

随着信息技术的高速发展和数据的海量增长,人们对软件系统的性能要求越来越高,希望系统能够承载更多的负荷,同时还能提供高效的服务,如何做好性能测试,也成为软件测试者更为重视的一个问题。在性能测试中,涉及到很多环节,比如测试环境的准备、测试数据的准备、性能测试场景设计、性能测试脚本录制、性能测试执行以及性能调优等,每个环节的工作都会影响到性能测试的准确性,如果操作不当,将会导致无法准确的实现“模拟实际情况”的目标。本文聚焦介绍测试数据应该如何准备,并通过实例浅谈测试数据对于性能测试结果的影响。
一、性能测试数据如何准备
性能测试涉及到的数据一般有三类:业务系统数据、测试铺底数据和测试执行数据,各自的定义和准备方法具体如下:
1、业务系统数据
当性能测试环境准备就绪后,还需要在测试环境中准备业务以及系统相关的数据,让系统在后续的压力测试中能够正常地运行。这些数据往往包括业务类的比如用户信息、业务和交易的配置信息,以及系统类的比如系统配置信息、与外联第三系统的配置信息等,一般可以通过两种方式来准备:
1)数据导入,可将系统其他测试环境中 已配置好的业务系统数据直接导入到性能测试环境中的对应表中,如有需要再利用SQL语句修改数据以适应性能测试环境,让其生;
2)手动配置,可以根据业务规则和系统设置需要,通过APP、GUI或者网页进行手动配置,让业务系统数据自动生成并存储在数据库中。当数据准备完毕后,还需要对性能测试的业务或交易进行验证,保证业务或交易的可用性和正确性。
2、测试铺底数据
测试铺底数据在性能测试中起到非常重要的作用。数据库表中有几条数据和有几千万条数据时,对于查询、插入和更新等数据库操作的执行计划和执行时间差异非常大,会严重影响性能测试的结果。例如数据量不同,数据库引擎对同样SQL的执行计划不一样,有的可能全表扫描进行引起表锁,有的可能索引扫描,不同的策略会对数据 库的性能造成不同的结果。再例如铺底数据过少,有可能会使测试环境中的响应时间比生产系统的时间快很多,导致测试没有模拟真实的情况,并没有任何参考性。
而且生产系统随着时间的推移,业务量逐年增加,数据越来越多,测试数据需要保持或接近生产系统的级别,才能让性能测试的过程最接近生产系统的真实压力。
这么多数据,我们如何快速地准备呢?首先要了解铺底数据的作用,如果需要铺底的数据跟业务逻辑息息相关,则最好接近真实的生产数据,保持原来的业务规则、数据约束关系和数据分布性,一般可以通过生产数据导入和压力测试工具产生等方法。
生产数据导入的基本过程是:
1)从生产系统的数据库表中全部或部分导出数据;
2)对导出的敏感数据进行脱敏处理;
3)把脱敏后的数据再导入到测试环境的相应表中。此方法的优点是数据真实性高,数据分布合理,数据压力点和线上系统保持一致,缺点是需要对敏感数据进行脱敏处理,如果敏感数据涉及到索引和约束关系等,需要选择合适的脱敏方法保持数据原有的特性。
压力测试工具产生:
可以通过Loadrunner或Jmete等工具按照业务规则编制脚本进行多线程发压,批量产生数据。此方法的优点是数据接近真实,不用脱敏,缺点是需要时间来产生数量数据。
如果铺底数据的作用和业务逻辑关系不大,只为使数据量达到规定的规模,可以通过数据库存储过程或程序等方法批量产生。如下图为MySQL的存储过程示例:

3、测试执行数据
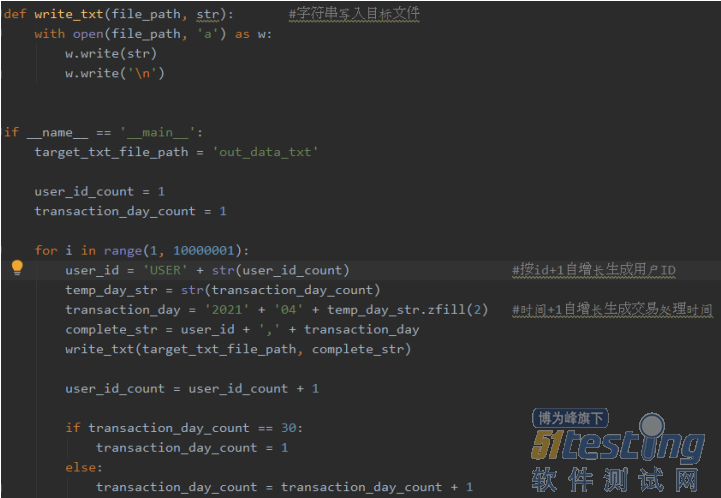
测试执行数据是压力测试工具中需要用到的参数化数据,一般可通过程序批量产生可用的数据文件,或使用测试工具添加配置元件如计数器或随机变量等自动产生参数化数据。测试执行数据需按照设计的性能测试场景产生,符合实际的业务规则,并考虑数据的分布性等因素,否则与真实的情况相差太远,也会影响性能测试的结果。如下图为Python程序批量产生测试执行数据并存储到TXT文件的示例:
二、测试数据对性能测试的影响
