

云计算1.0使用的主要技术就是虚拟化,也是接触云计算学习第一个知识,很多人会觉得云计算就是虚拟化,这两个的概念还是不同的,虚拟化可以将传统IT中的应用程序及操作系统与硬件解耦,并且虚拟化化和云计算一样,都可以通过这个功能构建可用的、稳定的运行环境给应用程序。
其实虚拟化只是提供了IaaS模式的服务,而云计算还提供了其他模式的服务,而其他模式的服务几乎都是在IaaS的基础上发展起来的。
虚拟化简介
1、虚拟化是什么
虚拟化的本质就是将原先的物理设备进行逻辑化,转化成一个文件夹或文件,实现软硬件的解耦。使用虚拟化后,物理服务器转变成一个文件夹或文件,这里面一般会包含两部分,一部分用来记录虚拟机的配置信息,另一部分用来保存用户数据的磁盘文件。
使用虚拟化前的问题:
每台物理机上只能同时运行一个操作系统,如果在服务器上运行多个主应用
程序,那么不同应用之间可能会产生冲突和性能问题。实际上,最佳做法是每个服务器仅运行一个应用程序以避免这些问题,但是这么做的结果是系统资源长时间利用率较低。
使用虚拟化后的优势:
每台物理机上可以同时运行多个虚拟机,每个虚拟机上又可以运行一个操作系统,硬件资源利用率得到了有效提高。并且由于虚拟化技术实现了软
硬件的解耦合,虚拟化可以不受当前服务器的限制,在集群范围内实现业务的在线动态迁移,并且在迁移过程中可以做到业务无中断、用户无感知。
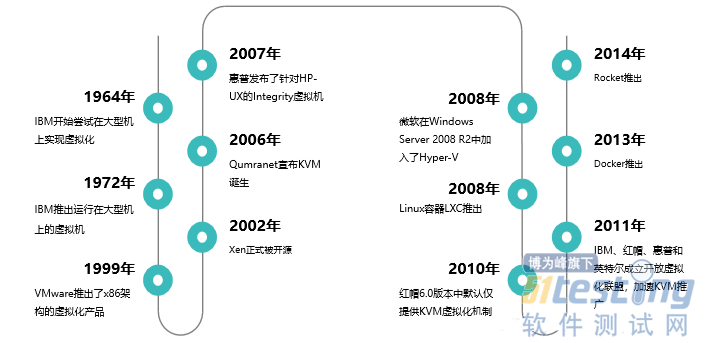
2、计算虚拟化发展史
1964年,“蓝色巨人”IBM就开始尝试在大型机上实现虚拟化,它们的分时系统,将CPU占用切分为多个极短(1/100sec)的时间片,每一个时间片都执行着不同的任务。通过对这些时间片的轮询,就可以将一个CPU虚拟化(伪装)成多个虚拟CPU;
在1972年的时候,IBM正式将system370机的分时系统命名为虚拟机;
1990年,IBM推出的system390机支持逻辑分区,将一个CPU分为若干份(最多10份),而且每份CPU都是独立的,也就是说,一个物理CPU可以逻辑地分为 10个CPU。
1999年,VMware推出了最早的能在x86架构上运行的虚拟化产品;
20世纪 90年代,伦敦剑桥大学的Lan Pratt和Keir Fraser在一个叫做Xenoserver的研究项目中,开发了Xen虚拟机。作为Xenoserver的核心,Xen虚拟机负责管理和分配系统资源,并提供必要的统计功能;
2002年Xen正式被开源,并先后推出了1.0和2.0版本。在这之后,Xen作为虚拟化解决方案,开始被诸如Redhat、Novell和Sun的Linux发行版集成。
除了Xen,另外一个就是大名鼎鼎的KVM,KVM的开发人员并没有选择从底层开始重新写一个Hypervisor,而是选择基于 Linux kernel,通过加载新的模块使Linux Kernel 本身变成一个Hypervisor。
2006年10月,在完成基本功能、动态迁移以及主要的功能和性能的优化后,Qumranet正式对外宣布KVM的诞生。同年10月,KVM模块的源代码被正式纳入Linux Kernel,成为内核源代码的一部分;
2008年9月4日,Redhat公司出人意料地出资1亿700百万美金,收购了Qumranet,成为了KVM开源项目的新东家。得益于此次收购,Redhat公司有了自己的虚拟机解决方案,于是开始在自己的产品中用KVM替换Xen;
