
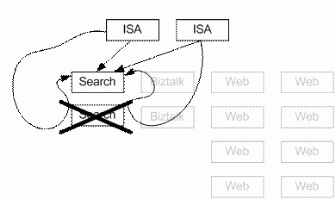
MSIB 2.0 企业部署的恢复模型下图给出了 MSIB 2.0 企业部署中典型的单点故障,下表介绍了 MSIB 2.0 企业部署是如何从单点故障中恢复过来的。 为了避免发生这些单点故障,建议您在投入实际运行之前在您的 MSIB 2.0 企业部署中采用本文前面介绍的高可用性技术。 注: 在下表中,所谓的可接受时限是指小于默认 ASP 超时时间的一个期间,在理想情况下为 15 秒钟或更少。 为了进行本文所述的测试,所有的故障切换时间都由 MSIB 项目组进行了记录。
服务器故障切换恢复 前面的部分讨论了如何利用网络负载均衡(NLB)和 Microsoft Cluster Service (MSCS)消除单点故障。 这一部分的目的是要介绍,当您在企业部署种使用了 NLB 和MSCS 时,MSIB 2.0 是如何从故障种恢复过来的。 ISA 故障切换 在 ISA 服务器因服务器故障而出现故障的时候, NLB 软件(运行在 ISA 服务器之上)将会把故障服务器从 NLB 群集中删除掉。 在 ISA 服务器因连接、RPC 或磁盘故障而出现故障的时候,ISA 服务器会将自己从群集中脱离开。 最后的结果是,仍然正常的冗余服务器将会把所有的请求接管过来。
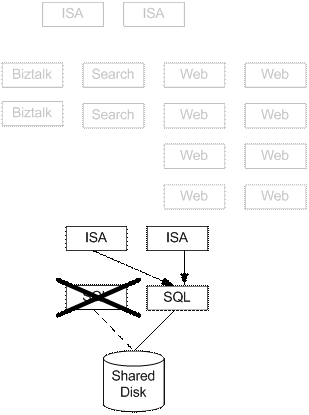
NLB 故障切换 当某一表示层服务器不能发送或响应心跳消息的时候,其他服务器将会进行收敛。 最后的结果是,仍然可对请求作出响应的表示服务器会为故障服务器处理所有的入站请求。 当某台新的表示服务器试图加入到该群集的时候,它将会发出一个意在收敛的心跳消息。 当所有的表示服务器都同意接受该成员的时候,将会对客户端的工作量重新划分。 SQL Server MSCS 数据库故障切换 SQL Server 使用了一套共享的磁盘子系统,它可以以一个群集服务器的形式工作。 当群集中的某活动 SQL 服务器出现故障的时候,备用的 SQL 服务器将会接管故障服务器的负载,处理客户请求,从同一共享盘上读取和写数据,如下图所示。
确定预期的可用性这一部分将介绍一个计算实例,MSIB 项目组为本文使用了这种计算方法以确定 MSIB 2.0 企业部署的可用性,也称为预期的正常运行时间。 这一实例是根据 Microsoft Technical Report 中的Markov Model of Availability for Server Clusters 中的数学模型给出的,地址在 http://go.microsoft.com/fwlink/?LinkId=15127. 在这一模型中需要考虑五个 MSIB 2.0 企业部署的群集。 这五个群集都是由两个节点/计算机构成的,它们必需能够正常运行,令那些考虑要可用的系统真正可用。 出于这一分析的考虑,群集列举如下:
每个群集都有一个可用性,p n 其中,0 p1 X p2 X p3 X p4 X p5 群集内每个节点的可用性可以通过带入以下三个数值的平均测量值得到。
MSIB 项目组首先切断活动-活动群集中来自服务器/节点的基本网络连接,然后再重新启用这些连接,通过这种方法测量了企业部署的恢复时间和故障切换时间。 对于活动——被动 SQL 群集,项目组从群集管理控制台执行了一个移动组命令。 如需了解关于如何测定恢复时间和故障切换时间的更多信息,参见“附件 C——Collecting Availability Data”。 请注意由 MSIB 项目组为本文所述测试部署的系统是按照 MSIB 2.0 随带的 MSIB 2.0 Deployment Guides 中所述的严格的设置和配置进行部署的。 顶级 ISA NLB 群集 顶级 ISA 网络负载均衡(NLB)群集是一种双节点的 NLB Web 服务器群集。 这一系统的可用性是根据服务器群集可用性的马尔可夫模型(MMASC)计算的。 这一实例是根据 Microsoft Technical Report 中的Markov Model of Availability for Server Clusters 中的数学模型给出的,地址在 http://go.microsoft.com/fwlink/?LinkId=15127对这一群集来说,MSIB 项目组发现其平均故障切换时间为 3 分钟,MTTR 时间为 9 分钟 56 秒。 