

对于以内容为主的软件来说,本土化和国际化必不可少。有的时候,一个词语要翻译成10几个国家语言。
我负责的一个产品就要翻译成16国文字。
对于我们这种土鳖来说,能看懂英文就不错了。
通常的做法是,将词语,或者句子,给第三方翻译公司翻译。然后存入到数据库,生成接口来调用。每个词语或者句子有个ID,请求某个语种,就会把对应的语言翻译传回来。
那么问题来了:有些词语,某个语种翻译了一些,一些没有翻译,用户体验很不好。
怎么把那些漏网之鱼捞出来?测试起来很困难,调用接口,把翻译全打出来,人工去看哪些没有翻译。姑且不论翻译对错与否。这样效率很低。
python 有个langid库,能检测64种语言。
可以先用pandas将翻译全弄出来,然后检测哪些没有翻译的。
import sys
import requests
import langid
import numpy as np
import pandas as pd
LANGUAGES = [‘ar’, ‘de’, ‘en’, ‘es’, ‘fr’, ‘it’, ‘ja-JP’, ‘ko-KR’, ‘pt-BR’, ‘ru’, ‘th’, ‘tr-TR’, ‘zh-cn’, ‘zh-HK’, ‘zh-TW’]
ID = [‘699126’, ‘699124’, ‘669751’, ‘647306’, ‘697256’, ‘647306’]
url = “http://{}.query?q=blurb!{}&c=culturecode={}“
list_obj = []
class Translate():
def get_translated_string(self, blurb_id, language_code):
response = requests.post(url.format(host, blurb_id, language_code))
value = (response.json())[0][‘translation’].strip()
return value
def check_language(self, target, language):
lineTuple = langid.classify(target) # 调用langid来对该行进行语言检测
if “-“ in language:
language = language.split(“-“)[0]
if lineTuple[0] != language:
return False
else:
return True
结果如下:

检测下来,效果还不错。
谷歌翻译也日渐智能,但目前还是收费状态。
本文就尝试用免费的百度API, 来看看翻译效果。
首先要去申请一个translate api key.
然后敲代码:
import requests
import hashlib
import random
import json
appid = ‘your id’
secretKey = ‘your key’
myurl = ‘/api/trans/vip/translate’
host = ‘http://api.fanyi.baidu.com‘
fromLang = ‘auto’
toLang = ‘en’
salt = random.randint(32768, 65536)
def md5hex(word):
sign = appid + word + str(salt) + secretKey
m1 = hashlib.md5()
return m1.hexdigest()
def trans(word, sign, fr, to):
word_num = len(word)
if word_num > 1600:
print(“over 1600”)
else:
url = myurl + ‘?appid=’ + appid + ‘&q=’ + word + ‘&from=’ + fr + ‘&to=’ + to + ‘&salt=’ + str(
salt) + ‘&sign=’ + sign
try:
result = requests.post(host + url)
if result.status_code == 200:
trans_data = json.loads(result.text)
trans_data = trans_data['trans_result'][0]['dst']
print(trans_data)
else:
print("please check you url")
except:
print("error")
if name == ‘main‘:
info = input(“please input you word!”)
md5_info = md5hex(info)
trans(info, md5_info,fromLang,toLang)
支持多种语言。Snake尝试了下自己能看懂的:简体,繁体,粤语,文言文,英文的测试。
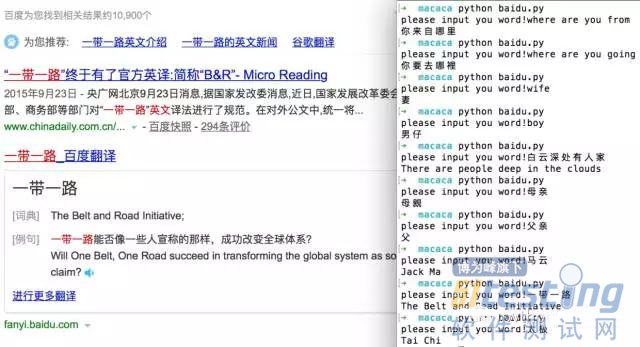
诗句也翻译出来了,看起来似乎还可以。
最新的热词,跟搜索结果一样,应该是用的同一套吧。
这样一个一个敲太累,准备几个词,一次性翻译出多种语言来。
语种:zh 中文 en 英语 jp 日语 kor 韩语 fra 法语 spa 西班牙语 th 泰语 ara 阿拉伯语 ru 俄语 pt 葡萄牙语 de 德语 it 意大利语
语言:早上好,欢迎,谢谢,huge blessings, 和谐社会,且行且珍惜,foodie, clown, 白日依山尽。
加几行代码:
languages = [‘zh’, ‘en’, ‘jp’, ‘kor’, ‘fra’, ‘spa’, ‘th’, ‘ara’, ‘ru’, ‘pt’, ‘de’, ‘it’]
words = [‘早上好’, ‘欢迎’, ‘谢谢’, ‘huge blessings’, ‘和谐社会’, ‘且行且珍惜’, ‘foodie’, ‘clown’, ‘白日依山尽’]
translated = (trans(x, md5hex(x), fromLang, y) for x in words for y in languages)
translated_list = np.array(list(translated)).reshape(len(words), len(languages))
translated_dataframe = pd.DataFrame(translated_list,columns=languages)
writer = pd.ExcelWriter(‘translated.xlsx’)
translated_dataframe.to_excel(writer,’translate’)
writer.save()
结果如下:
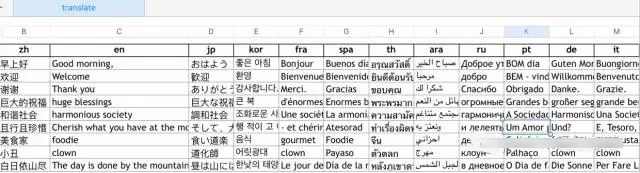
看起来似乎效果还可以。
尝试过翻译故事,典故。字数越多,文化背景啥因素加入。翻译出来效果大打折扣。短句子还凑合。
如国民老公的这句:“你的想法和评论改变不了我的现状,所以,随便你说什么,我也无需证明给你看。”
翻译出来的效果就是:“Your thoughts and comments don’t change my situation, so whatever you say, I don’t have to prove it to you.”
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