2010年11月,Redhat公司推出了新的企业版Linux——RHEL 6,该发行版集成了最新的KVM虚拟机,替换了在RHEL 5.x系列中集成的Xen。
当x86架构虚拟化发展地如火如荼时,一种轻量级的虚拟化也在慢慢发展着,那就是容器。1979年的UNIX chroot,后来经过多年的发展,直到2008年Linux推出了LXC,也就是Linux Containers,它是第一套完整的Linux容器管理实现方案。
2013年,推出了Docker容器项目。Docker在起步阶段同样使用LXC,之后将其替换为自己的libcontainer库。Docker引入了一整套与容器管理相关的生态系统。其中包括一套高效的分层式容器镜像模型、一套全局及本地
容器注册表、一个精简化REST API以及一套命令行界面等等。
2014年,Rocket推出,它最初是由CoreOS开发的,专门用于解决Docker中存在的部分缺陷。在满足安全性与生产要求能力上超越Docker。更重要的是,其基于App Container规范,并使其成为一项更为开放的标准。
3、计算虚拟化的分类
运行虚拟机的物理主机称为宿主机,即Host Machine
宿主机安装运行的操作系统称为宿主机操作系统,即Host OS
运行在宿主机上的虚拟机称为客户机,即Guest Machine
虚拟机安装运行的操作系统称为客户机操作系统,即Guest OS
位于Host OS和Guest OS之间的是所有虚拟化技术的核心——Hypervisor,也可以称为VMM(Virtual Machine Monitor)。
在物理架构中,主机只有两个层次,即硬件层Host Machine和操作系统层Host OS,应用安装在Host OS上;在虚拟化架构中,主机分为三个层次,硬件Host Machine,其上为虚拟机监视器Hypervisor,再上为虚拟机Guest Machine及其操作系统Guest OS,应用安装在Guest OS上。在一个Host Machine上可以创建并运行多个Guest Machine。
根据Hypervisor 的不同类型,我们将虚拟化分为I型和II型两种;
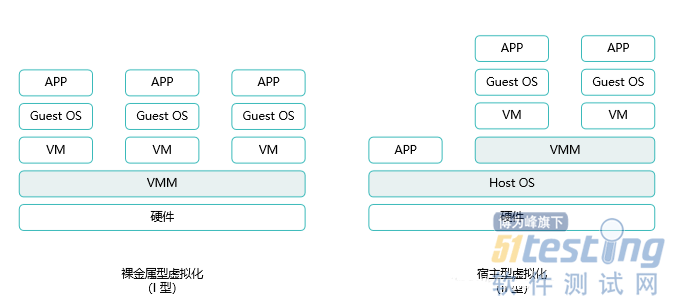
I型虚拟化,也称裸金属虚拟化,Hypervisor直接调用硬件资源,不需要底层Host-OS,Hypervisor主要实现两个基本功能:首先是识别、捕获和响应虚拟机发出的CPU特权指令或保护指令;其次,它负责处理虚拟机队列和调度,并将物理硬件的处理结果返回给相应的虚拟机。
Hypervisor负责管理所有的资源及虚拟环境。VMM可以看作是一个为虚拟化而生的完整操作系统,管理所有资源(CPU、内存和I/O设备)。VMM承担管理资源的重任,并向上提供虚拟机VM 用于运行Guest OS的环境,因此VMM还负责虚拟环境的创建和管理。
具有以下特点:虚拟机不依赖于操作系统,支持多种操作系统和多种应用。
II型虚拟化,也称宿主型虚拟化,此模型的物理资源由Host OS(例如Windows,Linux 等)管理,实际的虚拟化功能由VMM提供,而VMM作为底层操作系统(Windows或Linux等)上的一个普通应用程序,通过其创建相应的虚拟机,共享底层服务器资源。VMM通过调用Host OS的服务来获得资源,实现CPU、内存和I/O设备的虚拟化。VMM创建出虚拟机VM后,通常将VM作为 Host OS的一个进程参与调度。
