

1.简介
上大学的时候,第一次听同学说网页爬虫,当时比较幼稚和懵懂,觉得就是几只电子虫子爬在网页上在抓取东西。后来又听说写代码可以实现网页爬虫,宏哥感觉高大上,后来工作又听说,有的公司做爬虫被抓的新闻等等。一直以来,爬虫似乎都是写代码去实现的,今天宏哥心血来潮,试一下能不能不写代码实现网页爬虫了。因此今天文章的主题就是介绍一下 Jmeter 如何实现一个网页爬虫!这里宏哥以爬取博客园首页文章为例实战一下。
2.爬虫原理
Jmeter 的爬虫原理其实很简单,就是对网页提交一个请求,然后把返回的所有 href 提取出来,利用 ForEach 控制器去实现 url 遍历。这样解释是不是很清晰?下面宏哥就来简单介绍一下如何操作。
3.小试牛刀
1)首先我们根据爬虫原理需要对网页提交一个请求,就拿博客园来举例子实战一下吧!我们向博客园发起一个请求,如下图所示:

2)察看结果树,观察一下返回值可以发现中间有很多 href 标签 + 文字标题的 url,如下图所示:

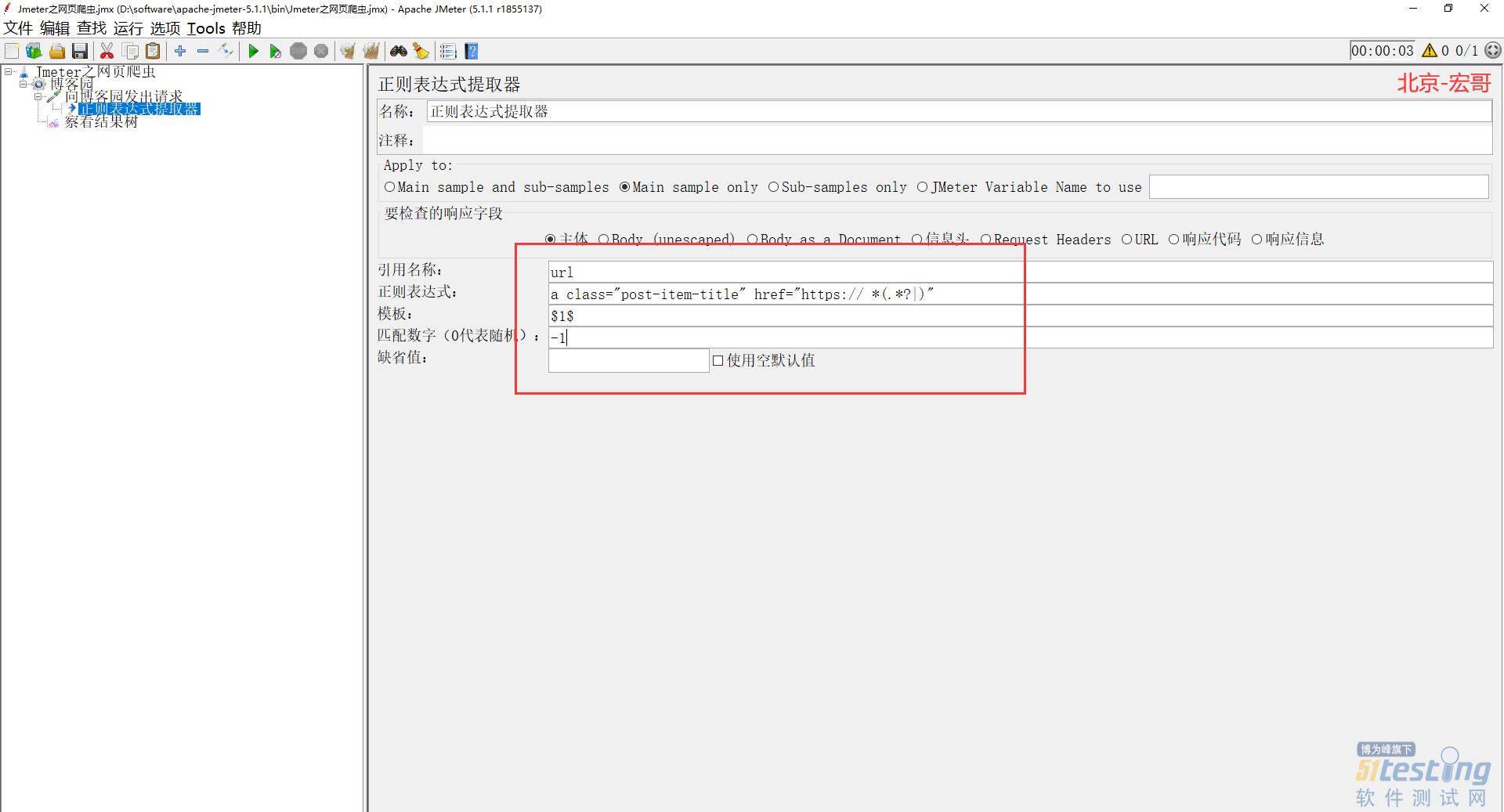
3)宏哥现在需要把这些 url 提取出来,利用强大的正则表达式!如下图所示:
4)从上图可以看出,宏哥已经把需要的东西提取到了,现在宏哥添加一个正则表达式提取器,记得匹配数字填-1,意思就是把所有合适的 url 都取出来,如下图所示:

