

ЎЎЎЎұҫОДЦчТӘДЪИЭ°ьАЁТФПВјёёц№ҰДЬөДКөПЦЈә
ЎЎЎЎЎӨОДХВ·ўІј
ЎЎЎЎЎӨЙҫіэөҘМхОДХВУГАэ
ЎЎЎЎЎӨЙҫіэЛщУРОДХВУГАэ
ЎЎЎЎЎӨМнјУIDұкЗ©КөПЦФӘЛШ¶ЁО»
ЎЎЎЎЎӨөЗВј№ҰДЬСйЦӨВлК¶ұр
ЎЎЎЎМнјУОДХВ
ЎЎЎЎМнјУОДХВТіГжЈә

ЎЎЎЎКөПЦЛјВ·Јә
ЎЎЎЎУГАэЙијЖЈә°ьАЁМнјУіЙ№ҰәНМнјУК§°ЬБҪМхcaseЎЈ
ЎЎЎЎ1.ФӘЛШ¶ЁО»
ЎЎЎЎ2.РҙұкМв->ДЪИЭ->өг»ч·ўІј
ЎЎЎЎ3.СйЦӨЈәtoastөҜҙ°ОДұҫДЪИЭХэИ·
ЎЎЎЎҪЕұҫКөПЦЈә
from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from time import sleep from basic.admin_login import Test_admin_login class TestArticle(object): def __init__(self, login): self.login = login # ІвКФМнјУОДХВ def test_add_ok(self): title = 'ОТөДОДХВ' content = 'ОТөДОДХВДЪИЭ' expected = 'ОДХВұЈҙжіЙ№ҰЎЈ' #¶ЁО»ЧуІаОДХВБРұн #ОДХВ self.login.driver.find_element_by_xpath('//*[@id="sidebar-menu"]/li[4]/a/span[1]').click() sleep(1) #ОДХВ№ЬАн self.login.driver.find_element_by_xpath('//*[@id="sidebar-menu"]/li[4]/ul/li[1]/a').click() sleep(1) #РВҪЁ self.login.driver.find_element_by_xpath('/html/body/div/div/section[3]/div/div/div/div[1]/div/div/a').click() sleep(1) #¶ЁО»ОДХВЗшУт #ұкМв self.login.driver.find_element_by_id('article-title').send_keys(title) sleep(1) #ҪшИлiframe frame1=self.login.driver.find_element_by_xpath('//*[@id="cke_1_contents"]/iframe') self.login.driver.switch_to.frame(frame1) sleep(1) #ОДХВДЪИЭ self.login.driver.find_element_by_xpath('/html/body').send_keys(content) #НЛіцframe self.login.driver.switch_to.default_content() #·ўІј°ҙЕҘ self.login.driver.find_element_by_class_name('btn-primary').click() #toast¶ЁО» loc=(By.CLASS_NAME,"toast-message") #өИҙэtoastіцПЦ WebDriverWait(self.login.driver,5).until(EC.visibility_of_element_located(loc)) #toastОДұҫ message=self.login.driver.find_element(*loc).text #¶ПСФЕР¶ПtoastОДұҫәНЖЪНыЦөПаөИ assert message==expected |