下表给出了根据搜集到的数据和节点的目标 MTTF 为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.8867% 下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9735% 注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2节点活动-活动群集的一半。 Web NLB 群集 顶级 Web 服务器 NLB 群集是一种双节点的 NLB 服务器群集。 这种系统的可用性是根据 MMASC 计算的。 对这一层来说,MSIB 项目组发现其平均故障切换时间为 15 分钟,MTTR 时间为 9 分钟 2 秒。 下表给出了两个不同的 MTTF ,并展示了 MTTF 数值是如何影响节点的总体可用性的。 下表给出了根据搜集到的数据,改变节点的 MTTF ,为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9092% 下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9788% 注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2节点活动-活动群集的一半。 搜索 NLB 群集 顶级 搜索 NLB 群集也是一种双节点的 NLB 服务器群集。 这种系统的可用性是根据 MMASC 计算的。 对这一层来说,MSIB 项目组发现其平均故障切换时间为 15 秒钟,MTTR 时间为 4 分钟 56 秒。 下表给出了两个不同的 MTTF ,并展示了 MTTF 数值是如何影响节点的总体可用性的。 下表给出了根据搜集到的数据,改变节点的 MTTF ,为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9498% 。 下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9883% 注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2节点活动-活动群集的一半。 中级 ISA NLB 群集 中级 ISA 网络负载均衡(NLB)群集是一种双节点的 NLB 服务器群集。 这种系统的可用性是根据 MMASC 计算的。 MSIB 项目组发现,这一层的平均故障切换时间为三分钟,故障服务器重新加入群集需要六分钟三十六秒的时间。 下表给出了两个不同的 MTTF ,并展示了 MTTF 数值是如何影响节点的总体可用性的。 下表给出了根据搜集到的数据,改变节点的 MTTF ,为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9197% 下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9813% 注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2 节点活动-活动群集的一半。 SQL Server 群集 顶级 SQL 服务器 是一种双节点的活动——被动 MSCS 群集。 这种系统的可用性是根据 MMASC 计算的。 注: 前面两张表格是和介绍活动-活动群集的表格不同的,这是因为当群集某一成员发生故障的时候,活动——被动群集不能进行更多的工作。 这样一来,最后一个节点进行故障切换的 MTTF 就等于前一个活动节点的值。 MSIB 项目组发现,这一层的平均故障切换时间为五分钟,故障服务器重新加入群集需要八分钟三十秒的时间。 下表展示了 MTTF 数值是如何影响群集的总体可用性的。
使用 MMASC 方法,此 2 节点活动——被动群集计算得到的可用性为 99.9504% 下表给出了在目标平均时间为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。
使用 MMASC 方法,此 2 节点活动——被动群集计算得到的可用性为 99.9884% 整体可用性 如前所述,整个集成系统的可用性为以下计算的结果: p1 X p2 X p3 X p4 X p5 对每个节点都以 MTTF 为一星期和一个月为条件进行计算。 利用这个方程, IT 专业人员可以建立起每个节点的目标 MTTF ,从而实现可测量的整系统可用性。 这样一来您就能够掌握主动,决定目标 MTTF 是多少,而不是必需要猜测为了满足正常运行时间标准系统出现故障之后 MTTF 将会是多少。 这一分析确切地给出了要实现整系统可用性服务水平协议的要求哪些节点必需要加以改进。 下表总结了如本部分前面所述使用了同样的 MTTF 向量的系统的整体可用性。
