

在代码设计中时常面对这样的场景,给定两个元素,我们需要快速判断他们是否属于同一个集合,同时不同的集合在需要时还能快速合并为一个集合,例如我们要开发一个社交应用,那么判断两个用户是否是朋友关系,或者两人是否属于同一个群就需要用到我们现在提到的功能。
这些功能看似简单,但有个难点在于你要处理的“足够快”,假设a,b两个元素分别属于集合A,B,判断它们是否属于同一个集合的直接做法就是遍历集合A中所有元素,看看是否能找到b,如果集合A中包含n个元素,那么该做法的时间复杂度就是O(n),当集合元素很多,而且判断的次数也很多时,这样的做法效率就会很低,本节我们要看看能不能找到次线性的算法。
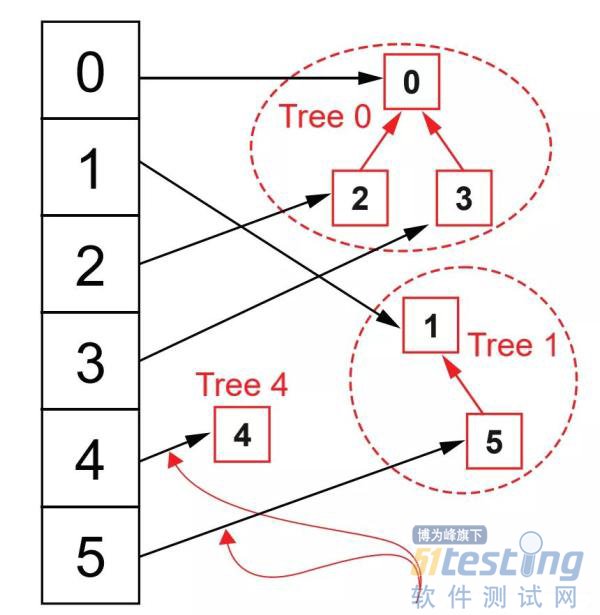
我们先看复杂度为O(n)的算法逻辑,假设我们有6个元素,编号分别为0到6,我们可以使用队列来模拟集合,属于同一个集合的元素就存储在同一个队列中,然后每个元素通过哈希表映射到队列头,如下图所示:

在这种数据结构下,查询两个元素是否属于同一个集合,那么只要通过哈希表找到各自元素所在队列的头部,判断头部是否一致即可,我们用areDisjoint(x,y)来表示两个元素是否属于一个集合,那么在当前数据结构下areDisjoint的时间复杂度是O(1)。
如果要合并两个元素所在集合,我们用merge(x,y)来表示,那么在当前结构下,我们只要找到x和y对应的队列头部,然后从x所在队列的头部遍历到最后一个元素,然后将最后一个元素的next指针执行y所在的队列头部,如下图所示:

同时我们还需要做一个操作,那就是修改第二个集合中每个元素映射的队列头部,因此在当前结构下,merge(x,y)对应时间复杂度为O(n),因为从队列头遍历到末尾是O(n),同时遍历y所在集合每个元素,修改他们映射的队列头,时间复杂度也是O(n)。
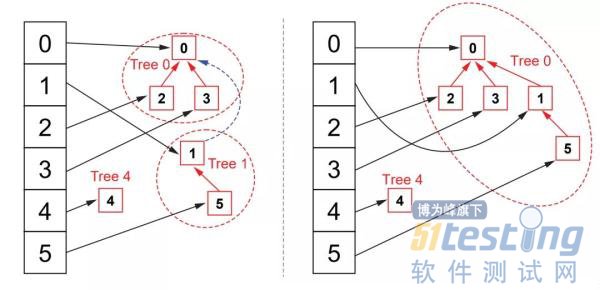
现在问题是我们能否将合并所需要的时间进行优化。我们注意到合并时有两个步骤很耗时,一是从队列走到队尾,二是修改第二个集合中每个元素指向的队列头。所以耗时其实是因为我们使用队列来表示集合所导致。为了优化时间,我们将队列换成多叉树,如下图所示:
此时我们不再使用哈希表来将元素映射到队列头部,而是将同一个集合的元素安插到同一个多叉树中,要判断两个元素是否属于同一集合,我们只要沿着元素的父节点指针往上走一直找到树的根节点,如果找到相同的根节点,那么两个元素就属于同一集合,对于排序二叉树而言,树的高度为O(lg(n)),n是树的节点数,于是判断两个元素是否属于同一集合所需时间复杂度为O(lg(n))。
当需要合并两个元素对于的集合时,我们分别找到两个元素对于的根节点,然后将高度较低的那棵树的根节点作为高度较高那棵树的子节点,这个处理对效率很重要,后面我们会进一步研究,树合并的情形如下图所示:
下面我们先看看代码实现:
# This is a sample Python script.
# Press ?R to execute it or replace it with your code.
# Press Double ? to search everywhere for classes, files, tool windows, actions, and settings.
class Element:
def __init__(self, val : int):
self.val = val
self.parent = self #元素在创建时自己形成一个单独集合,因此父节点指向自己
def value(self):
return self.val
def parent(self):
return self.parent
def set_parent(self, parent):
assert parent is not None
self.parent = parent
class DisjontSet:
def __init__(self):
self.hash_map = {}
def add(self, elem : Element):
assert elem is not None
if elem.value() in self.hash_map:
return False
self.hash_map[elem.value()] = elem
return True
def find_partition(self, elem : Element):
#返回元素所在集合的根节点
assert elem is not None or elem.value() in self.hash_map
parent = elem.parent()
if parent != elem: #递归查找根节点,树的高度为lg(n),所以这里查找的时间复杂度为lg(n)
parent = self.find_partition(parent)
return parent
def are_disjoint(self, elem1 : Element, elem2 : Element):
#判断两个元素是否属于同一集合只要判断他们再哈希表中映射的根节点是否同一个
root1 = self.find_partition(elem1)
root2 = self.find_partition(elem2)
return root1 is not root2
def merge(self, elem1 : Element, elem2 : Element):
root1 = self.find_partition(elem1)
root2 = self.find_partition(elem2)
if root1 is root2:
#两个元素属于同一个集合
return False
root2.setParent(root1)
self.hash_map[root2.value()] = root1 #设置root2对应的父节点
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
# See PyCharm help at https://www.jetbrains.com/help/pycharm/
由于我们将集合的表示从队列改为了多叉树,因此集合的查找与合并对应复杂度为O(lg(n)),现在问题是我们能否继续改进效率。当前merge函数耗时在于我们要通过parent指针一直爬到根节点,如果能让parent指针直接指向根节点那么不就省却向上爬的时间开销吗,这种直接将下层节点父指针直接指向根节点的办法叫路径压缩,如下图所示:
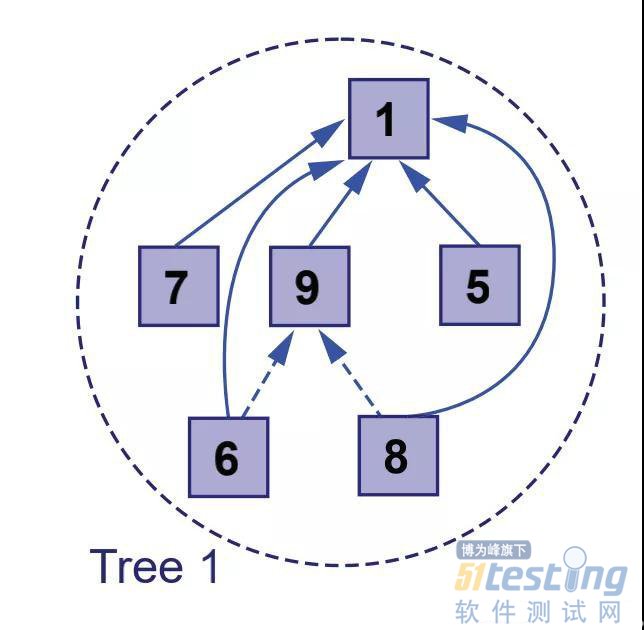
从上图看到,节点6,8的父节点原来是9,它所在集合的根节点是1,于是我们直接将原来指向9的指针直接指向根节点1,这样以后在合并或查询集合时我们就可以省掉向上爬的时间开销。还有一个问题在上面代码中两棵树合并问题,我们仅仅是把root2的父指针指向root1,这么做会存在合并后树不平衡问题,也就是合并后的左右子树高度可能相差较大,这种情况也会对效率产生不利影响,如下图所示:
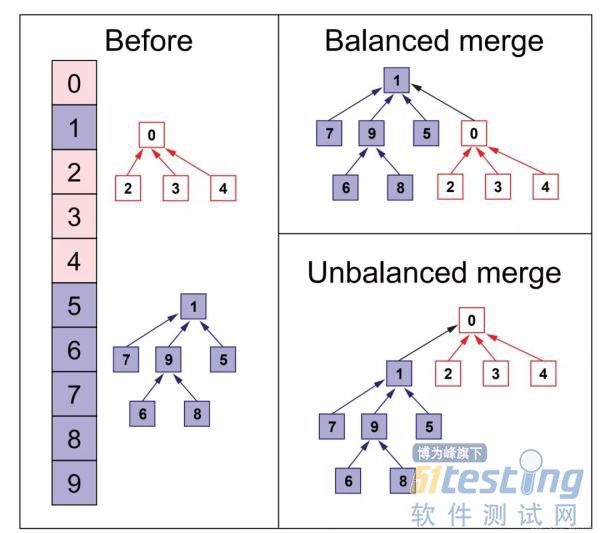
可以看到右下角合并后左右子树高度差异大,于是节点,6,8找到根节点0所需的时间就要比2,3,4要多,但形成右上角的情况时,叶子节点6,8和2,3,4找到根节点的时间就差不多,这样就有利于效率的提高,所以我们还需要记录下树的高度,在合并时要将高度小的树合向高度高的树,因此代码修改如下:
class Element:
def __init__(self, val : int):
self.val = val
self.parent = self #元素在创建时自己形成一个单独集合,因此父节点指向自己
self.rank = 1 #表示树的高度
def value(self):
return self.val
def parent(self):
return self.parent
def set_parent(self, parent):
assert parent is not None
self.parent = parent
def get_rank(self):
return self.rank
def set_rank(self, rank):
assert rank > 1
self.rank = rank
然后我们需要修改find_partition的做法。
def find_partition(self, elem : Element):
#返回元素所在集合的根节点
assert elem is not None or elem.value() in self.hash_map
parent = elem.parent()
if parent is elem: #已经是根节点
return elem
parent = self.find_partition(elem) #获得集合的根节点
elem.set_parent(parent) #路径压缩直接指向根节点
return parent #返回根节点
注意到find_partion的实现中有递归过程,如果当前节点不是根节点,那么递归的查询根节点,然后把当前节点的parent指针直接指向根节点,我们看到这步修改所需的时间复杂度跟原来一样都是lg(n)。
接下来我们要修改merge的实现:
def merge(self, elem1 : Element, elem2 : Element):
root1 = self.find_partition(elem1)
root2 = self.find_partition(elem2)
if root1 is root2: # 两个元素属于同一个集合
return False
new_rank = root1.get_rank() + root2.get_rank()
if root1.get_rank() >= root2.get_rank(): # 根据树的高度来决定合并方向
root2.set_parent(root1)
root1.set_rank(new_rank)
else:
root1.set_parent(root2)
root2.set_rank(new_rank)
return True
这种改进后,在m次指向find_partion和merge调用时所需要的时间是O(m),也就是说在改进后,当大量调用find_partion和merge时,这些调用的平均耗时降到了O(1),也就是说路径压缩后,其效果在大批量的调用查找集合和合并集合操作时能出现非常显著的效率提升,其对应的数学证明非常负责,我们暂时忽略调。我们可能对这里的效率提升感受不到,但想想微信中对两个人是否属于同一个群的调用一天至少也有千万乃至上亿次吧,因此这里的改进能大大的改进服务器的处理效率。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












