

jp@gc - Bytes Throughput Over Time:不同时间吞吐量展示(图表)
聚合报告里,Throughput是按请求个数来展示的,比如说1.9/sec,就是每s发送1.9个请求;而这里的展示是按字节Bytes来展示的图表
jp@gc - Composite Graph: 混合图表
在它的Graphs里面可以设置多少个图表一起展示,它可以同时展示多个图表
jp@gc - Hits per Second:每秒点击量
jp@gc - PerfMon Metrics Collector:服务器性能监测控件,包括CPU,Memory,Network,I/O等等
jp@gc - Reponse Latencies Over Time:记录客户端发送请求完成后,服务器端返回请求之前这段时间
jp@gc - Reponse Times Distribution: 显示测试的响应时间分布,X轴显示由时间间隔分组的响应时间,Y轴包含每个区间的样本数
jp@gc - Transactions per Second: 每秒事务数,服务器每秒处理的事务数
jp@gc - Reponse Times vs Threads:展示事务响应时间与虚拟用户数之前的对应关系
服务器性能分析:
cpu:
CPU 在操作系统中是运行的根本,CPU的执行速度与性能好坏在很大程度上决定了系统整体的性能的快慢,最开始大部分任务是单线程调度,CPU在同一时间内只能运行一个线程,但随着多处理器技术的成熟,软件架构的深入和复杂度的提升,单处理系统组件在往多处理系统转变,这些都是利用处理器的多核心处理能力的特性来提升系统性能.在做系统性能分析前,首先我们要了解系统处理器的情况,如逻辑处理器,处理器型号,主频率,cache大小,是否支持超线程技术等信息,在知道这些的情况下,才能更好地进行我们系统的性能分析。
除此之外,CPU的使用率也是我们需要关注的很重要指标,当CPU处于满载状态时,很多时候我们要结合系统附带的一些系统监控分析工具,检查相关的系统日志,web服务器日志,DB日志等,结合辅助一些命令如top,free,uptime,sar等辅助分析为什么系统CPU会被完全占用,以及后续的解决优化方案。
memery:内存
在系统性能因素中,内存大小也是影响系统性能的一个非常核心的指标,当可用的内存太小,系统进程会被阻塞中,应用也将会变得非常缓慢,有时候会失去响应,严重的甚至可能会触发系统的OOM(内存溢出)从而引发应用程序被系统给杀死,更严重的情况可能会引起系统重启;当机器的内存太大的时候,有时候也是一种浪费,这时候我们可以考虑做一些缓存服务去提升系统性能。
虚拟内存也是在内存里面我们需要考虑的性能指标,在系统设计中,当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用.那些被释放的空间可能来自一些长时间没什么操作的程序,这些被释放的空间被临时保存到虚拟内存空间中,等到那些程序要运行时,再从虚拟内存中恢复保存的数据到物理内存中.这样,系统总是在物理内存不够时,才进行内存之间的交换,有时可以越过系统性能瓶颈,节省系统升级费用。在做性能分析的时候,我们也要考虑系统有无设置虚拟内存,以及虚拟内存的使用情况。
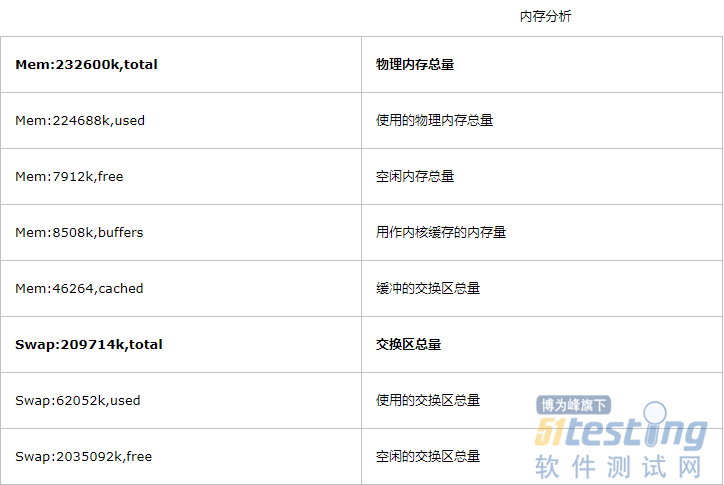
swap:交换分区
DIsks I/O:硬盘
访问应用离不开系统的磁盘数据的读写,I/O读写的性能直接会影响系统程序的性能.读写的性能直接会影响系统程序的性能,磁盘I/O系统是系统中最慢的部分。I/O比较频繁的时候,如果I/O得不到满足会导致应用阻塞.针对I/O的场景模型,我们要考虑的有I/O的TPS,平均I/O数据,平均队列长度,平均服务时间,平均等待时间,IO利用率等指标。
network I/O :网络
系统应用之间的交互,尤其是跨机器之间的,都是要基于网络的,因此网络宽带,响应时间,网络延时,阻塞等都是影响系统性能的因素.假如应用在不稳定和不安全的网络下会导致应用程序的超时,丢弃,阻塞,波动率大,这些在系统中都是不能接受的。我们需要一个可靠的,稳定的,能满足我们应用程序在机器之间畅通无阻地运行,这些需要测试工程师,网络管理员,系统管理员等一起合作把系统的网络完善。
在系统中,我们要考虑对应的网络是否可达,防火墙是否开启,端口访问,带宽是否有被限制,路由的寻址,网络的延时等问题。
TCP:一种网络传输协议
JMX:
EXEC:
TALL:

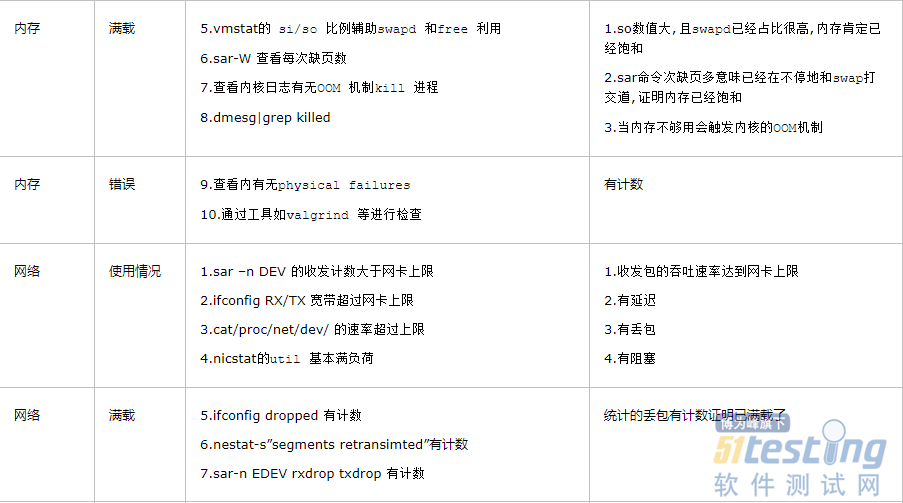

系统负载监控分析实践
uptime命令:主要用于获取主机运行时间和查询Linux系统负载等信息,uptime命令可以显示系统已经运行了多长时间,以及有多少用户登录,快速获取服务器的负荷情况,它信息显示依次为:现在时间,系统已经运行了多长时间,目前有多少登录用户,系统在过去的1分钟,5分钟,15分钟内的平均负载。
1.uptime的系统存活时间越长,意味着系统稳定,我们可以通过uptime查看系统这一段时间有无重启,这也是一种常见分析系统是否稳定的命令
2.通过uptime命令可以得知当前有多少登录用户,但相对来说w命令会更好地显示当前登录用户数的信息。
3.一般系统建议每个CPU内核的当前活动进程数量最好不要大于0.8,证明系统是空闲的,大于1且不小于3的时候,如果系统的其他资源很正常,那么系统的性能也可以接受的.但如果任务数大于5的话,那证明系统性能有问题了.以一个四核CPU的主机为例,当uptime的输出结果超过15,那就意味着当前系统负载非常严重,需要分析当前的进程调度策略,是否有阻塞等,估计此时可能打开运行脚本都会非常缓慢的。
4.系统负载的3个值表示的是系统过去的1分钟,5分钟,15分钟的一个平均值.通过这3个值的信息,我们 可以分析出系统负载的趋势:是否增加,稳固,降低等。
Linux系统性能分析思路和实践
负载uptime命令
CPU top命令
Windows 系统性能分析思路和实践
性能监视器综述:
perfmon 进入性能监视器
中间件Tomcat 监控 Probe
监控项

性能调优常用手段:
1.空间换时间,内存,缓存就是典型的空间换时间的例子.利用内存缓存从磁盘上取出的数据,CPU请求数据直接 从内存中获取,从而获取比从磁盘读取数据更高的效率。
2.时间换空间:当空间成为瓶颈时,切分数据分批次处理,用更少的空间完成任务处理.上传大附件时经常用这种方式。
3.分而治之:把任务切分,分开执行,也方便并行执行来提高效率。
4.异步处理:业务链路上有任务时间消耗较长,可以拆分业务,减少阻塞影响.常见的异步处理机制有MQ(消息队列),目前在互联网应用中大量使用。
5.并行:用多个进程或者线程同时处理业务,缩短业务处理时间,比如我们在银行办理业务时,如果排队人数较多时,银行会加开柜台。
6.离用户更近一些:比如CDN技术,把用户的静态资源放在离用户更近的地方。
7.一切可扩展:业务模块化,服务化,良好的水平扩展能力。
分布式架构的运用给性能带来了革命性的提升,业务流程的调整也会显著提升系统性能,单系统的调优能够压榨出更高的处理能力。
系统的发展:
单体--à集群--à分布式--à分布式集群
单机性能分析与调优
客户端--à应用服务器--à数据库
我们的服务运行在中间件上,中间件与DB运行在操作系统上,操作系统来管理计算机硬件设备(CPU,内存,磁盘,网卡等设备)。
单机性能分析流程:
Client:客户端
Load Machine:负载生成器—模拟用户负载
webserver:提供Web服务的服务器,即我们访问的web页面由此服务器提供服务;一般部署在Nginx,Apache等中间件上。
Middleware:中间件,比如Tomcat,Jboss,WebLogic等
OS:操作系统
System Resource:系统资源
APPserver:应用服务器,实现业务逻辑
DB:数据库服务器
配置优化:
JVM配置优化
连接池:
连接池配置参数
连接池配置多少连接合适
监控连接池
线程池:
缓存机制:
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












