


我们日常项目中的接口测试案例肯定不止一个,当案例越来越多时我们如何管理这些批量案例?如何保证案例不重复?如果案例非常多(成百上千,甚至更多)时如何保证案例执行的效率?如何做(批量)测试数据的管理?如何做到数据与脚本分离?
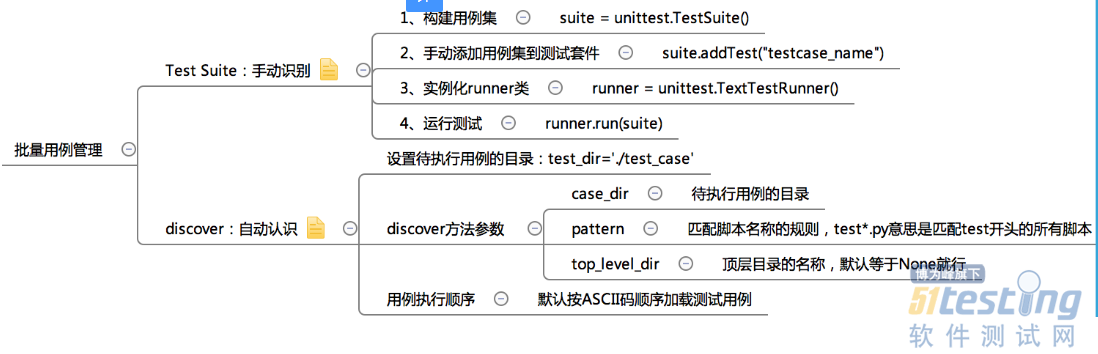
一、手工加载批量用例:
-- coding:utf-8 -- 批量用例执行--手工加载 import unittest class TestOne(unittest.TestCase): def setUp(self): print '\ncases before' pass def test_add(self): '''test add method''' print 'add...' a = 3 + 4 b = 7 self.assertEqual(a, b) def test_sub(self): '''test sub method''' print 'sub...' a = 10 - 5 b = 5 self.assertEqual(a, b) def tearDown(self): print 'case after' pass if name == 'main': # 1、构造用例集 suite = unittest.TestSuite() # 2、执行顺序是安加载顺序:先执行test_sub,再执行test_add suite.addTest(TestOne("test_sub")) suite.addTest(TestOne("test_add")) # 3、实例化runner类 runner = unittest.TextTestRunner() # 4、执行测试 runner.run(suite) |
二、自动加载批量用例:
-- coding:utf-8 -- 批量用例执行--自动加载 import unittest import os class TestOne(unittest.TestCase): def setUp(self): print '\ncases before' pass def test_add(self): '''test add method''' print 'add...' a = 3 + 4 b = 7 self.assertEqual(a, b) def test_sub(self): '''test sub method''' print 'sub...' a = 10 - 5 b = 5 self.assertEqual(a, b) def tearDown(self): print 'case after' pass if name == 'main': # 1、设置待执行用例的目录 test_dir = os.path.join(os.getcwd()) # 2、自动搜索指定目录下的cas,构造测试集,执行顺序是命名顺序:先执行test_add,再执行test_sub discover = unittest.defaultTestLoader.discover(test_dir, pattern='test_*.py') # 实例化TextTestRunner类 runner = unittest.TextTestRunner() # 使用run()方法运行测试套件(即运行测试套件中的所有用例) runner.run(discover) |
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理











