

前言
前四期我们学习了大数据分析的理论基础知识(第一期&第二期)以及给大家演示了如何将其应用到自己的工作中,为自己的工作增加价值(第三期&第四期),女巫在写这篇文章的时候正是2020年的圣诞节,魔幻般的2020终于就要接近尾声,女巫的大数据分析系列也快要接近尾声,其实这个系列也只是大数据分析的初阶篇,很多复杂的统计学理论,例如:假设检定,单边检定,双边检定等并没有涉及;因为担心会把大家的学习热情浇灭,所以希望尽量将一些较为简单的理论,重点在实践,希望大家学了这个系列,真的可以对自己的工作带来价值,课程的终点就是起点,因为大数据分析真的值得学习的内容太多了,还是那句话:路漫漫其修远兮,吾将上下而求索~~~~
我这次先给大家展示一个非常有实际意义的分析方法:失败率分析,然后再帮助大家一起总结一下,我们这2020年学习的大数据分析的模式是什么,我们这个系列虽然是一个大数据分析的初阶课程,但是并不妨碍我们将其总结一个分析模式,应将其应用到我们的实际工作中。
闲聊结束,让我们赶紧进入实战之旅吧!
推论统计学之失败率
为什么失败率对我们这样重要
我们在实际工作中会遇到这样的情况:工程师在实验室测试的结果都是Pass,为什么到了工厂会Fail?有时是环境问题:即同样的待测物在研发阶段为Pass但是到工厂会Fail。
往往出了这样的问题后,会造成额外的厘清问题的成本产生,我们有没有办法用数据分析的方式,尽量在RD端就能把这些问题cover住?
我们再保证我们的产品符合spec的基础上,是不是可以计算一下,它小于spec或者大于spec的机率。
如果这个机率比较大,工程师是不是可以再努力一下,让测试数据margin更大一些?以免到了工厂量产时会因为margin不大,加上一些环境等变异因素,最后导致测试结果Fail,而无法量产。
失败率就可以帮助我们解决这个问题。
累积分布(Cumulative Distribution)
定义
是概率密度函数的积分,能完整描述一个实随机变量X的概率分布。一般以大写CDF标记,,与概率密度函数probability density function(小写pdf)相对。
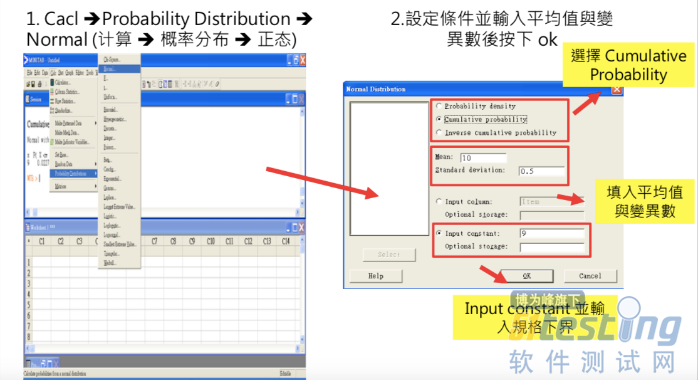
我们经常可以看到cdf以及pdf都是成对出现,我们看一下熟悉的minitab中也是将cdf和pdf成对出现,如下图1:
它的函数如下图2:
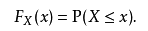
使用原理
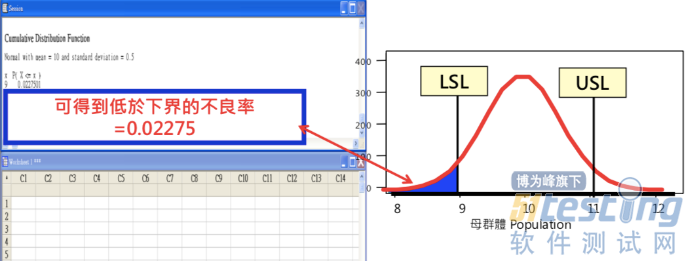
基于它的定义以及函数可以看出,它实际上计算的就是数据为常态分布的spec的左边的部分,如果我们要计算spec的下界的分布机率,即小于某个spec的机率如下图3:
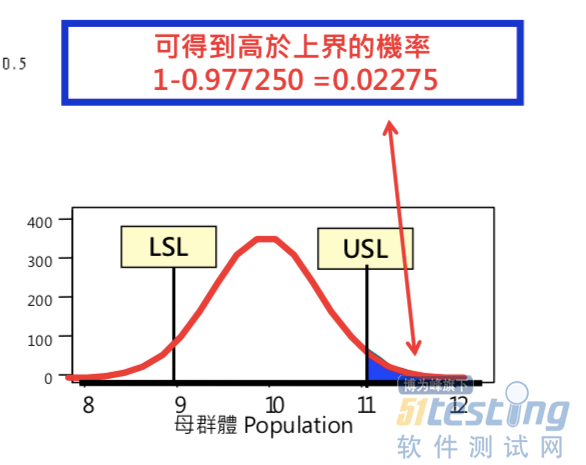
如果我们要计算spec的上界的分布机率,即大于某个spec的机率如下图4,如果计算上界需要1-%,因为它计算的永远是小于当前设定spec数值,左边分布的机率:
代码实现
画出Cumulative Distribution的chart。
1.使用statsmodels模块+matploylib模块组合画图
有一个好处,因为statsmodels中有ECDF函数供我们调用。
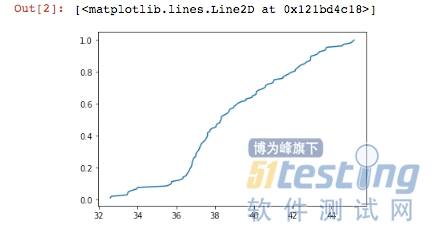
