

ЁЁЁЁПЊОжвЛеХЭМЃК
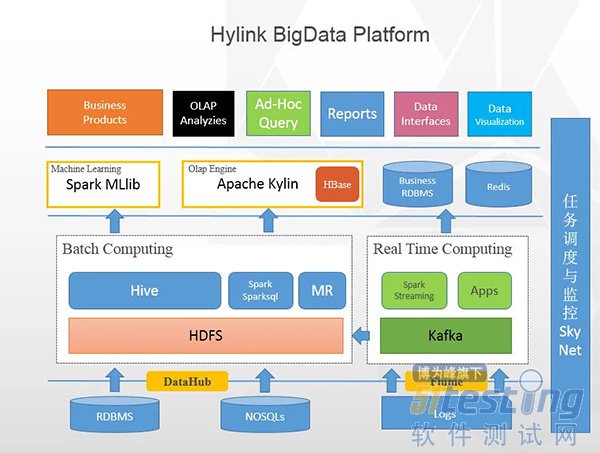
ЁЁЁЁетЪЧФГЙЋЫОЪЙгУЕФДѓЪ§ОнЦНЬЈМмЙЙЭМЃЌДѓВПЗжЙЋЫОгІИУЖМВюВЛЖрЁЃ
ЁЁЁЁДгетеХДѓЪ§ОнЕФећЬхМмЙЙЭМЩЯПДРДЃЌДѓЪ§ОнЕФКЫаФВугІИУЪЧЃКЪ§ОнВЩМЏВуЁЂЪ§ОнДцДЂгыЗжЮіВуЁЂЪ§ОнЙВЯэВуЁЂЪ§ОнгІгУВуЃЌПЩФмНаЗЈгаЫљВЛЭЌЃЌБОжЪЩЯЕФНЧЩЋЖМДѓЭЌаЁвьЁЃ
ЁЁЁЁЫљвдЮвЯТУцОЭАДетеХМмЙЙЭМЩЯЕФЯпЫїЃЌТ§Т§РДЦЪЮівЛЯТЃЌДѓЪ§ОнЕФКЫаФММЪѕЖМАќРЈЪВУДЁЃ
ЁЁЁЁЁЊ01ЁЊ. ДѓЪ§ОнВЩМЏ
ЁЁЁЁЪ§ОнВЩМЏЕФШЮЮёОЭЪЧАбЪ§ОнДгИїжжЪ§ОндДжаВЩМЏКЭДцДЂЕНЪ§ОнДцДЂЩЯЃЌЦкМфгаПЩФмЛсзівЛаЉМђЕЅЕФЧхЯДЁЃ
ЁЁЁЁЪ§ОндДЕФжжРрБШНЯЖрЃК
ЁЁЁЁ1ЁЂЭјеОШежО
ЁЁЁЁзїЮЊЛЅСЊЭјаавЕЃЌЭјеОШежОеМЕФЗнЖюзюДѓЃЌЭјеОШежОДцДЂдкЖрЬЈЭјеОШежОЗўЮёЦїЩЯЃЌвЛАуЪЧдкУПЬЈЭјеОШежОЗўЮёЦїЩЯВПЪ№flume agentЃЌЪЕЪБЕФЪеМЏЭјеОШежОВЂДцДЂЕНHDFSЩЯЁЃ
ЁЁЁЁ2ЁЂвЕЮёЪ§ОнПт
ЁЁЁЁвЕЮёЪ§ОнПтЕФжжРрвВЪЧЖржжЖрбљЃЌгаMysqlЁЂOracleЁЂSqlServerЕШЃЌетЪБКђЃЌЮвУЧЦШЧаЕФашвЊвЛжжФмДгИїжжЪ§ОнПтжаНЋЪ§ОнЭЌВНЕНHDFSЩЯЕФЙЄОпЃЌSqoopЪЧвЛжжЃЌЕЋЪЧSqoopЬЋЙ§ЗБжиЃЌЖјЧвВЛЙмЪ§ОнСПДѓаЁЃЌЖМашвЊЦєЖЏMapReduceРДжДааЃЌЖјЧвашвЊHadoopМЏШКЕФУПЬЈЛњЦїЖМФмЗУЮЪвЕЮёЪ§ОнПтЃЛгІЖдДЫГЁОАЃЌЬдБІПЊдДЕФDataXЃЌЪЧвЛИіКмКУЕФНтОіЗНАИЃЌгазЪдДЕФЛАЃЌПЩвдЛљгкDataXжЎЩЯзіЖўДЮПЊЗЂЃЌОЭФмЗЧГЃКУЕФНтОіЁЃ
