

2.1.6 时间复杂度
算法的时间复杂度计算方法
算法的时间复杂度是数据结构中的重要理论基础,也是较难理解和掌握的问题之一。本节总结了计算时间复杂度的方法。
计算算法的时间复杂度的具体步骤如下。
(1)找出算法中的基本语句。算法中执行次数最多的那条语句就是基本语句,通常它是最内层循环的循环体。
(2)计算基本语句的执行次数的数量级。只计算最高次幂的,忽略所有低次幂和最高次幂的系数。
(3)用O()记号表示算法的时间复杂度。将基本语句执行次数的数量级放入O()记号中。对于并列循环,忽略;对于嵌套循环,相乘。例如,若一层循环的时间复杂度为O(n),两层循环的时间复杂度就是O(n2),依此类推。
常见的算法时间复杂度由小到大依次如下。
Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!)
2.1.7 笔试题和面试题
试题1.在一个长度为n的顺序存储线性表中,向第i个元素(1≤i≤n+1)之前插入一个新元素,需要从后向前依次后移几个元素?当删除第i个元素时,需要从前向后前移几个元素?
分析:考查线性表中顺序存储的特点。
答案:n-i+1,n-i。
试题2.已知链表的头节点head,写一个函数把该链表逆序。
分析:考查线性表中链表逆序算法。
答案:
void List::reverse()
{
list_node*p=head;
list_node*q=p->next;
list_node*r=NULL;
while(q){;
r=q->next;
q->next=p;
p=q;
q=r;
}
head->next=NULL;
head=p;
}?
试题3.找出单向链表中的中间节点。
分析:有两个指针,一个指针的步长为1,另一个指针的步长为2。步长为2的指针指向链表末尾后步长为1的指针正好指向链表中间。
答案:
list_node*List::middleElement()
{
list_node*p=head;
list_node*q=head->next;
while(q){;
p=p->next;
if(q)q=q->next;
if(q)q=q->next;
}
}
试题4.如何检查一个单向链表中是否有环?
分析:同样有两个指针,一个指针的步长为1,另一个指针的步长为2,如果两个指针能相遇则有环。
答案:
list_node*List::getJoinPointer()
{
if(head==NULL||head->next==NULL)return NULL;
list_node*one=head;
list_node*two=head->next;
while(one!=two){
one=one->next;
if(two)two=two->next;
else break;
if(two)two=two->next;
else break;
};
if(one==NULL||two==NULL)return NULL;
return one;
}
试题5.给定单链表,如果有环则返回,从头节点(head)进入环的第1个节点。
分析:如果有环,那么p1与p2的重合点p必然在环中。从p点断开环,方法为令p1=p,p2=p->next,p->next=NULL。此时,原单链表可以看作两个单链表,一个从head开始,另一个从p2开始,于是运用本节中试题2的方法,我们找到它们的第一个交点即可。
答案:
list_node*List::findCycleEntry()
{
if(checkCycle()==false)return NULL;
list_node*joinPointer=getJoinPoiter();
list_node*p=head;
list_node*q=joinPointer->next;
While(p!=q)
{
p=p->next;
q=q->next;
}
return p;
}?