具有以下特点:简单、易于实现。安装和运行应用程序依赖于主机操作系统对设备的支持。管理开销较大,性能损耗大。
两者公有的特点:分区,隔离,封装和独立的特点
分区与隔离不难理解,分区是每个操作系统只能看到虚拟化层为其提供的“虚拟硬件”(虚拟网卡、CPU、内存等),使它误以为运行在自己的专用服务器上,虚拟机之间彼此互相不影响;隔离主要是为了安全考虑以及性能。
封装就意味着将整个虚拟机(硬件配置、BIOS配置、内存状态、磁盘状态、CPU 状态)储存在独立于物理硬件的一小组文件中。只需复制几个文件就可以随时随地根据需要复制、保存和移动虚拟机。
虚拟机封装为独立文件后,虚拟机迁移只需要把虚拟机设备文件和配置文件或磁盘文件复制到另一台主机上运行即可,而不用关心底层的硬件类型是否兼容,这就是相对硬件的独立性。
4、计算虚拟化
计算虚拟化根据虚拟机组成的设备类型包含CPU虚拟化、内存虚拟化和IO虚拟化。
(1)CPU虚拟化
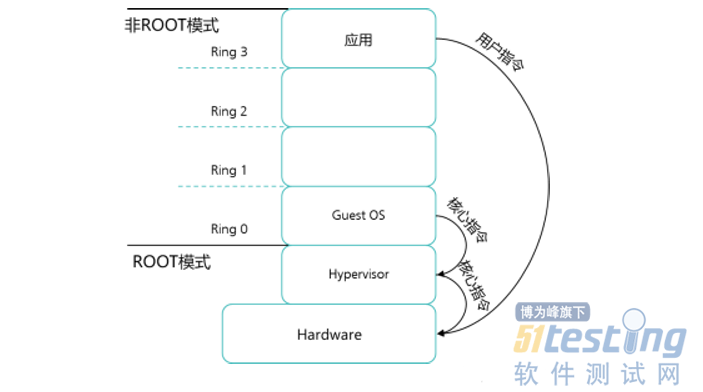
先了解一下CPU的分级保护域,在这种模式中,CPU被分成4个环——Ring0、Ring1、Ring2和Ring3,其中Ring0的权限最高,Ring3最低。Ring0的权限可以直接操作硬件,一般只有操作系统和驱动会允许拥有此权限。Ring3的权限最低,所有程序都可以拥有此权限。这么设置的原因无非也是为了安全,以防止恶意程序直接调用硬件资源。
操作系统所发出的指令分为两种,特权指令和普通指令
特权指令:是指用于操作和管理关键系统资源的指令,这些指令只在最高特权级上才能够运行,即必须在Ring 0级别上才能运行的指令;
普通指令:与特权指令相对的是普通指令,这些指令在CPU普通权限级别上就能够运行,即在Ring 3级别上就可以运行的指令。
而在虚拟化环境中,还有一种特殊指令被称为敏感指令 是指修改虚拟机的运行模式或宿主状态的指令,将Guest OS中原本需要在Ring 0模式下才能运行的特权指令剥夺特权后,交给VMM来执行的指令。
大型机CPU虚拟化采用的方法是“特权解除(Privilege deprivileging)”和“陷入模拟(Trap-and-Emulation)”, 该方法也被称为经典虚拟化方式。基本原理是,将Guest OS运行在非特权级(即“特权解除”),而将VMM运行在最高特权级(即完全控制系统资源)。
如果虚拟机Guest OS发出特权操作指令怎么执行呢?它解除 Guest OS的特权后,Guest OS的大部分指令仍可以在硬件上直接运行,只有当执行到特权指令时,才会陷入到 VMM模拟执行(陷入-模拟)。由VMM代替虚拟机向真正的硬件CPU发出特权操作指令。
定时器中断机制
如图,虚拟机1发送特权指令1到虚拟机监视器VMM,此时触发中断,虚拟机监视器VMM会将虚拟机1发送的特权指令1陷入到虚拟机监视器VMM中进行模拟,再转换成CPU的特权指令1’,虚拟机监视器VMM根据调度机制调度到硬件CPU上执行,并返回结果给虚拟机1。
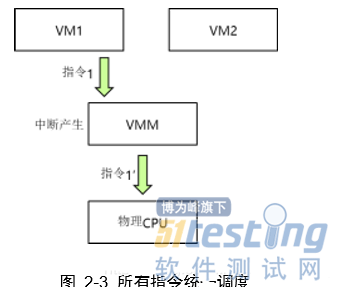
当虚拟机1和虚拟机2同时发送特权指令到虚拟机监视器VMM时,指令都被陷入模拟,虚拟机监视器VMM调度机制进行统一调度。首先执行指令1’,然后再执行指令2’。 所以采用定时器中断机制以及特权解除—陷入模拟的方法可以成功实现CPU的虚拟化功能。
为什么需要中断机制?(学校操作系统课程中会学习)