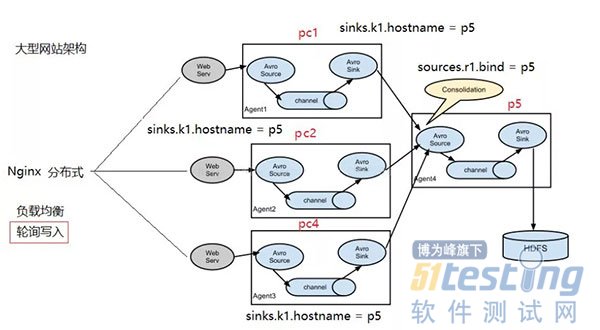
ЁЁЁЁЕБШЛЃЌFlumeЭЈЙ§ХфжУгыПЊЗЂЃЌвВПЩвдЪЕЪБЕФДгЪ§ОнПтжаЭЌВНЪ§ОнЕНHDFSЁЃ
ЁЁЁЁ3ЁЂРДздгкFtp/HttpЕФЪ§ОндД
ЁЁЁЁгаПЩФмвЛаЉКЯзїЛяАщЬсЙЉЕФЪ§ОнЃЌашвЊЭЈЙ§Ftp/HttpЕШЖЈЪБЛёШЁЃЌDataXвВПЩвдТњзуИУашЧѓЁЃ
ЁЁЁЁ4ЁЂЦфЫћЪ§ОндД
ЁЁЁЁБШШчвЛаЉЪжЙЄТМШыЕФЪ§ОнЃЌжЛашвЊЬсЙЉвЛИіНгПкЛђаЁГЬађЃЌМДПЩЭъГЩЁЃ
ЁЁЁЁЁЊ02ЁЊ. ДѓЪ§ОнДцДЂгыЗжЮі
ЁЁЁЁЮугЙжУвЩЃЌHDFSЪЧДѓЪ§ОнЛЗОГЯТЪ§ОнВжПт/Ъ§ОнЦНЬЈзюЭъУРЕФЪ§ОнДцДЂНтОіЗНАИЁЃ
ЁЁЁЁРыЯпЪ§ОнЗжЮігыМЦЫуЃЌвВОЭЪЧЖдЪЕЪБадвЊЧѓВЛИпЕФВПЗжЃЌдкБЪепПДРДЃЌHiveЛЙЪЧЪзЕБЦфГхЕФбЁдёЃЌЗсИЛЕФЪ§ОнРраЭЁЂФкжУКЏЪ§ЃЛбЙЫѕБШЗЧГЃИпЕФORCЮФМўДцДЂИёЪНЃЛЗЧГЃЗНБуЕФSQLжЇГжЃЌЪЙЕУHiveдкЛљгкНсЙЙЛЏЪ§ОнЩЯЕФЭГМЦЗжЮідЖдЖБШMapReduceвЊИпаЇЕФЖрЃЌвЛОфSQLПЩвдЭъГЩЕФашЧѓЃЌПЊЗЂMRПЩФмашвЊЩЯАйааДњТыЁЃ
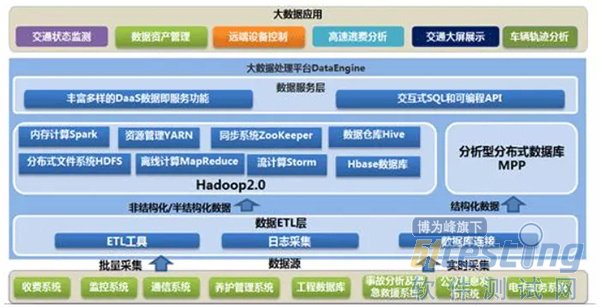
ЁЁЁЁЕБШЛЃЌЪЙгУHadoopПђМмздШЛЖјШЛвВЬсЙЉСЫMapReduceНгПкЃЌШчЙћецЕФКмРжвтПЊЗЂJavaЃЌЛђепЖдSQLВЛЪьЃЌФЧУДвВПЩвдЪЙгУMapReduceРДзіЗжЮігыМЦЫуЃЛ