试题6.只给定单链表中某个节点p(并非最后一个节点,即p->next!=NULL),删除该节点。
分析:将p后面那个节点的值复制到p,删除p后面的节点。
答案:
void List::deleteByPointer(list_node*node)
{
if(node)
{
if(node->next){
node->value=node->next->value;
node->next=node->next->next;
}
}
}
试题7.在单链表节点p前面插入一个节点。
分析:首先在p后面插入一个节点,然后将p的值与后面一个节点的值互换。
答案:类似于本节中试题6的答案,此处省略。
试题8.给定单链表头节点,删除链表中倒数第k个节点。
分析:第一个指针指向链表头,第二个指针指向第k个节点,然后两个指针一起移动,若第二个指针指向链表末尾,则第一个指针指向倒数第k个节点。
答案:
list_node*List::lastKelement(int k){
Int t=k;
list_node * p = head;
while(p&&t){
p=p->next;
t--;
}
if(p==NULL&&t>0)return NULL;
list_node*q=head;
while(q&&p){
p=p->next;
q=q->next;
}
return q;
}
试题9.判断两个链表是否相交。
分析:有两种情况。如果链表中有环,则先在环里设定一个不动的指针,另一个链表的指针从头开始移动。如果另一个链表的指针能够与环中的指针相遇,则两个链表相交。如果链表中没有环,则判断两个链表的最后一个节点是否相同。若相同,则两个链表相交。
答案:
bool List::isIntersecting(const List & list)
{
bool flag=false;
if(this->checkCycle( ))
{
list_node*p=getJoinPointer( );
list_node*q=list.head;
while(q){
if(q==p){;
flag=true;
break;
}
q=q->next;
}
flag=true;
}
else
{
list_node*p=head;
list_node*q=list.head;
while(p->next)p=p->next;
while(q->next)q=q->next;
if(p==q)flag=true;
else flag=false;
}
Return flag;
}
试题10.若两个链表相交,找出交点(2009年华为校园招聘笔试题)。
分析:求出两个链表的长度a和b,一个指针指向较短链表的头head,另一个指针指向较长链表的第(head+|a?b|)个节点,然后两个指针一起移动,相遇处即为交点。
答案:
list_node*List::intersectNode(const List&list)
{
if(!isIntersecting(list))return NULL;
int a=cnt;
int b=list.cnt;
list_node*p;
list_node*q;
if(a<b){p=list.head;q=head;}
else{p=head; q=list.head;}
a=abs(cnt–list.cnt);
while(p&&a)
{
p=p->next;
a--;
}
while(p&&q)
{
if(q==p)break;
p=p->next;
q=q->next;
}
if(p&&q&&p==q)return p;
return NULL;
}
试题11.实现库函数strcpy(char * des, const char * src)。
答案:注意要点见2.1.2节。
试题12.请说出树的深度优先、广度优先搜索,以及非递归实现的特点。
