

前言
从宏观的视角来看,软件质量保障有两条路线。第一条路线是形式化方法,这是一种数学方法,它使用逻辑学和集合理论等对软件工程进行建模,并自动生成有理论保证的零bug程序。第二条路线是实验性方法,这是一种工程方法,它将软件开发分解为多个阶段,并通过软件分析和测试来逐一暴露和消灭bug。
形式化方法虽然理论上很漂亮,但是由于各种原因,其实际应用的场景十分稀少。在绝大多数软件项目中,我们走第二条路线,即用工程方法来开发软件,并使用分析和测试技术来保障软件质量。
对于软件质量保障工程,根据具体实现路径不同,又可以分为静态和动态两种方法。所谓静态方法,就是在不执行代码的情况下,通过对代码进行检查和分析来发现bug。所谓动态方法,就是通过执行代码并观察其实际表现来发现bug。
在多数项目中,静态和动态方法并行存在。其中,静态方法通常在开发端进行,更有利于在项目早期发现bug。我们耳熟能详的静态检查工具,例如Coverity,FindBugs, pyflakes,SonarQube等,都可以高效地发现源代码中存在的各种不规范问题,异味,甚至bug。
在静态方法中,有一个软件工程的热门研究方向,即bug预测(prediction)。bug预测的基本思路是从大量现有代码(big code)中学习bug代码的特征,然后构造bug预测模型,用来预测新代码有bug的概率。
相比动态测试,作为静态方法的bug预测具有全自动化,成本低,反馈周期短等优势,吸引着一批批软件工程学者的目光。据调查,bug预测的第一篇论文产生于1976年,迄今已有40多年历史。下图反映了40多年来这一领域在IEEE数据库中收录论文的数量变化。
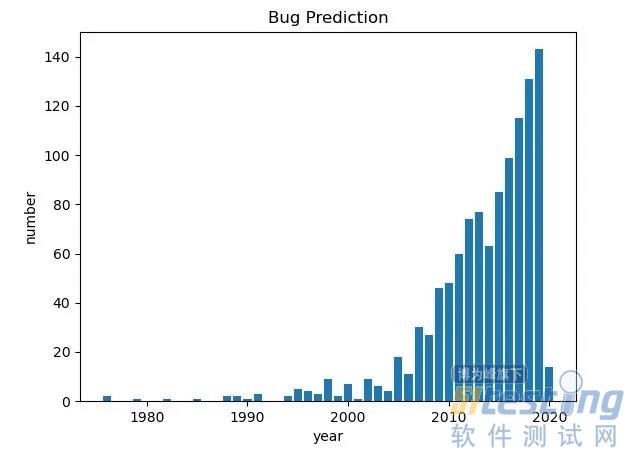
由图可知,近20年来,bug预测领域的研究热度持续增长。bug预测的研究热度能持续这么久,其实也反映了bug预测问题的挑战性和艰巨性。那么,40多年来,bug预测研究是如何变迁的呢?这里,肖哥梳理文献,将bug预测研究分为四个阶段,并介绍每个阶段的特点。
阶段一:基于代码metrics的文件级bug预测
最传统的bug预测研究的问题是:给定一个源代码文件,预测该文件有bug的概率(回归),或者判断该文件是否有bug(分类)。那么,如何进行预测呢?通过对一些软件项目的bug记录进行分析后发现,代码的某些metrics与源文件有没有被测出bug存在一定的关联关系。
这里的代码metrics有代码长度,运算复杂度,圈复杂度等数十种。包含这些metrics的开源数据集在网上可以找到。基于代码metrics的bug预测是典型的机器学习问题,相关研究论文层出不穷。
这个阶段的bug预测模型以有监督机器学习为主,代表性算法有逻辑回归,K-近邻,SVM,朴素贝叶斯等。然而,这些算法所基于的特征受软件项目的实际情况,例如编程语言、开发者水平、业务复杂度等影响较大,导致基于开源数据集训练的模型难以在实际项目中使用。
有没有健壮性和普适性更好的特征呢?有研究发现,与五花八门的metrics相比,预测源文件是否有bug可以另辟蹊径。
根据经验,bug的分布也符合著名的"二八原则",即80%的bug分布在20%的源文件中。通过挖掘源文件历史上所产生的bug记录,我们可以知道哪些源文件属于这20%的部分,而正是这些文件,在未来会有大概率产生新bug。
这就是基于历史记录的文件级bug预测思想。这个思想符合直觉,通用性好,一经提出便开启了软件bug预测的新阶段。
阶段二:基于历史记录的文件级bug预测
得益于版本控制系统(例如SVN,Git)的应用,我们可以得到源文件从创建至今所有的改动记录。软件开发最佳实践,提倡开发者在提交代码改动时,使用模板化commit message来描述改动的内容。
例如,如果代码改动是为了修复一个bug,那么在commit message中会有相应字段说明这是一种修复bug的改动,并且会附上bug的ID或链接。
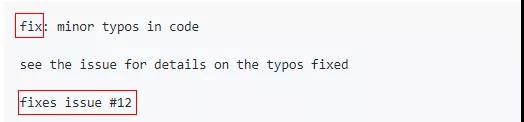
对于应用了模板化commit message的项目来说,我们可以从版本控制系统日志中知道修复每个bug时改动了哪些源文件,据此可以统计出每个源文件历史上产生的bug数量,从而识别出一批在过去产生bug最多的源文件。对于这些文件,我们有理由相信它们在未来会继续产生新bug。
基于历史记录的文件级bug预测算法,是bug预测领域少有的在工业界有过落地的研究成果。谷歌就曾经在其研发系统中集成了这一功能。当然,谷歌使用的是一个优化后的版本。