ЁЁЁЁSparkЪЧетСНФъЗЧГЃЛ№ЕФЃЌОЙ§ЪЕМљЃЌЫќЕФадФмЕФШЗБШMapReduceвЊКУКмЖрЃЌЖјЧвКЭHiveЁЂYarnНсКЯЕФдНРДдНКУЃЌвђДЫЃЌБиаыжЇГжЪЙгУSparkКЭSparkSQLРДзіЗжЮіКЭМЦЫуЁЃвђЮЊвбОгаHadoop YarnЃЌЪЙгУSparkЦфЪЕЪЧЗЧГЃШнвзЕФЃЌВЛгУЕЅЖРВПЪ№SparkМЏШКЁЃ
ЁЁЁЁЁЊ03ЁЊ. ДѓЪ§ОнЙВЯэ
ЁЁЁЁетРяЕФЪ§ОнЙВЯэЃЌЦфЪЕжИЕФЪЧЧАУцЪ§ОнЗжЮігыМЦЫуКѓЕФНсЙћДцЗХЕФЕиЗНЃЌЦфЪЕОЭЪЧЙиЯЕаЭЪ§ОнПтКЭNOSQLЪ§ОнПтЁЃ
ЁЁЁЁЧАУцЪЙгУHiveЁЂMRЁЂSparkЁЂSparkSQLЗжЮіКЭМЦЫуЕФНсЙћЃЌЛЙЪЧдкHDFSЩЯЃЌЕЋДѓЖрвЕЮёКЭгІгУВЛПЩФмжБНгДгHDFSЩЯЛёШЁЪ§ОнЃЌФЧУДОЭашвЊвЛИіЪ§ОнЙВЯэЕФЕиЗНЃЌЪЙЕУИївЕЮёКЭВњЦЗФмЗНБуЕФЛёШЁЪ§ОнЃЛКЭЪ§ОнВЩМЏВуЕНHDFSИеКУЯрЗДЃЌетРяашвЊвЛИіДгHDFSНЋЪ§ОнЭЌВНжСЦфЫћФПБъЪ§ОндДЕФЙЄОпЃЌЭЌбљЃЌDataXвВПЩвдТњзуЁЃ
ЁЁЁЁСэЭтЃЌвЛаЉЪЕЪБМЦЫуЕФНсЙћЪ§ОнПЩФмгЩЪЕЪБМЦЫуФЃПщжБНгаДШыЪ§ОнЙВЯэЁЃ
ЁЁЁЁЁЊ04ЁЊ. ДѓЪ§ОнгІгУ
ЁЁЁЁ1ЁЂвЕЮёВњЦЗЃЈCRMЁЂERPЕШЃЉ
ЁЁЁЁвЕЮёВњЦЗЫљЪЙгУЕФЪ§ОнЃЌвбОДцдкгкЪ§ОнЙВЯэВуЃЌжБНгДгЪ§ОнЙВЯэВуЗУЮЪМДПЩЁЃ
ЁЁЁЁ2ЁЂБЈБэЃЈFineReportЁЂвЕЮёБЈБэЃЉ
ЁЁЁЁЭЌвЕЮёВњЦЗЃЌБЈБэЫљЪЙгУЕФЪ§ОнЃЌвЛАувВЪЧвбОЭГМЦЛузмКУЕФЃЌДцЗХгкЪ§ОнЙВЯэВуЁЃ
ЁЁЁЁ3ЁЂМДЯЏВщбЏ
ЁЁЁЁМДЯЏВщбЏЕФгУЛЇгаКмЖрЃЌгаПЩФмЪЧЪ§ОнПЊЗЂШЫдБЁЂЭјеОКЭВњЦЗдЫгЊШЫдБЁЂЪ§ОнЗжЮіШЫдБЁЂЩѕжСЪЧВПУХРЯДѓЃЌЫћУЧЖМгаМДЯЏВщбЏЪ§ОнЕФашЧѓЁЃ
