

1. 背景
不同的弹出框有不同的处理方案:
广告:直接关闭;
警告框:点击确定或者取消;
验证码:输入验证码,进行验证;
登录窗口:进行登录。
下面以1688网站为例,记录几种类型的处理方式。
2. 环境
python 3.6.1
系统:win7
IDE:pycharm
安装过chrome浏览器
配置好chromedriver
selenium 3.7.0
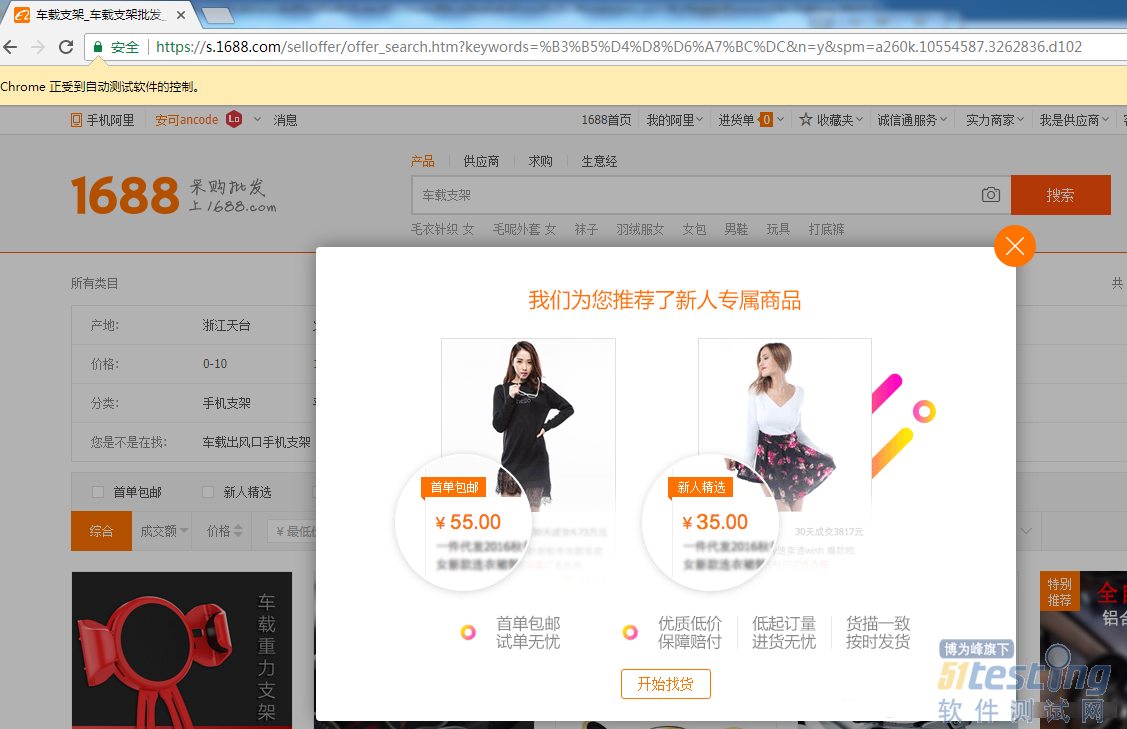
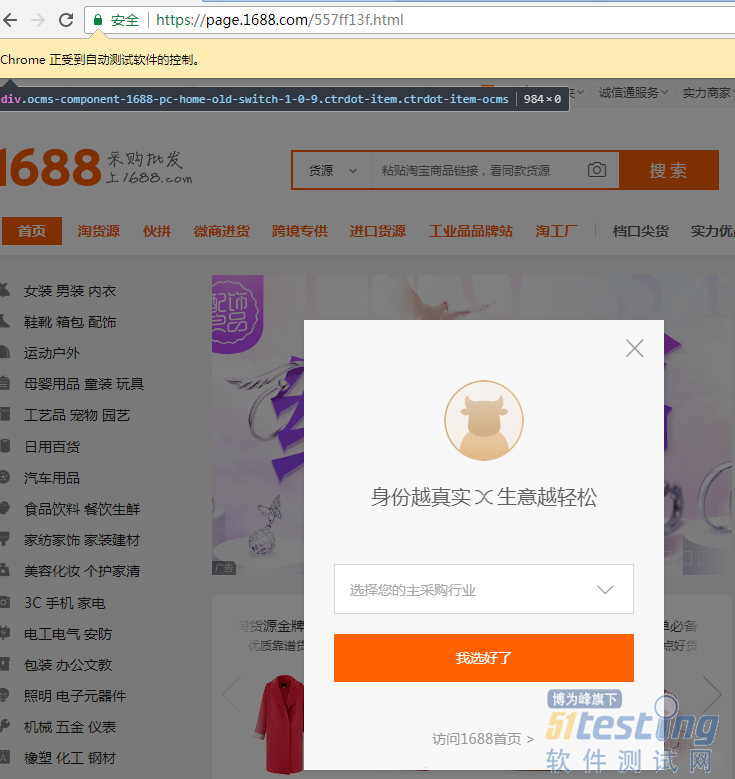
3. 广告弹窗的处理
代码
# 广告页面弹窗处理
def suspondWindowHandler(browser):
# 第一种广告弹窗
try:
suspondWindow = browser.find_element_by_xpath("//div[contains(@class, 'identity-dialog')]//*[contains(@class, 'close-icon')]")
suspondWindow.click()
print(f"searchKey: Suspond Page1 had been closed.")