CPU在程序运行时系统外部、系统内部或当前运行的程序本身若出现紧急事件,CPU立即中止当前运行的程序,自动转入相应的处理程序(中断服务程序), 待处理完后,再返回原来的程序运行,这整个过程称为程序中断。
随着x86主机性能越来越强,如何将虚拟化技术应用到x86架构成为实现x86服务器虚拟化的主要问题,而大型机使用的CPU经典虚拟化方式不能移植到x86服务器上,这是因为两者CPU的不同。
大型机(包括后来发展的小型机)是PowerPC架构,即精简指令集RISC计算机架构。RISC架构的CPU指令集中,虚拟机特有的敏感指令是完全包括在特权指令中的,在虚拟机操作系统解除特权后,特权指令和敏感指令都可以被正常陷入-模拟并执行,因为特权指令包含敏感指令,所以RISC架构的CPU采用特权解除和陷入模拟是没有问题的。但是x86架构的CPU指令集是不同于RISC架构的CISC架构,如图所示

基于x86的CISC指令集有19条敏感指令不属于特权指令的范畴,这部分敏感指令运行在CPU的Ring 1用户态上。这会带来什么问题呢?显然,当虚拟机发出这19条敏感指令时,由于指令不属于特权指令,因而这些敏感指令不能陷入-模拟被虚拟机监视器(VMM)捕获,因此x86无法使用“解除特权”“陷入-模拟”的经典虚拟化方式实现X86架构的虚拟化。
IT架构师们想出了解决这个问题的三种方法。它们分别是:全虚拟化、半虚拟化以及硬件厂商提出的硬件辅助虚拟化。
全虚拟化解决方案
将所有虚拟机发出的操作系统请求转发到虚拟机监视器(VMM),虚拟机监视器对请求进行二进制翻译(Binary Translation),如果发现是特权指令或敏感指令,则陷入到VMM模拟执行,然后调度到CPU特权级别上执行;如果只是应用程序指令则直接在CPU非特权级别上执行。这种方法由于需要过滤所有虚拟机发出的请求指令,因而被称为全虚拟化方式。
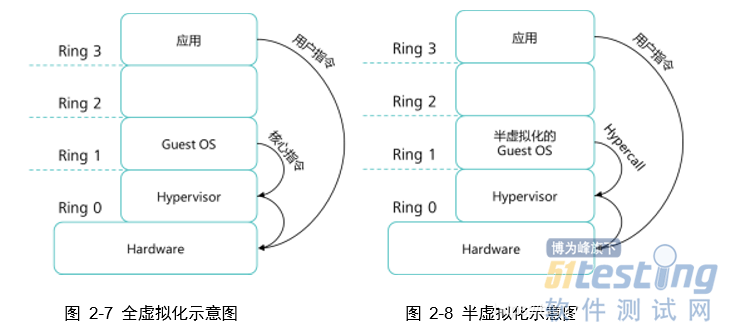
半虚拟化解决方案
修改虚拟机操作系统Guest OS,让虚拟机操作系统能够意识到
自己是被虚拟化的,虚拟机操作系统会“超级调用” (Hypercall)Hypervisor层来替换虚拟化中的敏感指令,从而实现虚拟化,而其它应用程序等非敏感或非特权请求则直接在CPU非特权级别上执行。
半虚拟化所具有的优点是:半虚拟化中的 Guest OS可以同时支持多个不同的操作系统,并提供与原始系统相近的性能。但缺点是:半虚拟化中的Host OS只支持修改开源的操作系统,如Linux,而对于未开源的如Windows系统,则无法实现半虚拟化。此外,被修改过的虚拟机操作系统Guest OS可移植性较差。
硬件辅助虚拟化解决方案
目前主流的x86主机的CPU都支持硬件虚拟化技术,即Intel推出了VT-x(Intel Virtualization Technology)的CPU,AMD也推出了AMD-V的CPU。VT-x和AMD-V,这两种技术都为CPU增加了新的执行模式——root模式,可以让虚拟机监视器VMM运行在root模式下,而root模式位于CPU指令级别Ring 0下。特权和敏感指令自动在Hypervisor上执行,所以无需全虚拟化或半虚拟化技术。这种通过硬件辅助虚拟化解决虚拟化漏洞,简化VMM的工作,不需要半虚拟化和二进制翻译的方法,被称为CPU的硬件辅助虚拟化技术。
(2)内存虚拟化
内存虚拟化遇到的一个问题是:如何分配内存地址空间?