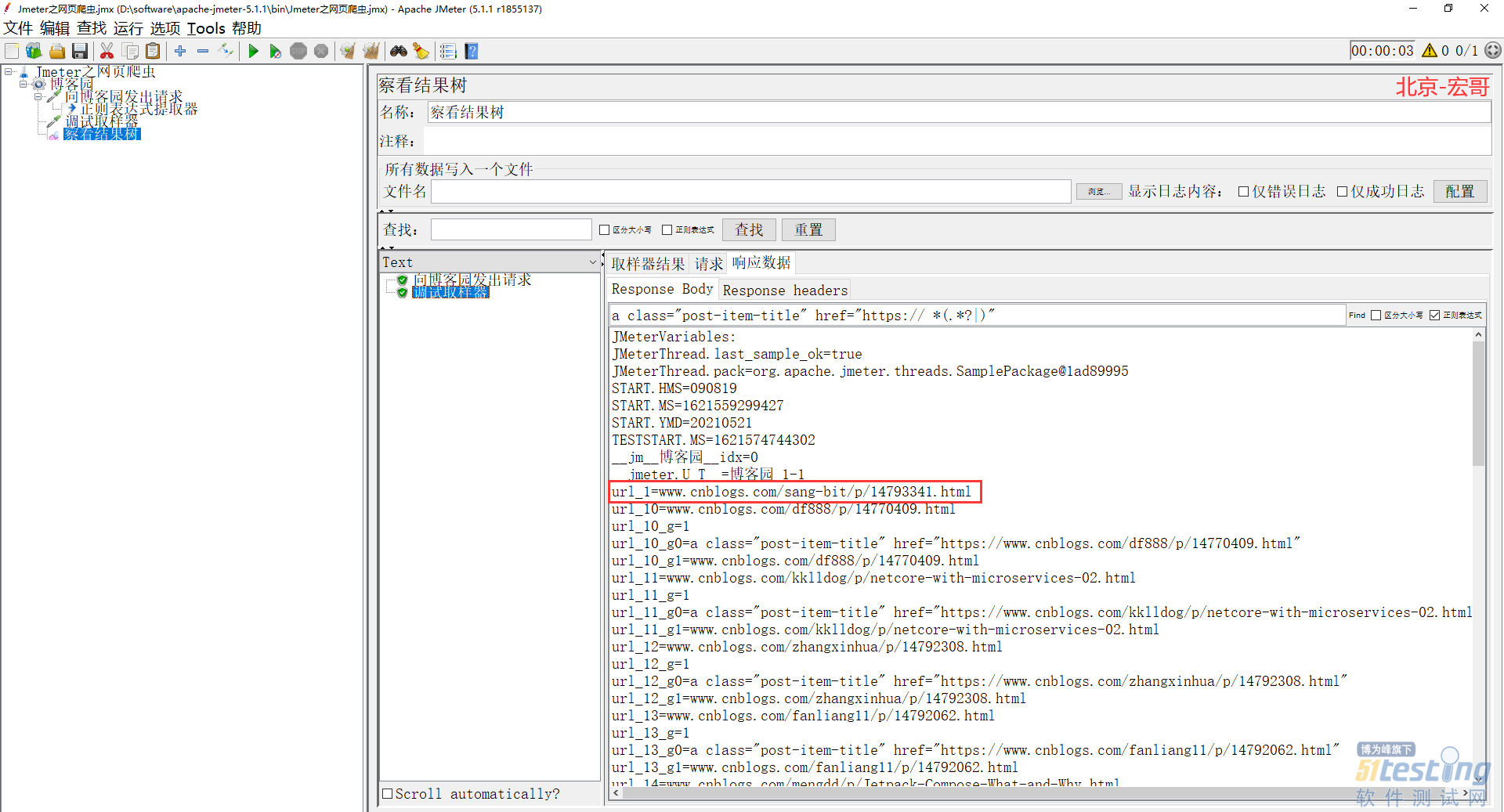
5)然后,宏哥加一个 debug 取样器,运行jmeter,查看一下是否真的取出来了我们想要的东西,如下图所示:
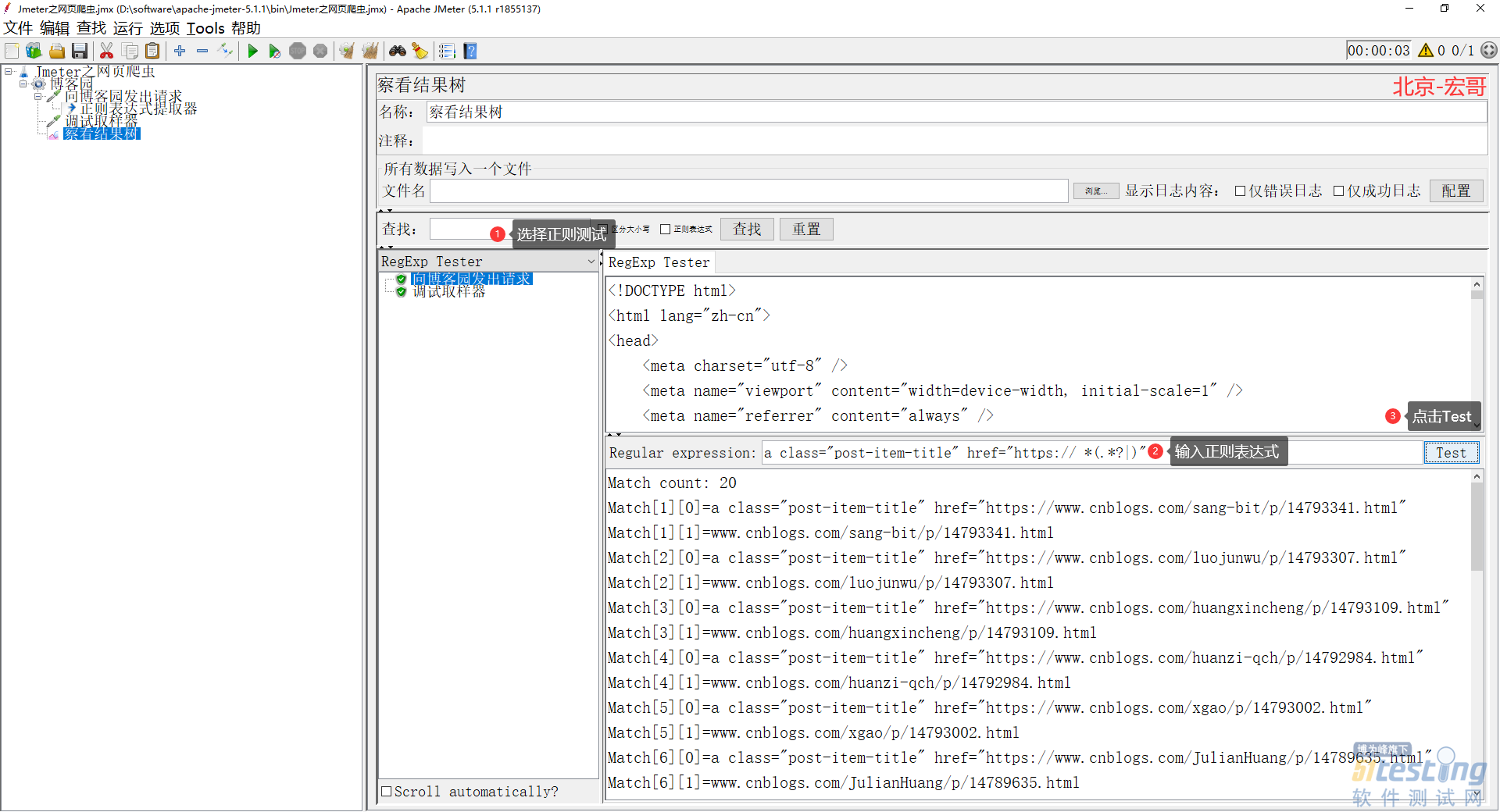
6)又或者我们在结果里面直接利用正则匹配一下,可以看到很多网页链接都被取出来了,如下图所示:
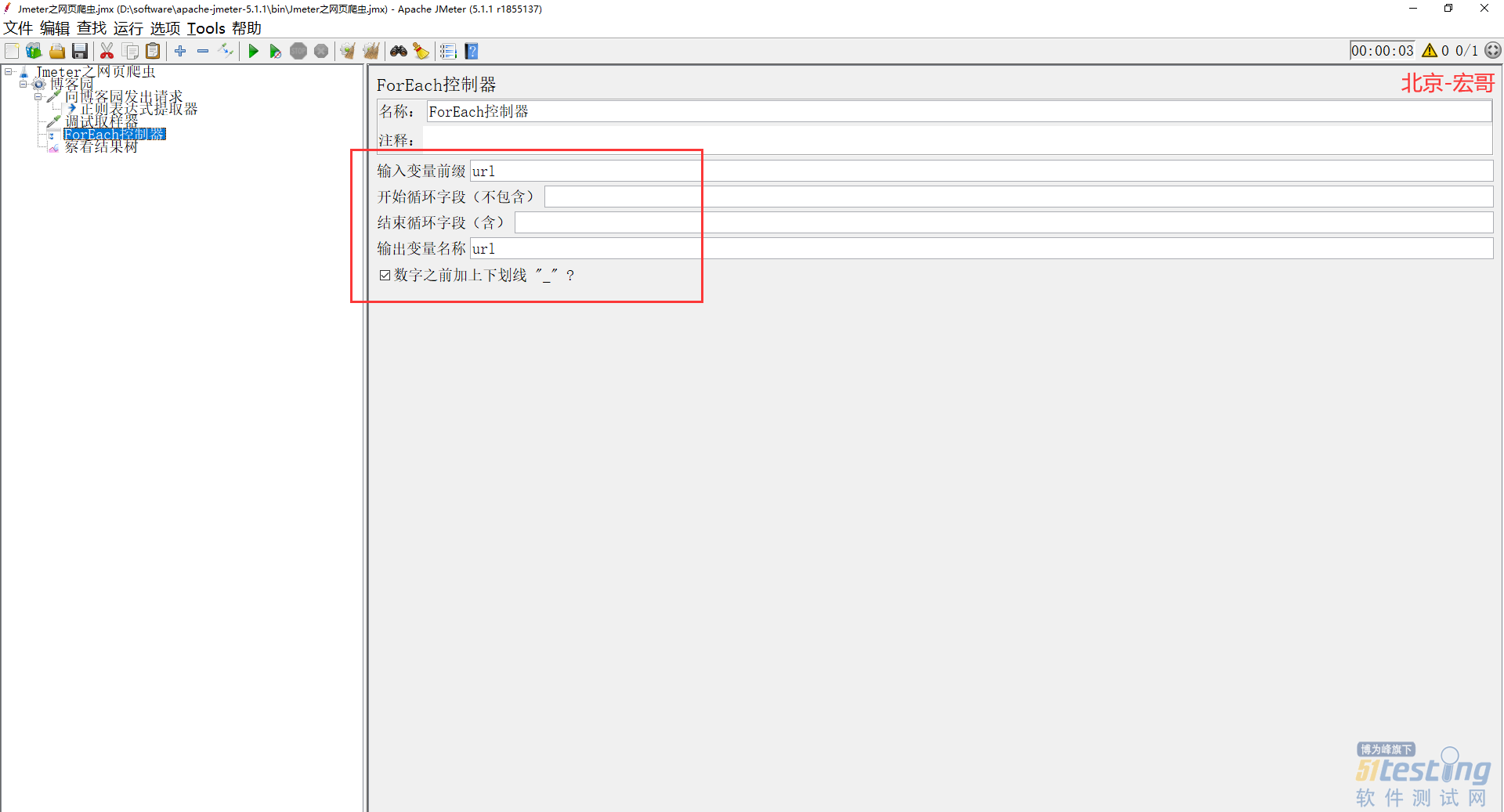
7)接下来我们需要动用到 ForEach 控制器了,利用这个控制器对所有取出来的 url 进行遍历触发。记得在控制器里面填入变量名称,也就是刚刚正则表达式里面的变量名,如下图所示:
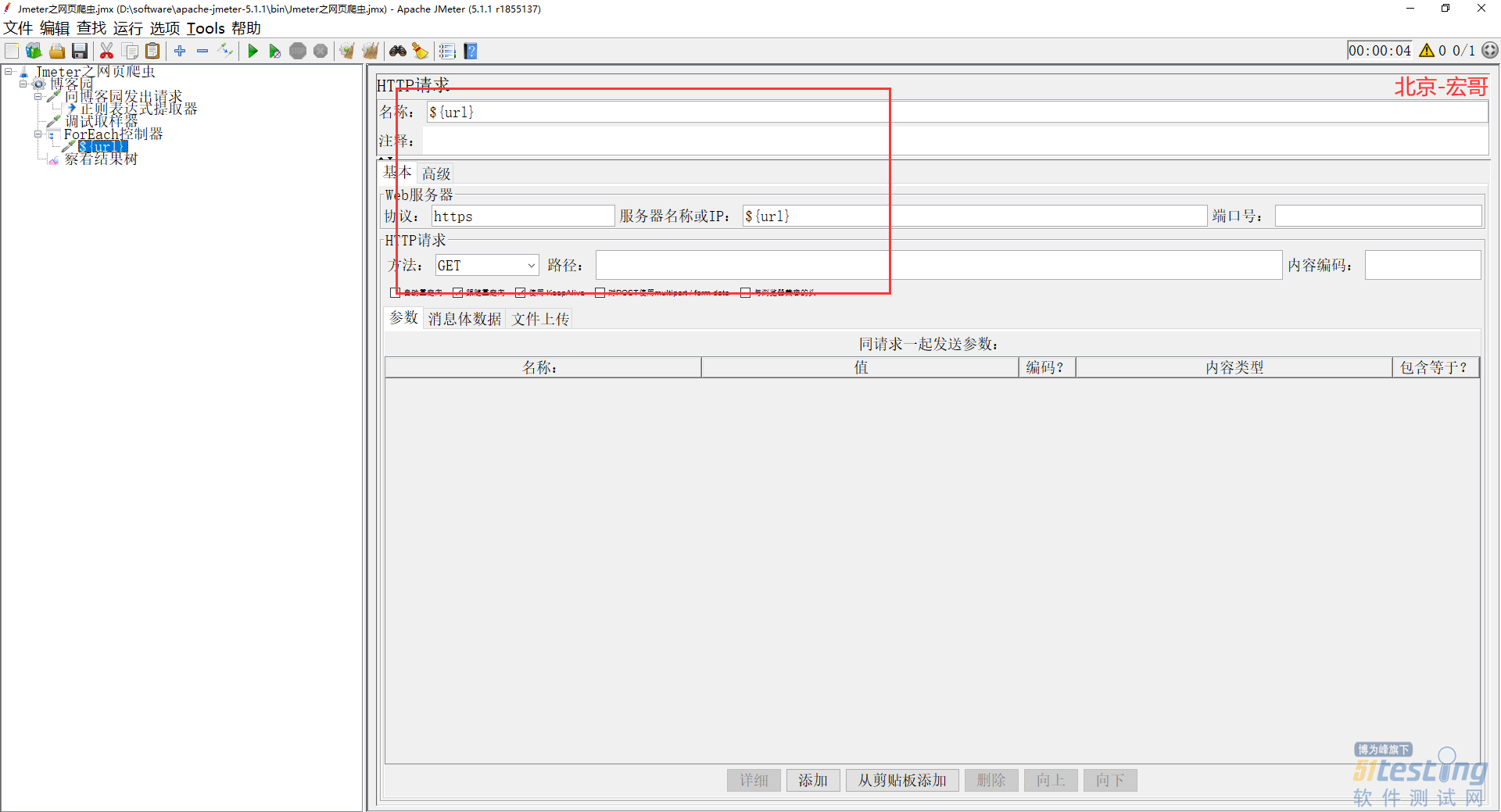