分析:该题考核的树的两种遍历方法,见2.1.3节。
答案:深度优先搜索是一条分支一条分支进行遍历的,广度优先搜索是一层一层进行遍历的;深度优先的非递归实现利用栈,广度优先的非递归实现利用队列。其具体实现见2.1.3节。
试题13.对于一棵二叉树,如何判断它是否是完全二叉树?
分析:考查二叉树的特性,二叉树的第5条特性是关于完全二叉树的。
答案:如果二叉树的最大节点为i,父节点是i/2,那么它就是完全二叉树。
试题14.一个典型的大型项目通常由众多模块构成,在构建整个系统时,这些模块之间复杂的编译依赖是让人头疼的地方之一。现在就有这样的一个大型项目,它由N(N>1000)个模块构成,每个模块都是可以编译的,但模块之间存在编译依赖,如模块N1依赖N2,即编译N1时,N2必须已经先编译完成,否则N1不能完成编译,但模块之间没有循环依赖的问题。请设计一种快速算法,以完成整个项目的编译构建过程,并给出算法的时间复杂度。
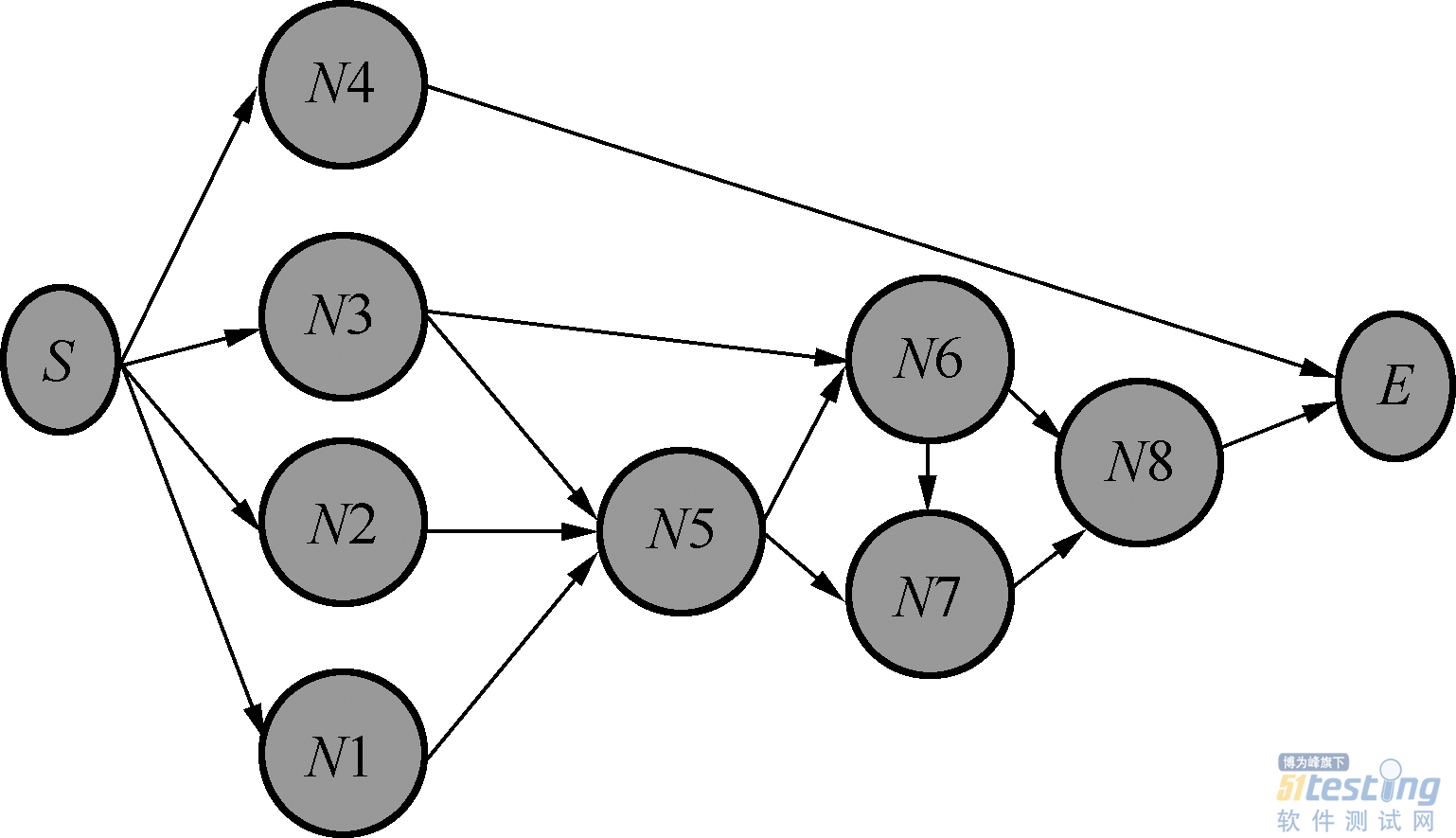
图2.9 N个模块的关系
分析:按照题意,假设N=8,将8个模块的关系画出来(注意,不能循环依赖,一个模块可以依赖多个其他模块,一个模块可以被多个模块依赖),如图2.9所示。其中S表示编译起点,E表示编译终点,箭头指向表示被依赖关系,即N5依赖N1、N2、N3这3个模块。
由此可以看出,合理的编译流程应该是从S出发,当一个节点的前驱节点都编译完成后,该节点才可以编译。该题考查的是图的遍历的灵活运用。
可以考虑从S开始对节点深度进行标号,起始深度为0。使用广度优先搜索算法扫描节点,对未标记过深度的节点,深度加1。对比已标记过的节点深度(已标记深度)和上一个节点的深度加1后的值,取最大值。按照该深度标记完整张图之后,假设最大深度为k,建立大小为k的链表a。再次扫描所有节点,将深度为1的节点链接到a[1],深度为m的节点链接到a[m]。最后,从a[1]编译执行到a[m]。
答案:
{
string modeName;
Int depth=-1;
arrayList <node> nextNodes;
}
Int MaskTask(node PreTask) //利用队列,采用图的广度搜索算法给节点加上深度标记
{ Queue*queue;
Int maxDepth=0;
preTask.depth=0;
queue.push(preTask);
While(!queue.isEmpty())
{
node tmp=queque.pop();
ArrayList <node> nexts=tmp.nextNodes;
For(int i=0;i<nexts.lenths;i++)
{
If(nexts[i].depth==-1)
{
nexts[i].depth=tmp.depth+1;
tmp.push(nexts[i]);
}
Else
{
If((tmp.depth+1)>nexts[i].depth)
{
nexts[i].depth=tmp.depth+1;
tmp.push(nexts[i]);
}
}
maxDepth=nexts[i].depth;
}
Return maxDepth;
}
arraylist SortTask(node PreTask,int maxDepth)//将标记的节点整理排序
{
Queue element;
ArrayList nodelist;
For(int i=0;i<maxDepth;i++)
{
Nodelist.add(new arraylist());
}
Element.push(preTask);
While(!element.isEmpth())
{
Node tmp=element.pop();
Int tmpDepth=tmp.depth;