ЎЎЎЎЧўТвөгЈә
ЎЎЎЎ1.frameөҜҙ°өДЗРИлЗРіц
ЎЎЎЎ2.ОДХВДЪИЭ¶ЁО»ТіГжјмІйКұөҪ/htmlЈ¬РиТӘЧФјәКЦ¶ҜМнјУөҪbodyПВ'/html/body'
ЎЎЎЎ3.·ўЛНК§°ЬtoastөҜҙ°ПыК§әЬҝмЈ¬ҝЙТФ¶аҙОөг»чјёПВ¶ЁО»
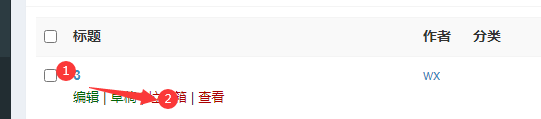
ЎЎЎЎЙҫіэөҘМхОДХВУГАэ
ЎЎЎЎЙҫіэОДХВТіГжЈә
ЎЎЎЎКөПЦЛјВ·Јә
ЎЎЎЎУГАэЙијЖЈәЙҫіэіЙ№ҰЎЈ
ЎЎЎЎ1.КуұкРьНЈФЪОДХВұкМв
ЎЎЎЎ2.өг»чА¬»шПд
ЎЎЎЎ3.СйЦӨЈәСйЦӨЙҫіэәуОДХВКэ=ЙҫіэЗ°ОДХВКэ-1
ЎЎЎЎҪЕұҫКөПЦЈә
article.py # ІвКФЙҫіэөҘЖӘОДХВ def test_delete_one_article_ok(self): # ОДХВ№ЬАн self.login.driver.find_element_by_xpath('//*[@id="sidebar-menu"]/li[4]/ul/li[1]/a').click() sleep(1) #ЙҫіэЗ°ОДХВКэ beforenumber=len(self.login.driver.find_elements_by_class_name('jp-actiontr')) #КуұкРьНЈОДХВДЪИЭ a=self.login.driver.find_element_by_xpath('/html/body/div/div/section[3]/div/div/div/div[2]/table/tbody/tr[2]/td[2]/strong/a') ActionChains(self.login.driver).move_to_element(a).perform() #Йҫіэ self.login.driver.find_element_by_xpath('/html/body/div/div/section[3]/div/div/div/div[2]/table/tbody/tr[2]/td[2]/div/div/a[3]').click() sleep(1) #ЙҫіэәуОДХВКэ afternumber=len(self.login.driver.find_elements_by_class_name('jp-actiontr')) #СйЦӨЙҫіэәуОДХВКэ=ЙҫіэЗ°ОДХВКэ-1 assert beforenumber==afternumber+1 |
ЎЎЎЎјјКхДСөгЈә
ЎЎЎЎ1.КуұкРьНЈІЩЧчЈә
| ActionChains(self.login.driver).movetoelement(a).perform() |
ЎЎЎЎ2.ОДХВКэДҝК№УГlen()әҜКэИ·ИП
