

2. 非功能性测试
·性能测试
性能测试:是大数据测试过程中的一种重要手段,它通常是验证在大数据量的情况下数据处理和响应能力。通过性能测试能够很好地检测出大数据系统的业务处理瓶颈、资源使用不足等问题。常见的性能测试验证参数除了内存使用率、吞吐率、任务完成时间外还有以下几个方面:
1) 数据存储:大数据量情况下数据如何存储在不同的节点中,是否有表漏写分区。
2) 并发性:大并发场景下的数据读取、写入、计算等性能,有多少个线程可以执行写入和读取操作。
3) JVM参数:堆大小,GC收集算法等。
4) 缓存:调整缓存设置“行缓存”和“键缓存”。
5) 超时:连接超时值,查询超时值、任务执行超时等。
6) 消息队列:消息速率,大小等。
·安全测试
考虑各公司或地区政策定义的数据保密项,需要对特殊数据进行加密;数据权限不仅需要从库、表和文件层面考虑安全性,还需要从数据行、列等更细粒度考虑权限设置问题;对数据实施读取、下载、管理权限控制,保证数据不能处于安全范围外。
·易用性测试
易用性测试是指测试数据能否较好的被用户理解和使用。数据的易用性可以分为两方面:是否易于理解和使用。
易于理解是指对数据的定义是否被行业认可,是否存在团队与团队之间、用户与开发者之间理解的不一致。
易于使用通常指数据存储格式是否易于后续使用。比如数据精度需要统一,不能出现类似12.12345678912345这类不易读、不易处理的数据;数据值太大时,考虑使用合适的单位换算后显示;字符串要求合理拼接,不要出现大json类型,避免在后续使用中带来性能问题。
·兼容性测试
包括不同数据库的兼容和不同数据类型的兼容等。
6.2.3 ETL测试场景
下面列出三个ETL测试场景:HiveQL测试场景、源表目标表验证场景、MR测试场景,来说明如何将功能测试方法应用到实际业务测试场景中。
1. HiveQL测试场景
以下是一段HiveQL的业务代码,它的业务需求转变后的代码逻辑如下所示:
从sdw.t05_student_info_h表中查询出7个字段(unique_id、studentNo、courseName、term、score、creditHour、start_dt)的值并插入表tmp.t05_student_info_tmp01。需要满足where查询条件如下:start_dt的值不大于给定的参数etl_dt-1且end_dt的值不小于给定的参数etl_dt-1,且需要去除studentNo为空的记录。脚本需要支持重跑,这里的重跑指的是重复运行SQL语句,目标表得到结果一致。下面给出被测试业务代码及常见测试用例。
insert?overwrite?table?tmp.t05_student_info_tmp01 select unique_id --' 唯一编号' ,studentNo -- ' 学号', ,courseNo --' 课程名称', ,term --' 开课学期', ,score -- ' 成绩', ,creditHour -- ' 所得学分', ,start_dt -- '开课时间' from sdw.t05_student_info_h where start_dt<=date_sub('${hivevar:etl_dt}',1) and end_dt>date_sub('${hivevar:etl_dt}',1) and studentNo is not NULL 1 and studentNo != ''; |
测试用例1:代码及字段注释检查
检查发现代码中所有字段都有注释;该代码非关键步骤,可以不添加代码描述注释。检查结果符合需求,测试用例通过。
测试用例2:表名正确性
检查表名,验证源表和目标表的名称是否符合需求。检查结果符合需求,测试用例通过。
测试用例3:字段正确性
检查查询出的各个字段是否符合需求。发现需要查询的是“courseName”字段,但是查出来的是“courseNo”字段,不符合需求,测试用例不通过。
测试用例4:数据过滤逻辑
检查要求的where条件是否满足需求。发现 end_dt 的查询条件不正确,应该是“end_dt >=”。不符合需求,测试用例不通过。
测试用例5:脏数据处理
检查要求的脏数据是否正确去除。发现空值和NULL值已经过滤。符合需求,测试用例通过。
测试用例6:计算函数使用
代码中使用的函数date_sub为传入etl_dt值减去1,与需求一致。符合预期,测试用例通过。
测试用例7:数据写入方式
代码中使用的是insert overwrite,而不是insert into。insert into操作是以追加的方式向hive表尾部追加数据,而insert overwrite操作则是直接重写数据,即先删除hive表的数据,再执行写入操作。由于需求要求脚本支持重跑,所以需要使用insert overwrite来保证每次重跑时原数据被覆盖。符合需求,测试用例通过。
2.源表到目标表验证场景
该场景侧重验证目标表结果是否符合预期,并没有给出数据流转代码实例,在实际项目测试中是需要关注数据流转的代码逻辑的。源表EMP经过简单的ETL过程(实际ETL过程比案例场景复杂的多,为方便说明问题,此处仅进行简单示意)得到目标表EMP_SALARY,源表和目标表的列信息及转换规则见表6-3:
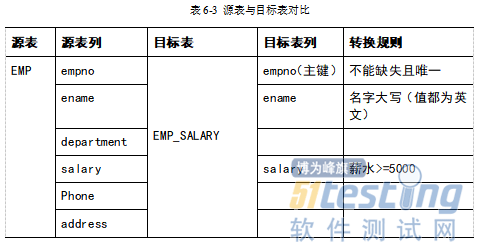
测试用例1:测试源表中数据是否正确映射到目标表,数据的信息和数据量是否正确,主要验证数据的完整性。
SELECT * FROM ( SELECT E.empno, upper(E.ename) AS upper_ename, E.salary FROM DEFAULT.EMP E WHERE E.salary >= 5000 ) a LEFT JOIN DEFAULT.EMP_SALARY b ON (a.empno?=?b.empno AND a.upper_ename = b.ename AND a.salary = b.salary) WHERE b.empno IS NULL; |
执行上述SQL后,期望得到结果为0条。
版权声明:51Testing软件测试网获得人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。