物理主机在使用内存地址空间时,要求满足如下两点要求:内存地址都是从物理地址0开始的 ,内存地址空间都是连续分配的。
要求内存地址空间都从物理地址0开始,因为物理地址为0的内存地址空间只有一个,无法同时满足所有虚拟机使用的内存都从0开始的要求;其次是内存地址连续分配问题。即使可以为虚拟机分配连续的物理地址,但是内存使用效率不高,缺乏灵活性。
内存虚拟化就是把物理机的真实物理内存统一管理,包装成多份虚拟的内存给若干虚拟机用。内存虚拟化技术的核心在于引入一层新的地址空间——客户机物理地址空间,客户机(Guest)以为自己运行在真实的物理地址空间中,实际上它是通过VMM访问真实的物理地址的,在VMM中保存的是客户机地址空间和物理机地址空间之间的映射表。

内存虚拟化的内存地址转换涉及到三种内存地址,即虚拟机内存地址(Virtual Memory Address,即VA)、物理内存地址(Physical Memory Address,即PA)和机器内存(Machine Memory Address,即MA)。虚拟机Guest OS控制虚拟地址到客户内存物理地址的映射(VA→PA),但是虚拟机Guest OS不能直接访问实际机器内存,因此Hypervisor需要负责映射客户物理内存到实际机器内存(PA→MA)。
(3)I/O虚拟化
物理服务器上会创建出许许多多的虚拟机,并且每台虚拟机都需要访问物理主机的I/O设备。但I/O设备的数量毕竟是有限的,为了满足多个虚拟机共同使用I/O设备的需求,就需要虚拟机监视器VMM的参与。
全虚拟化:通过VMM为虚拟机模拟出一个与真实设备类似的虚拟I/O设备,当虚拟机对I/O设备发起I/O请求时,VMM截获虚拟机下发的I/O访问请求,再由VMM将真实的访问请求发送到物理设备进行处理。
半虚拟化:它需要建立一个特权级别的虚拟机,即特权虚拟机。半虚拟化方式要求各个虚拟机运行前端驱动程序,当需要访问 I/O设备时,虚拟机通过前端驱动程序把I/O请求发送给特权虚拟机,由特权虚拟机的后端驱动收集每个虚拟机所发出的I/O请求,再由后端驱动对多个I/O请求进行分时分通道处理。特权虚拟机运行真实的物理I/O设备驱动,将I/O请求发送给物理I/O设备,I/O设备处理完成后再将结果返回给虚拟机。
硬件辅助虚拟化:将 I/O设备驱动直接安装
在虚拟机操作系统中,不需要对操作系统做任何修改即可使用,这就使得虚拟机访问I/O硬件所需的时间与传统PC机的访问时间相同。硬件辅助虚拟化就相当于一个智能的信息收集、处理平台,用户的意见请求可以直接向该平台提交,并自助完成业务处理,无需人工干预。因此硬件辅助虚拟化在I/O性能上远远超过全虚拟化和半虚拟化方式。但硬件辅助虚拟化需要特殊的硬件支持。
5、主流的计算虚拟化
CPU虚拟化,内存虚拟化,I/O虚拟化,都可以进行物理资源的复用,这样一台物理主机可以运行多台虚拟服务器,提高了硬件的利用率。而且由于虚拟服务器被逻辑划分成一个文件或文件夹,通过移动这些文件或文件夹,就可以提高在虚拟机上的业务的可靠性,所以在云计算中,主要用虚拟化技术来实现IaaS的云服务,这也是HCIA的学习目标。
而云计算不仅仅是IaaS,还包括PaaS和SaaS,有一部分PaaS和SaaS是基于虚拟化来实现的,还有一部分是基于物理硬件+分布式计算来实现的。
云计算是为用户提供随时随地可获取的IT服务,是一种商业模式或者服务模式,而虚拟化是一种技术手段,是云计算实现的重要手段之一。