下面将通过两个实例浅谈测试数据对性能测试的影响。
实例一:铺底数据量不够难以发现性能问题
在此实例中,压力测试涉及到的查询SQL:
| SELECT TEST_COL FROM TEST_TABLE WHERE COL1=:1 AND COL2=:2 AND COL3=:3; |
查询目标表是TEST_TABLE,WHERE查询条件是COL1,COL2和COL3,其中TEST_TABLE有一条索引(COL1,COL2),不包含COL3。当TEST_TABLE的铺底数据量不同时,查询SQL命中索引(COL1,COL2)的数据量都为30万,同样模拟10个用户发起5分钟的压力测试,通过ORACLE AWR报告可以看出,此SQL相关的性能指标大不相同。
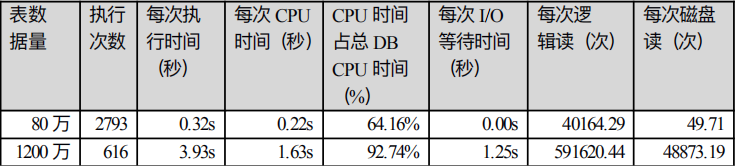
如下表所示:当铺底数据量分别是80万和1200万时,数据量越大,此查询SQL的执行时间、CPU时间、CPU时间占总DB CPU时间的百分比、I/O 等待时间、逻辑读次数和磁盘读次数都大幅度提高。
分析原因是铺底数据量较高时,此条SQL需要在内存中读取的索引和扫描的数据块越多,因此逻辑读次数越多,造成CPU消耗越大,但数据库的内存有限,一次不能读取所有数据块在内存中,所以涉及到磁盘读数据,造成I/O等待。当铺底数据量较小时, 也许不能很快发现此条SQL的性能问题,只有当数据量到达一定规模时比如千万级别,才会快速暴露问题。解决此性能问题的方案可以将COL3添加到当前索引(COL1,COL2,COL3),让查询能够直接命中索引,减少数据块的读取和扫描次数:
实例二:参数化数据的不同影响查询SQL的执行计划和时间
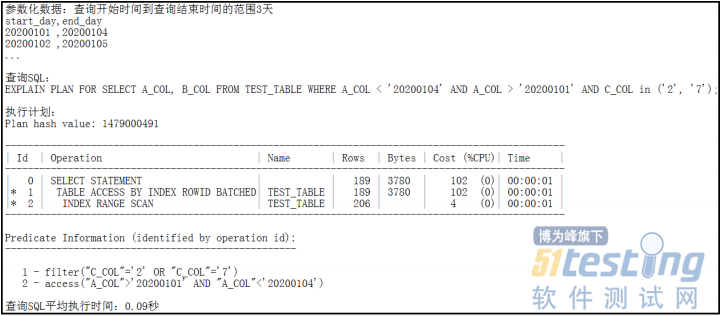
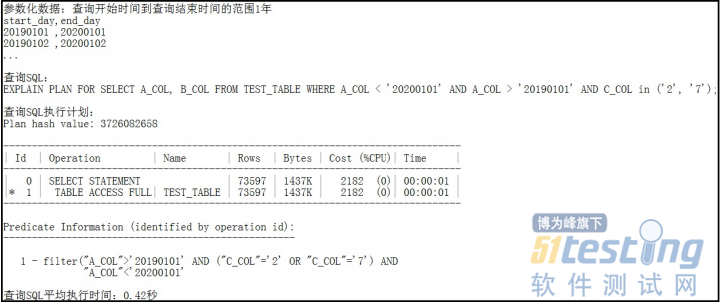
在此实例中,压力测试的业务场景是针对一支交易指定一个查询开始时间和结束时间查找某些历史数据信息,其压力测试脚本的参数化信息就是查询开始时间和查询结束时间,交易对应访问的数据表是TEST_TABLE,其数据量100万,查询时间对应的列是A_COL,A_COL是TEST_TABLE的主键第一列。如下两个场景,当场景一的查询起止时间范围是3天时,查询SQL利用A_COL>’查询开始时间’ AND A_COL<’查询结束时间’来查询TEST_TABLE,其执行计划是INDEX RANGE SCAN,返回的记录数rows数据量较小,估算是206,平均执行时间较短是0.09 秒;当场景二的查询起止时间范围是1年时,查询SQL同样利用 A_COL>’查询开始时间’AND A_COL<’查询结束时间’来查询TEST_TABLE,其执行计划却变成了TABLE ACCESS FULL,返回的记录数rows数据量较小,估算是73597,平均执行时间较场景1增长到0.42秒。可以看出查询起止时间的范围不同,在同样的数据量和数据分布下,数据库对查询SQL选择的执行计划不同,处理和返回的数据量不同,造成了SQL执行时间的较大差异。我们在性能测试中,应该根据业务规则,尽可能覆盖最厂长查询数据范围, 如此实例中的场景二,把在此场景下的压力测试结果作为性能是否接受的标准。
场景一:
场景二:
通过前面的介绍以及实例可以看出,性能测试数据是性能测试中的一个重要组成部分,测试执行者在发压之前应该了解清楚系统的性能特性、数据特性以及业务逻辑,设计出合理的测试场景,准备接近生产系统的测试数据,这样才能模拟真实的压力场景,让性能问题得以暴露和解决。
版权声明:本文出自51Testing会员投稿,51Testing软件测试网及相关内容提供者拥有内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。