ЁЁЁЁетжжМДЯЏВщбЏЭЈГЃЪЧЯжгаЕФБЈБэКЭЪ§ОнЙВЯэВуЕФЪ§ОнВЂВЛФмТњзуЫћУЧЕФашЧѓЃЌашвЊДгЪ§ОнДцДЂВужБНгВщбЏЁЃ
ЁЁЁЁМДЯЏВщбЏвЛАуЪЧЭЈЙ§SQLЭъГЩЃЌзюДѓЕФФбЖШдкгкЯьгІЫйЖШЩЯЃЌЪЙгУHiveгаЕуТ§ЃЌПЩвдгУSparkSQLЃЌЫќЕФЯьгІЫйЖШНЯHiveПьКмЖрЃЌЖјЧвФмКмКУЕФгыHiveМцШнЁЃ
ЁЁЁЁЕБШЛЃЌФувВПЩвдЪЙгУImpalaЃЌШчЙћВЛдкКѕЦНЬЈжадйЖрвЛИіПђМмЕФЛАЁЃ
ЁЁЁЁ4ЁЂOLAP
ЁЁЁЁФПЧАЃЌКмЖрЕФOLAPЙЄОпВЛФмКмКУЕФжЇГжДгHDFSЩЯжБНгЛёШЁЪ§ОнЃЌЖМЪЧЭЈЙ§НЋашвЊЕФЪ§ОнЭЌВНЕНЙиЯЕаЭЪ§ОнПтжазіOLAPЃЌЕЋШчЙћЪ§ОнСПОоДѓЕФЛАЃЌЙиЯЕаЭЪ§ОнПтЯдШЛВЛааЁЃ
ЁЁЁЁетЪБКђЃЌашвЊзіЯргІЕФПЊЗЂЃЌДгHDFSЛђепHBaseжаЛёШЁЪ§ОнЃЌЭъГЩOLAPЕФЙІФмЃЛБШШчЃКИљОнгУЛЇдкНчУцЩЯбЁдёЕФВЛЖЈЕФЮЌЖШКЭжИБъЃЌЭЈЙ§ПЊЗЂНгПкЃЌДгHBaseжаЛёШЁЪ§ОнРДеЙЪОЁЃ
ЁЁЁЁ5ЁЂЦфЫќЪ§ОнНгПк
ЁЁЁЁетжжНгПкгаЭЈгУЕФЃЌгаЖЈжЦЕФЁЃБШШчЃКвЛИіДгRedisжаЛёШЁгУЛЇЪєадЕФНгПкЪЧЭЈгУЕФЃЌЫљгаЕФвЕЮёЖМПЩвдЕїгУетИіНгПкРДЛёШЁгУЛЇЪєадЁЃ
ЁЁЁЁЁЊ05ЁЊ. ЪЕЪБЪ§ОнМЦЫу
ЁЁЁЁЯждквЕЮёЖдЪ§ОнВжПтЪЕЪБадЕФашЧѓдНРДдНЖрЃЌБШШчЃКЪЕЪБЕФСЫНтЭјеОЕФећЬхСїСПЃЛЪЕЪБЕФЛёШЁвЛИіЙуИцЕФЦиЙтКЭЕуЛїЃЛдкКЃСПЪ§ОнЯТЃЌвРППДЋЭГЪ§ОнПтКЭДЋЭГЪЕЯжЗНЗЈЛљБОЭъГЩВЛСЫЃЌашвЊЕФЪЧвЛжжЗжВМЪНЕФЁЂИпЭЬЭТСПЕФЁЂбгЪБЕЭЕФЁЂИпПЩППЕФЪЕЪБМЦЫуПђМмЃЛStormдкетПщЪЧБШНЯГЩЪьСЫЃЌЕЋЮвбЁдёSpark