主流的虚拟化技术有很多,一般分为开源和闭源两类。开源的虚拟化包括KVM和Xen,闭源的虚拟化包括微软的Hyper-v、VMware的vSphere、华为的FusionSphere等。
在开源的虚拟化技术中,Xen和KVM平分秋色,KVM是全虚拟化,而Xen同时支持半虚拟化和全虚拟化。KVM是Linux内核中的一个模块,用来实现CPU和内存的虚拟化,是Linux的一个进程,而其它的I/O设备(网卡、磁盘等)需要QEMU来实现。Xen与KVM不同,它直接运行在硬件上,然后在其之上运行虚拟机,Xen中的虚拟机分为两类:Domain0和DomainU,Domain0是一个特权虚拟机,具有直接访问硬件和管理其它普通虚拟机DomainU的权限,在其它虚拟机启动前,Domain0需要先启动。DomainU是普通虚拟机,不能直接访问硬件资源,所有的操作都需要通过前后端驱动的方式转给Domain0,再由Domain0完成具体的操作后将结果返回给DomainU。
二、KVM简介
KVM,全称是Kernel-based Virtual Machine(基于内核的虚拟机),是一种典型的II型全虚拟化,它之所以叫做基于内核的虚拟机,是因为KVM本身是一个Linux内核模块,当安装有Linux系统的物理机安装了这个模块后,就变成了Hypervisor,而且还不会影响原先在该Linux上运行的其它应用程序,而且每个虚拟机都是进程,可以直接用kill命令杀掉。
一个普通的Linux安装了KVM模块后,会增加三种运行模式:
Guest Mode:此模式主要是指虚拟机,包括虚拟机的CPU、内存、磁盘等虚拟设备,该模式被置于一种受限的CPU模式下运行;
User Mode:用户空间,此模式下运行的主要是QEMU,它用来为虚拟机模拟执行I/O类的操作请求;
Kernel Mode:内核空间,此模式下可以真正操作硬件,当Guest OS执行I/O类操作或特权指令操作时,需要向用户模式提交请求,然后由用户模式再次发起硬件操作请求给内核模式,从而真正操作硬件。
KVM体系一般包括三部分:KVM内核模块、QEMU和管理工具,其中KVM内核模块和QEMU是KVM的核心组件:
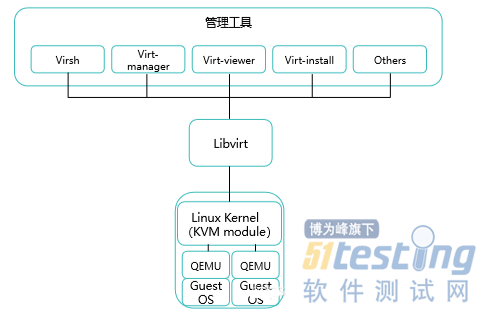
除了KVM,其它的虚拟化产品几乎都是类似的架构。
KVM内核模块是KVM虚拟机的核心部分,其主要功能是初始化CPU硬件,打开虚拟化模式,然后将Geust Machine运行在虚拟机模式下,并为虚拟客户机的运行提供一定的支持。
KVM本身不能实现任何模拟功能,它仅仅是提供了一个/dev/kvm接口,这个接口可被宿主机用来主要负责vCPU的创建、虚拟内存的地址空间分配、vCPU寄存器的读写以及vCPU的运行。
而一个虚拟机除了CPU和内存外,还需要网卡、硬盘等其它的I/O设备,这就是QEMU的作用了,KVM核心模块和QEMU一起才能构成一个完整的虚拟化技术。
其实QEMU原本不是KVM的一部分,它是一个通用的开源的使用纯软件来实现的虚拟化模拟器,Guest OS以为自己在与硬件进行交互,其实真正交互的是QEMU,然后再通过QEMU与硬件交互,这就意味着所有与硬件的交互都需要经过QEMU,所以使用QEMU进行模拟的性能比较低。QEMU本身可以模拟CPU和内存,在KVM中,只使用QEMU来模拟IO设备,KVM的开发者将其改造成了QEMU-KVM