8)在 ForEach 控制器下面再添加一个 http 请求,利用它去执行请求触发,如下图所示:
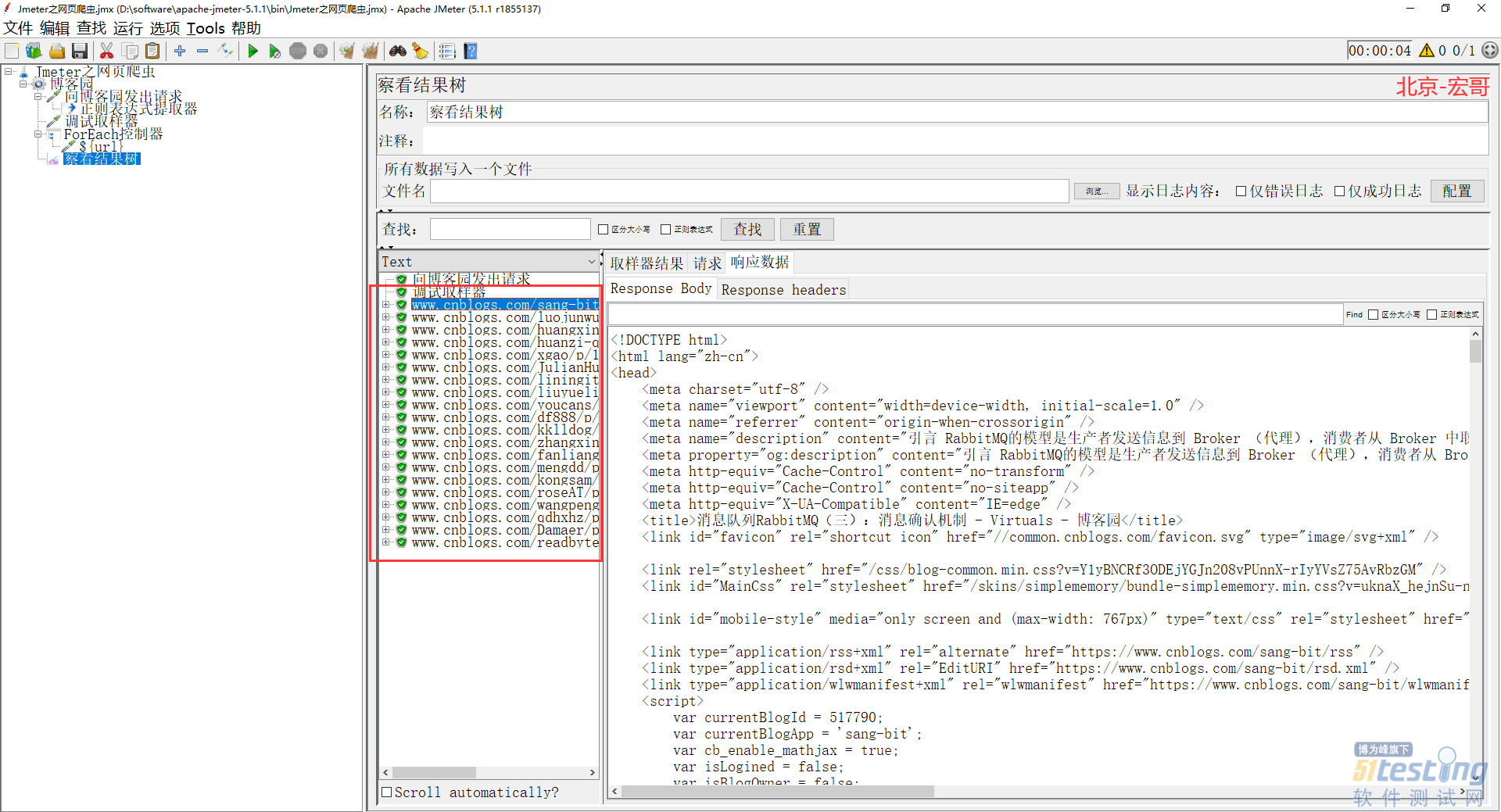
9)重新运行Jmeter后,我们可以观察结果了,见证奇迹的时候到了。观察结果我们发现所有匹配的 url 都被触发了,如下图所示:
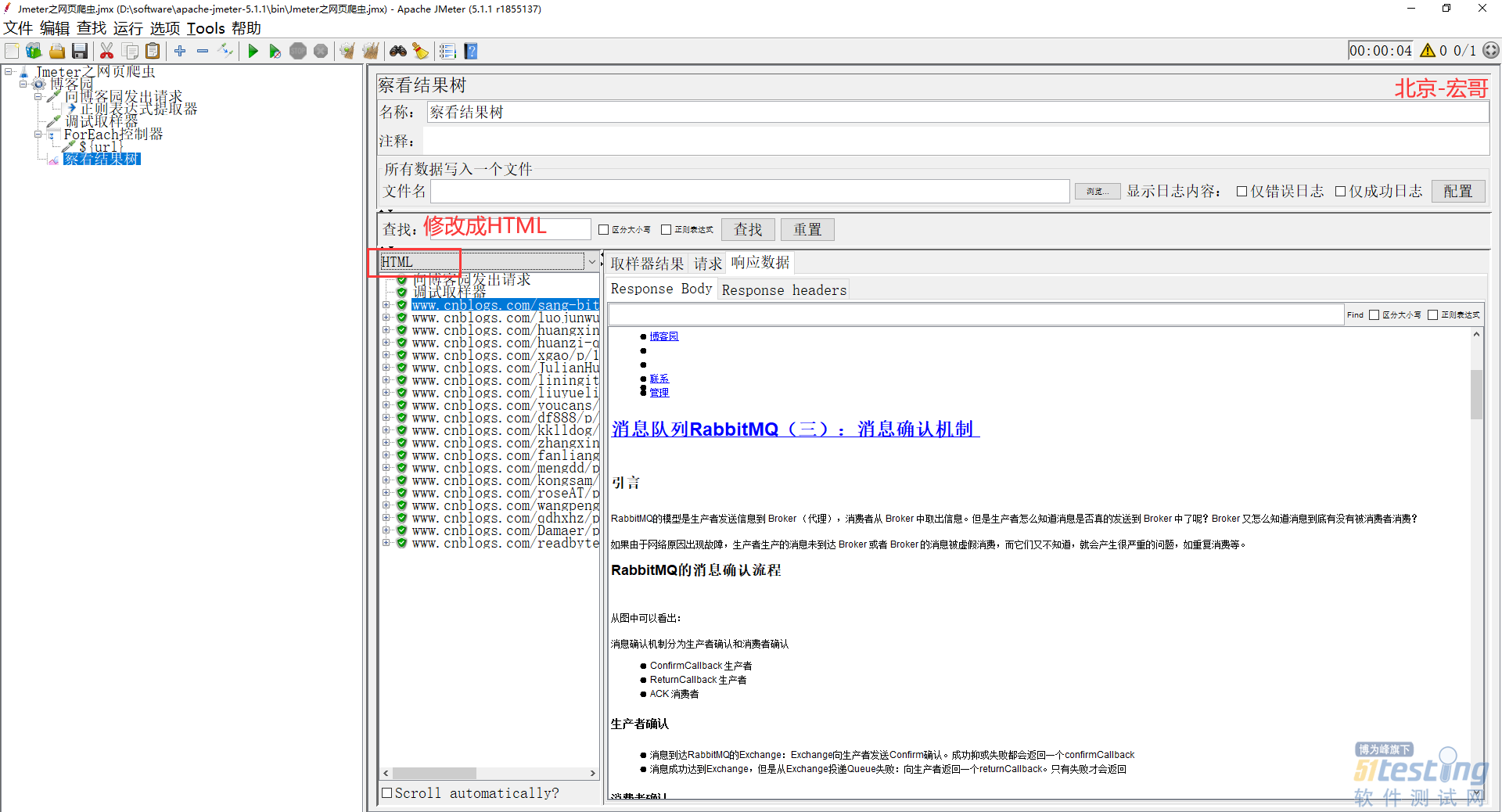
10)修改HTML,可以更好的查看我们爬取到的文章,如下图所示:
到此,Jmeter之网页爬虫-上篇就结束了,是不是很简单?去实际操作一下吧!
4.小结
注意正则表达式,宏哥开始的时候,没有那个问号,结果导致url中,会带有target一串东西,导致请求失败。还有就是https注意有个s否则也会失败的。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