ЎЎЎЎ3.ЛщУРОДХВКэДҝИ·ИПНЁ№эself.login.driver.findelementsbyclassname¶ЁО»Т»ЧйelementsИ·ИП
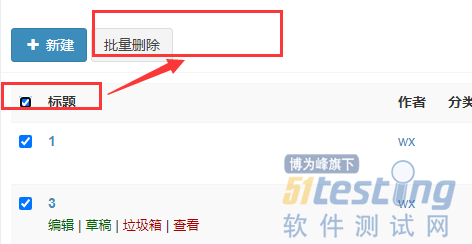
ЎЎЎЎЙҫіэЛщУРОДХВУГАэ
ЎЎЎЎЙҫіэЛщУРОДХВТіГжЈә
ЎЎЎЎКөПЦЛјВ·Јә
ЎЎЎЎУГАэЙијЖЈәЙҫіэіЙ№ҰЎЈ
ЎЎЎЎ1.өг»чИ«СЎёҙСЎҝт
ЎЎЎЎ2.өг»чЕъБҝЙҫіэ
ЎЎЎЎ3.СйЦӨЈәСйЦӨОДХВКэДҝ=0
ЎЎЎЎКөПЦҪЕұҫЈә
# ІвКФЙҫіэЛщУРОДХВ def test_delete_all_article_ok(self): #ОДХВ№ЬАн self.login.driver.find_element_by_xpath('//*[@id="sidebar-menu"]/li[4]/ul/li[1]/a').click() #өг»чИ«ІҝёҙСЎҝт self.login.driver.find_element_by_xpath('/html/body/div/div/section[3]/div/div/div/div[2]/table/tbody/tr[1]/th[1]/input').click() sleep(1) self.login.driver.find_element_by_id('batchDel').click() sleep(1) WebDriverWait(self.login.driver,5).until(EC.alert_is_present()) alert = self.login.driver.switch_to.alert alert.accept() sleep(1) #ОДХВКэДҝ=0 afternumber = len(self.login.driver.find_elements_by_class_name('jp-actiontr')) sleep(1) assert afternumber==0 if __name__ == '__main__': login = Test_admin_login() login.login_success() testArticle = TestArticle(login) testArticle.test_add_ok() #testArticle.test_delete_one_article_ok() testArticle.test_delete_all_article_ok() |
ЎЎЎЎЧЬҪбЈә
ЎЎЎЎНЁ№эЙПГжОТГЗҝЙТФ·ўПЦЈ¬ЧФ¶Ҝ»ҜУГАэөДКөПЦј°УГАэәН№ҰДЬІвКФУГАэ»щұҫЙПКЗТ»СщөДЈ¬ПаН¬өДІЩЧчІҪЦиЈ¬ПаН¬өДСйЦӨ·Ҫ·ЁЎЈЦ»І»№эКЗНЁ№эҪЕұҫөД·ҪКҪХ№ПЦіцАҙЈ¬НЁ№эПВГжөДұнёсФЩҙОјУЙоТ»ПВУЎПуЎЈ
ЎЎЎЎМнјУIDұкЗ©КөПЦФӘЛШ¶ЁО»
ЎЎЎЎОКМвЗйҫіЈә
ЎЎЎЎФЪұҫөШ»·ҫіutil№ӨҫЯАаАпУРТ»ёц·вЧ°әГөДНјЖ¬СйЦӨВлАаЈ¬КөПЦК¶ұрНјЖ¬ЦРөДСйЦӨВлЈ¬РиТӘҙ«ИлІОКэidЎЈ
ЎЎЎЎө«З°¶ЛТіГжГ»УРidКфРФЈ¬РиТӘМнјУТ»ёцidКфРФЈ¬ИзПВНјЈә
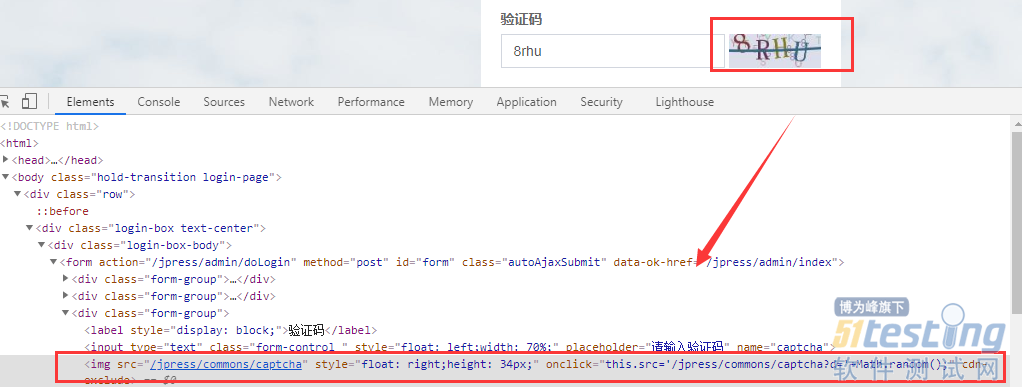