from statsmodels.distributions.empirical_distribution import ECDF import pandas as pd import matplotlib.pyplot as plt excel_data_1 = pd.read_excel('5GACLR.xlsx',sheet_name = 'N350150_aclr') trace_aclr_1 = excel_data_1['Tx ACLR (dB)'] ecdf = ECDF(trace_aclr_1 ) plt.plot(ecdf.x,ecdf.y) |
运行结果如下图5:
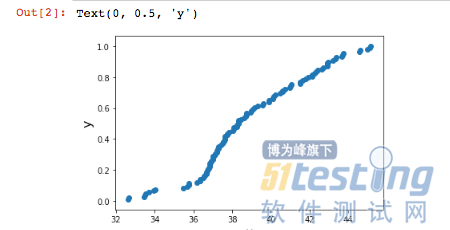
使用numpy模块+matploylib模块组合画图 画图所使用的x,y需要自己写算法即函数def ecdf。
import numpy as np import pandas as pd import matplotlib.pyplot as plt excel_data_1 = pd.read_excel('5GACLR.xlsx',sheet_name = 'N350150_aclr') trace_aclr_1 = excel_data_1['Tx ACLR (dB)'] def ecdf(data): """Compute ECDF for a one-dimensional array of measurements.""" # Number of data points: n n = len(data) # x-data for the ECDF: x x = np.sort(data) # y-data for the ECDF: y y = np.arange(1, n+1) / n return (x,y) a,b = ecdf(trace_aclr_1) plt.scatter(x=a,y=b) plt.xlabel("x",fontsize =16) plt.ylabel("y",fontsize=16) |
运行结果如下图6:
使用scipy的norm的cdf计算小于某个数的机率。
import numpy as np import pandas as pd from scipy.stats import norm import matplotlib.pyplot as plt excel_data_1 = pd.read_excel('5GACLR.xlsx',sheet_name = 'N350150_aclr') trace_aclr_1 = excel_data_1['Tx ACLR (dB)'] mymean = trace_aclr_1.mean() std =trace_aclr_1.std() norm(mymean, std).cdf(33) |
运行结果如下:
即小于33的机率是2.27%
0.022710578250867305
如果我们从开发阶段要求比较严格,不是达到spec.就万事大吉,而是还要继续分析,无法达到标准的机率,如果机率比较大,还是需要继续调整,确保量产万无一失,这样的工作模式一旦形成真的可以大大降低cost。
总结
激动人心的时刻终于来临了,我们完成了数据分析系列之后,终于可以尝试建立属于我们测试人自己的Pattern了!甚至可以Pattern会写到我们自己公司的系统中,给大家带来便利的统计学应用的服务!!
版权声明:本文出自《51测试天地》第六十期。51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任