在QEMU-KVM中,KVM运行在内核空间,QEMU运行在用户空间,Guest OS下发指令时,与CPU和内存相关的指令会通过QEMU-KVM中的/ioctl调用/dev/kvm,从而将这部分指令交给内核模块来完成,从QEMU的角度来看,这样做也可以加速虚拟化。其它的I/O操作则由QEMU-KVM中的QEMU来实现。
QEMU-KVM还提供了原生工具来对虚拟机的创建、修改和删除等进行管理,Libvirt是目前使用最为广泛的管理 KVM虚拟机的工具和API。
在云计算中,Hypervisor种类众多,每个Hypervisor都有自己独特的管理工具,同时由于Hypervisor不统一,也没有统一的编程接口来对它们进行管理,对云计算的环境影响很严重。Libvirt作为管理工具和Hypervisor的中间层,向下可以对接各种Hypervisor,比如KVM、Xen等,向上可以提供各种语言的API,而且它对上层的用户来说是完全透明的。
此外,如果使用QEMU模拟一个Windows虚拟机网卡,我们在系统上看到该网卡的速率仅为100M,当某些应用对网卡速率有要求时,就不能再使用QEMU了,我们需要引入一个新的技术——Virtio,用了Virtio,模拟同样一个 Windows虚拟机网卡,该网卡的速率可以提升到10G。
没有virtio时,虚拟机磁盘操作如何实现?
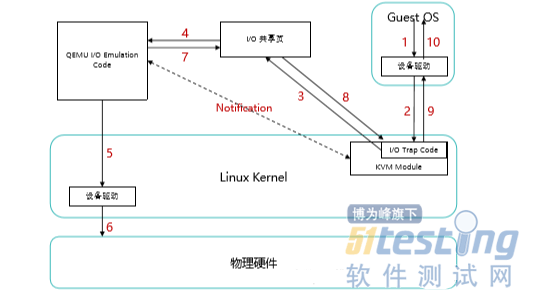
1 虚拟机中的磁盘设备发起一次I/O操作请求
2 KVM模块中的I/O Trap Code(I/O捕获程序)将这个I/O操作请求捕获到,进行相应的处理,然后将处理后的请求放到I/O共享页中
3 KVM模块会通知QEMU,告诉它有新的I/O操作请求放到了共享页中;
4 QEMU收到通知后,到共享页中获取该I/O操作请求的具体信息;
5 QEMU对该请求进行模拟,同时根据I/O操作请求的信息调用运行在内核态的设备驱动,进行真正的I/O操作;
6 通过设备驱动对物理硬件执行真正的I/O操作;
7 QEMU将执行后的结果返回到共享页中,同时通知KVM模块已完成此次I/O操作;
8 I/O捕获程序从共享页中读取返回的结果;
9 I/O捕获程序将操作结果返回给虚拟机;
10 虚拟机将结果返回给发起操作的应用程序。
使用Virtio时,具体的操作流程如下:
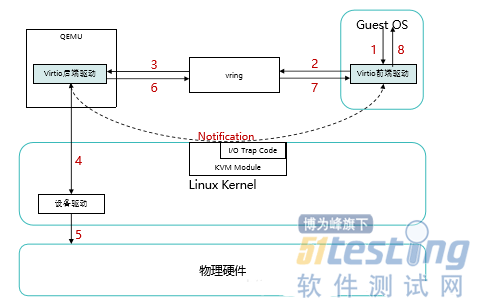
1 同样是由虚拟机发起I/O操作请求;
2 与使用默认模型不一样,这个I/O操作请求不会经过I/O捕获程序,而是直接以前后端的形式放到环形缓冲区,同时KVM模块通知后端驱动;
3 QEMU到环形缓冲区获取到操作请求的具体信息;
4 后端驱动直接调用真实的物理设备驱动进行具体的I/O操作;
5 由真实的设备驱动完成I/O操作;
6 QEMU将处理结果返回到环形缓冲区,并由KVM模块通知前端驱动;
7 前端驱动从环形缓冲区获取到此次I/O操作的结果;
8 前端驱动将结果返回给发起操作的应用程序。
三、FusionCompute简介
华为FusionSphere虚拟化套件是业界领先的虚拟化解决方案,能够帮助客户带来如下价值:
帮助客户提升数据中心基础设施的资源利用率。
帮助客户成倍缩短业务上线周期。