except Exception as e:
print(f"searchKey: there is no suspond Page1. e = {e}")
# 第二种广告弹窗
# 如果有广告界面弹出,关闭广告。 否则会导致数据无法输入到搜索框
try:
suspondWindow = browser.find_element_by_xpath("//div[contains(@class,'overlay-box')]//div[contains(@class,'overlay-close')]")
suspondWindow.click()
print(f"searchKey: Suspond Page2 had been closed.")
except Exception as e:
print(f"searchKey: there is no suspond Page2. e = {e}")
4. 调用原则
一般来说,在处理广告弹窗时,遵守以下规则时,可以提高程序的稳定性。
将所有出现过的广告类型,集中到一个函数中,如上suspondWindowHandler,每种类型的弹窗都try检测一下。
对广告弹窗元素的获取,尽量收集他们的特征,采用模糊匹配的方式来寻找,如上dialog,overlay-box,close-icon,overlay-close。这样覆盖面可能更广。不过要小心的是,也有可能会误伤。
进入页面时,要首先确保页面已经加载成功了,再来检测广告弹窗是否存在,一定要遵守这个顺序。
关闭广告弹窗之后,一定要重新获取页面元素,防止切换带来的元素失焦。
页面的每次刷新或者数据加载,都可能会带来广告弹出。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import time
import parserPageModel
# 启动浏览器,并设置好wait
browser = webdriver.Chrome()
browser.set_window_size(960, 960) # 设置浏览器窗口大小,和桌面 分辨率有关
wait = WebDriverWait(browser, timeout=20) # 设置页面加载等待时间
# 进入1688首页,搜索关键字
def searchKey(keyWord, DamatuInstance, retryCount):
print(f"searchKey: enter, keyWord = {keyWord}, retryCount = {retryCount}")
retryCount += 1
if retryCount > 8:
return (False, 0, keyWord)
mainUrl = "https://www.1688.com/"
print(f"searchKey: 访问1688主页, 进行搜索. mainUrl = {mainUrl}")
browser.get(mainUrl)
# 尝试搜索
try:
# 搜索框是否出现。用于判断搜索页面是否已经加载好
input = wait.until(
EC.presence_of_element_located((By.XPATH, "//input[@id='alisearch-keywords']"))
)
except Exception as e:
# 搜索框都没出现,说明页面没有加载好,重试
print(f"searchKey: 搜索框还没有加载好,重新加载主页. retryCount = {retryCount}, url = {mainUrl}, e = {e}")
searchKey(keyWord, DamatuInstance, retryCount)
else:
time.sleep(2)
# 处理可能出现的广告
suspondWindowHandler(browser)
try:
# 重新拿到搜索框,防止处理广告页面之后,元素失焦
input = browser.find_element_by_xpath("//input[@id='alisearch-keywords']")
# 输入搜索关键字
time.sleep(5)
input.clear()
input.send_keys(keyWord)
# 敲enter键
input.send_keys(Keys.RETURN)
print(f"searchKey: press return key.")
time.sleep(3)
# 处理可能出现的广告弹窗
suspondWindowHandler(browser)
# 查看搜索结果是否出现。 以商品List是否出现为标准
searchRes = wait.until(
EC.presence_of_element_located((By.XPATH, "//div[contains(@class, 'sm-breadcrumb')]//span[@class='sm-widget-offer']"))
)
print(f"searchKey: searchSuccess, searchRes = {searchRes}")
except Exception as e:
print(f"searchKey: 搜索结果总页数尚未加载好,重新加载主页. retryCount = {retryCount}, url = {mainUrl}, e = {e}")
searchKey(keyWord, DamatuInstance, retryCount)
else:
# 如果发现结果页加载OK, 开始寻找总页数
try:
# 获取结果总页数
print(f"searchKey: 搜索结果已出现,开始寻找总页数")
totalPage = 0
print(f"searchKey: totalPageInit = {totalPage}")
total = wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@class='fui-paging-form ']//span[contains(@class, 'total')]//em[contains(@class, 'num')]"))
)
totalPage = int(total.text)
print(f"searchKey: totalPage = {totalPage}")
return (True, totalPage, keyWord)
except Exception as e:
print(f"searchKey: 搜索结果就一页. e = {e}")
return (True, 1, keyWord)
finally:
# 特别注意:这个部分会在本函数return语句之前执行
# 参考文章解说return和finally:
# Python: 浅析 return 和 finally 共同挖的坑 http://python.jobbole.com/88408/
try:
print(f"searchKey: 取第一页的数据出来,进行存储")
# 解析页面内容:
if browser.page_source:
productInfoLst = parserPageModel.getProductMainInfo(browser.page_source)
print(f"productInfoLst = {productInfoLst}")
except Exception as e:
print(f"searchKey: 取第一页数据出来这个过程出现异常。Exception = {e}")
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