If(Nodelist[tmpDepth-1].Notexist(tmp))
{
Nodelist[tmpDepth-1].add(tmp);
}
For(int j=0;j<=tmp.nextNodes.length;j++)
{
Element.push(tmp.nextNodes[j]);
}
}
Return nodelist;
}
Void DoCompile( Node PreTask)
{ int depth=MaskTask(Node PreTask);
Arraylist nl=SortTask(Node PreTask,depth);
For(int i=0;i<nl.length;i++)
{ arraylist al=nl[i];
For(int j=0;j<=al.length;j++)
{
Comile(al[j]);//编译节点
}
}
}
通过广度优先搜索算法计算节点深度的时间复杂度为O(n+e),其中n为节点个数,e为边数。扫描完后节点分类的时间复杂度也是O(n+e),编译的时间复杂度为O(n)。因此,整个算法的时间复杂度为O(n)。
试题15.如果有一个大文本文件(保存各种词语),每次搜索都必须检查查询词是否在这个大文件中,请问通过什么方式能够提高查找效率?请讲解所使用的算法。
分析:考查基本数据结构,灵活采取算法处理实际问题的能力,快速编程能力,在给出一定提示的情况下,检查学习能力和知识应用能力。
答案:基本方法是采用哈希签名,提高匹配效率;建立多叉树,保存文件数据,提高查找速度。
较优方法是在上面的基础上,将文本文件转化为key->value的二进制文件,提高文件操作和查找速度。
更优方法是在上面的基础上,开辟内存作为调整缓存,保存高频率查询词,提高整体查找效率,如给出缓存的更新机制。
试题16.函数void log(int, char, long)调用栈的结构是什么样的?
分析:考查函数压栈的顺序、字节对齐等。
答案:按照从右到左的压栈顺序,注意高地址和低地址,压栈时以机器字长为单位且所有参数按字对齐,栈的结构如图2.10所示。

图2.10 栈的结构
试题17.有一份成绩单,只有两个字段,即姓名和成绩,数据量在百万级别。要求用最优的数据存储方式,通过姓名快速查找出成绩。
答案:哈希存储。
试题18.快速排序的平均时间复杂度是多少?最坏时间复杂度是多少?在哪些情况下会出现最坏时间复杂度?
分析:考查排序算法。
答案:快速排序算法的时间复杂度为O(nlog2n),最坏时间复杂度为O(n2),在待排序列正序或者逆序的情况下会出现最坏时间复杂度。
试题19.请用你熟悉的任意语言实现一个冒泡算法,并写出它的时间复杂度。
分析:考查基本算法知识。
答案:见2.1.5节。
试题20.栈和队列的共同特点是什么?
分析:考查栈和队列的概念。
答案:栈和队列都只能在端点处插入与删除元素。
试题21.栈通常采用的两种存储结构是什么?
分析:栈属于线性表的一种,线性表的存储结构有两种。
答案:顺序存储结构和链式存储结构。
试题22.下列关于栈的叙述正确的是( )。
A.栈具有非线性结构B.栈具有树状结构
C.栈具有先进先出的特征D.栈具有后进先出的特征
分析:考查栈的概念。
答案:D。
试题23.链表不具有的特点是( )。
A.不必事先估计存储空间B.可随机访问任意元素
C.插入和删除操作中不需要移动元素D.所需空间与线性表长度成正比
分析:该题考查链表的特点,B属于顺序存储结构的特点。
答案:B。
试题24.链表的优点是什么?
分析:考查链表的特点。
答案:便于插入和删除操作,动态申请空间。
试题25.线性表若采用链式存储,要求内存中可用的存储单元地址( )。
A.连续B.部分地址连续
C.一定不连续D.连续、不连续都可以
分析:考查链表的特点。
答案:D。
试题26.在深度为5的满二叉树中,叶子节点的个数是多少?