ЎЎЎЎДЗГҙЈ¬ФхГҙСщІЕДЬПтЗ°¶ЛТіГжМнјУКфРФЦөДШЈҝХвАпОТГЗК№УГJSУп·ЁЎЈ
ЎЎЎЎМнјУidөДЛјВ·ИзПВЈә
ЎЎЎЎКЧПИЈ¬НЁ№эЙПНјөДimgұкЗ©ХТөҪТӘҙҰАнөДHTMLФӘЛШЈ»
ЎЎЎЎИ»әуЈ¬ІЩЧчХвёцФӘЛШЈ¬НЁ№эsetAttributeМнјУКфРФј°КфРФЦөЈ»
ЎЎЎЎЧўТвЈәjsҪЕұҫРиТӘ·ЕөҪТ»ёцұдБҝЦРЈ¬И»әуНЁ№эself.driver.execute_script(js)ЦҙРРҪЕұҫЎЈ
ЎЎЎЎКөПЦҪЕұҫЈә
js="document.getElementsByTagName('img')[0].setAttribute('id','captchaimg')" self.driver.execute_script(js) |
ЎЎЎЎСйЦӨКЗ·сМнјУіЙ№ҰЈә
ЎЎЎЎ1.ChromeдҜААЖчF12Ј¬ХТөҪconsoleЈ¬КдИлҪЕұҫЈә
| document.getElementsByTagName('img')[0].setAttribute('id','captchaimg') |

ЎЎЎЎ2.·ө»Шelement tabПВЈ¬ІйҝҙҙжФЪidКфРФИзПВНјЈә

ЎЎЎЎЙПГж»сИЎФӘЛШөД·Ҫ·ЁіэБЛұкЗ©ГыіЖ»№УРЖдЛы·ҪКҪИзЈә
ЎЎЎЎЎӨgetElementById()
ЎЎЎЎЎӨgetElementByName()
ЎЎЎЎЎӨgetElementByTagName()
ЎЎЎЎЎӨgetElementByClassName()
ЎЎЎЎЦБУЪәОЦЦ·Ҫ·ЁҝЙТФёщҫЭФҙВлІйҝҙЈ¬ФҙВлУРКІГҙУГКІГҙ·Ҫ·ЁЎЈ
ЎЎЎЎұЁҙнРЕПў
| javascript error: Cannot read property 'setAttribute' of undefined |
ЎЎЎЎКэЧйФҪҪз
ЎЎЎЎФҙҙъВлЈә
| js="document.getElementsByTagName('img')[1].setAttribute('id','captchaimg')" |
ЎЎЎЎОДөөЦРТ»№ІУРТ»ёцimgұкЗ©Ј¬ПВұкҙУ0ҝӘКјЈ¬ЛщТФҪ«1ёДОӘ0ЎЈ
ЎЎЎЎРЮёДәуЈә
| js="document.getElementsByTagName('img')[0].setAttribute('id','captchaimg')" |
ЎЎЎЎЙПГжМṩһЦЦҙҰАнОКМвөДЛјВ·Ј¬өұОТГЗРиТӘДіЦЦФӘЛШұкЗ©КұЈ¬ІўЗТХвЦЦұкЗ©І»ҙжФЪөДЗйҝцПВОТГЗҝЙТФЧФјәАыУГjsУп·ЁМнјУұкЗ©ІўКөПЦөчУГЎЈ
ЎЎЎЎН¬КұЈ¬ФЪУцөҪseleniumұҫЙнУп·ЁОЮ·ЁҪвҫцөДОКМвЈ¬ҝЙТФҪиЦъjsҪЕұҫНкіЙЈ¬ұИИзТіГжЙППВ»¬¶ҜЎўҙҰАнКұјдҝХјдөИөИЎЈ
ЎЎЎЎөЗВј№ҰДЬСйЦӨВлК¶ұр
ЎЎЎЎТ»°гwebНшХҫөЗВјТіГж¶ј»бУРСйЦӨВлК¶ұр№ҰДЬ Ј¬Из№ыКЗ№«ЛҫДЪІҝІвКФЈ¬ҝЙТФИГҝӘ·ўИЛФұНЁ№эЖБұОСйЦӨВл»тХЯБфәуГЕ·ҪКҪЗбЛЙМш№эЈ¬ҙуҝЙІ»ұШ°СКұјдАЛ·СФЪСйЦӨВлК¶ұрЙПЎЈ