StreamingЃЌдвђКмМђЕЅЃЌВЛЯыЖрв§ШывЛИіПђМмЕНЦНЬЈжаЃЌСэЭтЃЌSpark StreamingБШStormбгЪБадИпФЧУДвЛЕуЕуЃЌФЧЖдгкЮвУЧЕФашвЊПЩвдКіТдЁЃ
ЁЁЁЁЮвУЧФПЧАЪЙгУSpark StreamingЪЕЯжСЫЪЕЪБЕФЭјеОСїСПЭГМЦЁЂЪЕЪБЕФЙуИцаЇЙћЭГМЦСНПщЙІФмЁЃ
ЁЁЁЁзіЗЈвВКмМђЕЅЃЌгЩFlumeдкЧАЖЫШежОЗўЮёЦїЩЯЪеМЏЭјеОШежОКЭЙуИцШежОЃЌЪЕЪБЕФЗЂЫЭИјSpark StreamingЃЌгЩSpark StreamingЭъГЩЭГМЦЃЌНЋЪ§ОнДцДЂжСRedisЃЌвЕЮёЭЈЙ§ЗУЮЪRedisЪЕЪБЛёШЁЁЃ
ЁЁЁЁЁЊ06ЁЊ. ШЮЮёЕїЖШгыМрПи
ЁЁЁЁдкЪ§ОнВжПт/Ъ§ОнЦНЬЈжаЃЌгаИїжжИїбљЗЧГЃЖрЕФГЬађКЭШЮЮёЃЌБШШчЃКЪ§ОнВЩМЏШЮЮёЁЂЪ§ОнЭЌВНШЮЮёЁЂЪ§ОнЗжЮіШЮЮёЕШЁЃ
ЁЁЁЁетаЉШЮЮёГ§СЫЖЈЪБЕїЖШЃЌЛЙДцдкЗЧГЃИДдгЕФШЮЮёвРРЕЙиЯЕЃЌБШШчЃКЪ§ОнЗжЮіШЮЮёБиаыЕШЯргІЕФЪ§ОнВЩМЏШЮЮёЭъГЩКѓВХФмПЊЪМЃЛЪ§ОнЭЌВНШЮЮёашвЊЕШЪ§ОнЗжЮіШЮЮёЭъГЩКѓВХФмПЊЪМЁЃ
ЁЁЁЁетОЭашвЊвЛИіЗЧГЃЭъЩЦЕФШЮЮёЕїЖШгыМрПиЯЕЭГЃЌЫќзїЮЊЪ§ОнВжПт/Ъ§ОнЦНЬЈЕФжаЪрЃЌИКд№ЕїЖШКЭМрПиЫљгаШЮЮёЕФЗжХфгыдЫааЁЃ
ЁЁЁЁБОЮФФкШнВЛгУгкЩЬвЕФПЕФЃЌШчЩцМАжЊЪЖВњШЈЮЪЬтЃЌЧыШЈРћШЫСЊЯЕ51TestingаЁБр(021-64471599-8017)ЃЌЮвУЧНЋСЂМДДІРэ