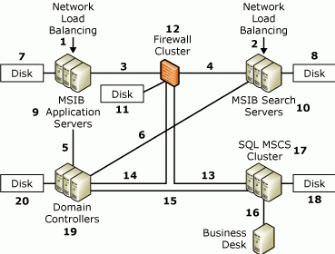
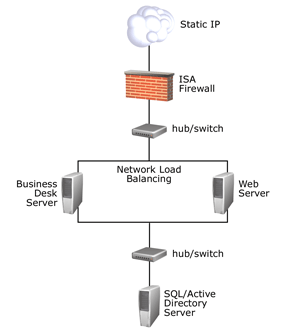
附录 A ——硬件和网络拓扑详述这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的硬件和网络拓扑。 下图给出了 MSIB 2.0 基础部署的网络图。
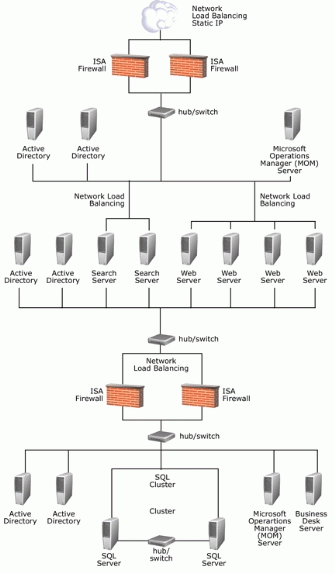
下图给出了 MSIB 2.0 企业部署的网络图。 这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的 Web 服务器的配置。 Web 服务器
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的搜索服务器的配置。 搜索服务器
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的 SQL Server 的配置。 SQL server
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的 ISA 服务器的配置。 ISA 服务器
附录 B——许可计算下表给出了 MSIB 项目组创建的两个电子数据表。 以后可以从与本文所在的同一 Web 页面上获得这些表格。
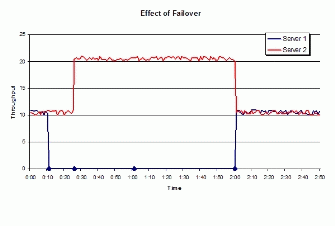
附录 C — 搜集可用性数据当两台服务器利用网络负载均衡(NLB)工作在活动-活动群集的模式下时,这对服务器的系统吞吐量情况将会和下图类似。 X轴上标出了 4 个点,它们代表了与 NLB 故障切换和恢复过程有关的事件。 从 0:00 到第一个标识点(0:10),群集处于正常运行状态,服务器 1 和服务器 2 分担着同样的负载或吞吐量。到了这一刻,服务器 1 出现故障,无法工作了。 从 0:10 到 0:26 ,到服务器 1 的所有请求都丢失了,这是因为群集还没有发现服务器 1 出现故障了。 在这期间,群集是以不到一半的容量运行的。 在 0:26 秒的时候,群集发现了服务器 1 的故障,服务器 2 开始处理其请求。 此时服务器 2 是在两倍的负荷工作的,不过仍然在其限额之内。 1:01 (图中标注的第三个点)时,服务器 1 重新设定了 W3 SVC 服务,这一过程大约需要一分钟的时间。 2:00 (图中标注的第四个点)时,服务器 1 恢复过来并通过收敛过程重新加入到 NLB 群集中来。 在做可用性分析的时候,为了测量群集的恢复时间和故障切换时间,您需要监控两个时间间隔长度:
为了测量 MTTR ,您应当具备管理软件或警告软件,以检测故障并完成故障恢复过程。 对 MSIB 来说,建议您利用 Microsoft Operations Manager (MOM)实现错误发现和解决的自动化。 如果您没有用以自动检测和故障恢复的解决方案,您应当将解决 IT 问题的平均时间作为 MTTR 。 本文中的信息,包括 URL 及其他 Internet Web 站点的引用,如有更改恕不另行通知。 除非另外指明,在本文例中提到的公司、单位、产品、域名、e-mail 地址、徽标、人员、地点和事件等都是虚构的,不与任何真实的公司、单位、产品、域名、e-mail地址、徽标、人员、地点和事件发生任何联系,也不应从中做任何此类联系方面的推断。 用户有责任遵守所有适用的版权法律。 在不限制版权所赋予权利的前提下,没有 Microsoft Corporation 明确的书面允许,不得以任何形式或通过任何手段(电子的、机械的、影印、录制或其他)或出于任何目的复制本文的任何部分或将其存储或引入检索系统,或进行传播。 Microsoft 可能具有一些专利、专利申请、商标、版权或其他知识产权涉及到本文所述主题。 除非微软公司通过书面许可协议明确提供,此文档并没有授予您对这些专利,商标,版权或其他知识产权的任何许可。 © 1996-2003 Microsoft Corporation 。 保留所有权利。 Microsoft 、Active Directory、MS-DOS、Windows、Windows NT 和 SharePoint 为 Microsoft Corporation 在美国和/或其他国家的注册商标或商标。 本文提到的实际公司和产品的名称可能是其相应所有者的商标。
|












;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}