ЎЎЎЎө«КЗЈ¬ҙуІҝ·ЦРЎ»п°йТ»°гёХҝӘКјҪУҙҘЧФ¶Ҝ»ҜКұ¶јКЗЧФјәХТөДПоДҝЈ¬»щұҫЙПКцБҪЦЦ·Ҫ·ЁІ»ККУГЎЈ
ЎЎЎЎПВГжНЖјцБҪЦЦіЈУГөДСйЦӨВлК¶ұр·ҪКҪЈә
ЎЎЎЎөЪТ»ЦЦOCRЧФ¶ҜК¶ұр·ҪКҪЈ¬ИұөгҪПёҙФУөДСйЦӨВлК¶ұрІ»іцАҙЎЈ
ЎЎЎЎөЪ¶юЦЦЈ¬өЪИэ·ҪAPIК№УГЈ¬ОТХвАпК№УГөДКЗҙтВлЖҪМЁөДЈ¬іэҙЛЦ®Нв°Щ¶ИК¶ұр»тХЯНтО¬ТЧФҙЈЁИұөгЈәөчУГ·ұЛцЎў·СУГҪПёЯЈ©ЎЈ
ЎЎЎЎіЎҫ°ЈәК¶ұрПВНјөДСйЦӨВлЎЈ

ЎЎЎЎOCRЧФ¶ҜК¶ұрөДФӯАн
ЎЎЎЎФЪХвАпОТГЗРиТӘК№УГpytesseractЈ¬ЛьКЗТ»ҝоУГУЪ№вС§ЧЦ·ыК¶ұрЈЁOCRЈ©өДpython№ӨҫЯЈ¬јҙҙУНјЖ¬ЦРК¶ұріцЖдЦРЗ¶ИлөДОДЧЦЎЈ
ЎЎЎЎХыёц№эіМ·ЦОӘҪШИЎөЗВјТіГж->»сИЎСйЦӨВлөДО»ЦГЧшұк->ҙтҝӘҪШНј->ҙУҪШНјЦРҪШИЎСйЦӨВлөДЗшУт->К№УГpytesseract№ӨҫЯК¶ұрСйЦӨВлЈ¬ХвАпЦұҪУК№УГpytesseractЧӘ»»ҪйЙЬЎЈ
ЎЎЎЎ1.°ІЧ°Pillow
| pip install Pillow |
ЎЎЎЎ2.°ІЧ°pytesseract
| pip install pytesseract |
ЎЎЎЎ3.КөПЦҙъВл
from PIL import Image өјИлImageәҜКэ import pytesseract өјИлpytesseract def get_file_content(filePath): # 3.СйЦӨВлҙҰАн-К№УГOCRЧФ¶ҜК¶ұр qq = Image.open("D://software//project//jpress//testcases//basic//test.png") # ҙтҝӘjpgСйЦӨВлНјЖ¬ text = pytesseract.image_to_string(qq).strip() |
ЎЎЎЎФЛРРІйҝҙҪб№ы·ө»ШОӘҝХЈ¬ЛщТФЛөХвЦЦ·Ҫ·Ё¶ФУЪјтөҘөДСйЦӨВл»№ҝЙТФЈ¬ёҙФУТ»өгөДҝЙТФЦұҪУ·ЕЖъЎЈ

ЎЎЎЎөЪИэ·ҪAPIҪУҝЪ
ЎЎЎЎҙтВлЖҪМЁБҙҪУөШЦ·Јә
ЎЎЎЎhttp://www.ttshitu.com/docs/index.html?spm=null
ЎЎЎЎКЧПИРиТӘЧўІбТ»ёцХЛәЕЈ¬ЖдҙОідЦөЈ¬1ҝйЗ®№»УГНҰіӨКұјдЈ¬ХТөҪ¶ФУҰөДУпСФЈЁИзpythonЈ©Ј¬ҝҪұҙҙъВлЈә
°жИЁЙщГчЈәұҫОДіцЧФЎ¶51ІвКФМмөШЎ·өЪБщК®Т»ЖЪЎЈ51TestingИнјюІвКФНшј°Па№ШДЪИЭМṩХЯУөУР51testing.comДЪИЭөДИ«Іҝ°жИЁЈ¬ОҙҫӯГчИ·өДКйГжРнҝЙЈ¬ИОәОИЛ»төҘО»І»өГ¶ФұҫНшХҫДЪИЭёҙЦЖЎўЧӘФШ»тҪшРРҫөПсЈ¬·сФтҪ«Ч·ҫҝ·ЁВЙФрИО












