

用Robot进行性能测试,datapool几乎是少不了的,但是以前用datapool通常用的都是默认的值,让其能够顺序取值就OK了,没有做过深入的研究,最近折腾了一下,发现datapool的各个设置其实很有用的,以一个简单的脚本为例:
#include <VU.h>
{
DP1 = datapool_open("test");
datapool_fetch(DP1);
print("test"+datapool_value(DP1, "unitCode")+"\n");
}
DATAPOOL_CONFIG "test" DP_SEQUENTIAL DP_SHARED DP_PERSISTENT DP_WRAP
{
INCLUDE, "unitCode", "string", "0005";
}
从上述脚本我们可以看出要在VU脚本中使用datapool,必须在其中添加DATAPOOL_CONFIG,后面需要配置的有datapool名,以及datapool的属性,下面是其可用的column列表,录制的脚本中默认datapool中元素的键值为EXCLUDE,必须改为INCLUDE,否则不会去读取datapool中设置的值。
我们从最常见的设置开始,datapool最常见的情况是一个脚本一个datapool,各个虚拟用户都依次读取datapool中的值,直至datapool结束。这时候除了要将需要用到的column前的EXCLUDE改为INCLUDE外,我们还需要在datapool properties中use script data选择为obey usage,否则将不会读取datapool中的数据。
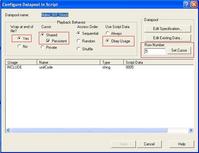
上图为datapool properties对话框,我们从左到右依次解释其中的选项设置,wrap at the end of file?,如果选择No,则当datapool中读取到最后一条记录后,读取下一条记录将会产生错误,vuser将会退出并报错,如果希望在从头开始读取,则该项选择Yes;Cursor,表示的是datapool中记录读取的顺序,如果设置为shared,则各个user共享cursor,如果数据不能重复,需要选择shared,这样多个用户并发添加数据的时候,不会添加同一条;其中的persistent复选框如果选中的话,cursor值将会在各个suite之间传递,比如一个有30行记录的datapool,默认的cursor值为1,选中persistent的情况下运行5次后,将会变成5,目前尚未用到这种情况,所以我一般去掉该复选框的,private如果选中,则各个vuser读取datapool相互独立,都是从头读到尾;Access Order控制的是datapool中记录读取的顺序,sequential为顺序读取,random为随机读取,shuffle为乱序读取,根据需要选择就可以了;Use script data,如果选中Always,则会使用脚本中录制时候的数据,而不是datapool中的数据,因此如果你要使用datapool中的数据,选择Obey Usage。
以上就是datapool的基本属性设置,各个选项之间的具体差别可以通过自己实验来确定。