帮助客户成倍降低数据中心能耗。
利用虚拟化基础设施的高可用和强恢复能力,实现业务快速自动化故障恢复,降低数据中心成本,增加系统应用的正常运行时间。
FusionSphere虚拟化套件通过在服务器上部署虚拟化软件,使一台物理服务器可以承担多台服务器的工作。通过整合现有的工作负载并利用剩余的服务器,以部署新的应用程序和解决方案实现较高的整合率。
FusionCompute是FusionSphere虚拟化套件中的必选组件,是云操作系统软件,主要负责硬件资源的虚拟化,以及对虚拟资源、业务资源、用户资源的集中管理。它采用虚拟计算、虚拟存储、虚拟网络等技术,完成计算资源、存储资源、网络资源的虚拟化。同时通过统一的接口,对这些虚拟资源进行集中调度和管理,降低业务的运行成本,保证系统的安全性和可靠性,协助运营商和企业构筑安全、绿色、节能的云数据中心。
FusionCompute由两部分组成:CNA(Computing Node Agent,计算节点代理)VRM(Virtual Resource Manager,虚拟资源管理器)。
UVP是华为研发的统一虚拟化平台,它与KVM和Xen一样,也是一款Hypervisor。FusionCompute的Hypervisor使用裸金属架构,直接在硬件上安装虚拟化软件,将硬件资源虚拟化。由于使用了裸金属架构,FusionCompute可为用户带来接近服务器性能的、高可靠和可扩展的虚拟机。
FusionCompute的架构和KVM非常相似,其中***VRM相当于KVM中的管理工具***,管理员和用户可以通过图形化的Portal对FusionCompute进行管理和使用。CNA相当于KVM中QEMU+KVM模块,主要提供虚拟化功能,通常是以集群的方式部署,将集群内的计算、存储和网络资源虚拟化成资源池供用户使用。同样,CNA也是基于Linux操作系统的。
VRM主要提供以下功能:
管理集群内的块存储资源。
管理集群内的网络资源(IP/VLAN),为虚拟机分配IP地址。
管理集群内虚拟机的生命周期以及虚拟机在计算节点上的分布和迁移。
管理集群内资源的动态调整。
通过对虚拟资源、用户数据的统一管理,对外提供弹性计算、存储、IP等服务。
通过提供统一的操作维护管理接口,操作维护人员通过WebUI远程访问 FusionCompute对整个系统进行操作维护,包含资源管理、资源监控、资源报表等
CNA主要提供以下功能:
提供虚拟计算功能。
管理计算节点上的虚拟机。
管理计算节点上的计算、存储、网络资源
总结:
VRM和CNA都有管理的作用,CNA管理的是本节点上的虚拟机和资源,而VRM是从集群或者整个资源池的层面进行管理。如果VRM对某个虚拟机进行修改或者其它生命周期的操作时,需要将命令下发给CNA节点,再由CAN去执行。操作完成后,CNA再把结果返回给VRM,由 VRM记录到数据库中。
FusionCompute除了支持华为自己的硬件产品外,还支持其它基于x86硬件平台的多种服务器,并兼容多种存储设备,可供企业灵活选择。目前单个集群最大可支持64个主机,3000台虚拟机。FusionCompute具有完善的权限管理功能,可根据不同的角色、权限等,提供完善的权限管理功能,授权用户对系统内的资源进行管理。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