分析:考查二叉树的特性及满二叉树的概念。满二叉树中叶子节点的个数为。注意,不要按照完全二叉树计算。
答案:31。
试题27.已知二叉树后序遍历结果是dabec,中序遍历结果是debac,它的前序遍历结果是什么?
分析:考查二叉树的遍历方式,2.1.3节中有讲解,先画出二叉树,再遍历。
答案:cedba。
试题28.已知二叉树前序遍历结果与中序遍历结果分别是ABDEGCFH和DBGEACHF,则该二叉树的后序遍历结果是什么?
分析:同本节的试题27。
答案:DGEBHFCA。
试题29.字符串的长度定义是什么?
分析:考查串的概念。
答案:字符串中所包含的字符个数。
试题30.判断两个数组中是否存在相同的数字。给定两个排好序的数组,怎样高效判断这两组数中有相同的数字?
分析:首先考虑时间复杂度为O(nlog2n)的算法。任意挑选一个数组,遍历该数组的所有元素。在遍历过程中,在另一个数组中对第1个数组中的每个元素进行二叉树搜索。还可以采用时间复杂度为O(n)的算法,因为两个数组都是排好序的,所以只需要遍历一次即可。
答案:首先设置两个索引,分别初始化为两个数组的起始地址,然后依次向前推进。推进的规则是比较两个数组中的数字,小的数组的索引向前推进一步,直到任何一个数组的索引到达数组末尾。若此时还没有碰到相同的数字,则说明数组中没有相同的数字。
试题31.在需要经常查找节点的前驱和后继的场合中,使用( )比较合适。
A.单链表B.双链表C.顺序链表D.循环链表
分析:考查链表的运用。
答案:B。
试题32.对长度为n的线性表进行顺序查找,在最坏情况下所需要的比较次数是多少?
分析:考查查找算法。
答案:最坏情况下比较n次。
试题33.最简单的交换排序方法是什么?
答案:冒泡排序。
试题34.线性表的长度为n,在最坏情况下,冒泡排序需要的比较次数是多少?
分析:考查冒泡排序。
答案:n(n?1)/2。
试题35.在待排序元素基本有序的前提下,效率最高的排序方法是什么?
答案:冒泡排序。
试题36.在最坏情况下,时间复杂度最小的排序方法是什么?
答案:堆排序。
试题37.堆排序法属于什么排序?
答案:选择排序。
试题38.对N个数进行快速排序算法的平均时间复杂度是多少?
分析:见2.1.5节中表2.1。
答案:O(Nlog2N)。
试题39.把整数转换成字符串。
分析:2.1.2节中有算法描述。
答案:
/*把整数转化成字符串*/
char *IntToStr(int num,char str[])
{
int i=0,j=0;
char temp[100];
while(num)
{
temp[i]=num%10+'0';
num=num/10;
i++;
}
temp[i]=0; //字符串结束标志
i=i-1; //回到temp中最后一个有意义的数字
while(i>=0)
{
str[j]=temp[i];
i--;
j++;
}
str[j]=0; //字符串结束标志
return str;
}
试题40.判断以下8位二进制数(补码形式)的加法运算是否会产生溢出。
(a)11000010+00111111
(b)00000010+00111111
(c)11000010+11111111
(d)00000010+11111111
分析:手动进行计算,判断依据是正数+正数=负数,负数+负数=正数。
答案:
(a)11000010+00111111表示负数+正数,不可能溢出。
(b)00000010+00111111=01000001,正数+正数=正数,没有溢出。
(c)11000010+11111111=11000001,负数+负数=负数,没有溢出。
(d)00000010+11111111表示正数+负数,不可能溢出。
试题41.在不借助第3个变量的情况下,互换两个int类型的变量X、Y的值,用任何自己熟悉的编程语言完成。
分析:思路为X=X+Y,Y=X?Y,X=X?Y。
答案:略。
试题42.请问以下代码有什么问题?
int main()
{
char a;
char *str=&a;
strcpy(str,"hello");
printf(str);
return 0;
}
答案:没有为str分配内存空间,因此将发生异常。问题出在将一个字符串复制进一个字符变量指针所指地址。虽然以上代码可以正确输出结果,但会因为越界进行内存读写而导致程序崩溃。
版权声明:51Testing软件测试网获得人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。