谷歌发现,原始算法存在一个问题。有些源文件过去确实曾经产生过许多bug,但是后来经过重构和优化,就没有再出现bug。此时,由于历史记录不会消失,原始算法仍然会将这些源文件预测为高概率有bug。这是明显的误报(False Positive)。
如何解决这个问题呢?谷歌的做法是:给每个bug增加一个权重,它的值随着时间的流逝而衰减。离当前时间最近的bug,权重为1;离当前时间最远的bug,权重为0。
由此,bug过去的时间越久,它对预测概率的贡献就越小。算法更加偏向近期的bug记录,而相对忽视远期的bug记录。上述False Positive现象,因此就得到抑制。
阶段三:即时(just-in-time)bug预测
无论是阶段一基于代码metrics的bug预测,还是阶段二基于历史记录的bug预测,预测的对象都是代码源文件。文件级bug预测存在的一个问题是不能在bug产生的时间与地点对bug进行识别和拦截。它看起来像一种"事后诸葛亮"的做法。
随着软件开发越来越多地采用持续集成(CI)模式,我们希望在开发者提交代码改动时,就进行bug预测。这时候,bug预测的对象不再是源文件,而是一次代码改动。
所谓代码改动,就是出于某个目的,例如提交新特性或修复已知bug,而添加、修改或删除一个或多个源文件中的代码行的活动。
此时的bug预测有个正式的名字,叫做just-in-time(即时)bug预测,从而与传统bug预测做了区分。即时bug预测通过挖掘代码改动的特征,建立代码改动特征与代码改动是否会引入bug之间的映射模型,用来预测代码改动导致新bug的概率。概率是否超出门限,可以作为代码改动能否合入代码库主干的标准(门禁)之一。
相比传统bug预测,即时bug预测的结果更有现实意义,与工程结合也更紧密,因而在近10年来成为bug预测的主流方向。当然,从复杂度来看,即时bug预测问题的挑战性也是空前的。
为了进行即时bug预测,学者们挖掘了丰富的代码改动特征,例如改动大小(添加、修改、删除行数),改动范围(发生变动的源文件、目录数量),改动历史(发生改动的源文件历史上的修改情况),作者信息(提交代码、产生bug的记录),代码评审信息(comments数量、reviewer记录)等。
由此可知,即时bug预测既利用了阶段一中的代码metrics特征,也利用了阶段二中的历史记录特征。基于这种复合的特征空间,我们就可以采用与传统bug预测中类似的机器学习算法来解决即时bug预测问题。
即时bug预测面临的挑战是:人工提取特征的成本高,并且难以提取到深层次特征。例如,两个改动大小、范围、作者信息等完全相同,但是具体修改内容不同的代码改动,模型会认为它们有bug的概率是相同的。
这显然有可能是错误的,因为具体修改内容,也是代码是否有bug的影响因素,甚至是更重要的因素。例如,一个判断条件,是a < 10还是a <= 10?形式的小差异可能导致结果的大不同:一个有bug,一个没有bug。这里牵涉到代码改动的语法和语义特征,人工很难提取。
幸运的是,深度学习(deep learning)的横空出世,给我们提取代码改动的深层次特征带来了希望。深度学习技术的引入,开辟了软件bug预测的第四个阶段,也是最新的阶段。
阶段四:基于深度学习的即时bug预测
机器学习的一般过程是数据采集、特征工程、模型训练和模型评价。其中,数据采集,模型训练和模型评价都容易自动化,唯独特征工程常常严重依赖大量人工,效率低且成本高,是机器学习的瓶颈。
深度学习带来的最大改变就是:特征工程也被自动化了,机器学习流程也就可以实现端到端自动化。
基于深度学习的即时bug预测,用到的主要技术是自然语言处理。描述代码改动的commit message是自然语言,实现代码改动的编程语言也可看作某种形式的自然语言。
将commit message和代码改动作为文本型输入,算法可以自动从中学习各种各样的低阶和高阶特征(包括代码语法和语义特征),并利用这些特征来构建预测模型。这个过程中用到的典型技术有word embedding、卷积神经网络CNN等。
总结与展望
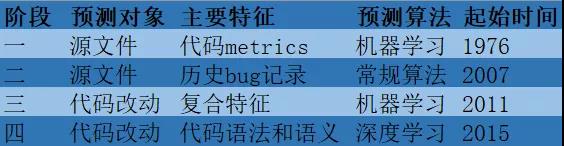
以上就是40多年来,bug预测研究的变迁历程。下面用一张表总结上述内容。
写到这里,大家或许会问,bug预测这么多研究成果,能不能用来改进我们日常的研发和测试工作呢?
坦白说,落地一直是bug预测研究的短板,也是其备受诟病的地方。"干打雷,不下雨",学术界研究得如火如荼,工业界却受益甚少。这显然不是一件好事。
当然,我们也不是没有落地的思路。比如:
(1) 将bug预测作为静态检查的一部分。在静态检查时,利用bug预测计算每个源文件有bug的概率。对于高概率源文件,以Error或Warning形式提醒开发者修改。
(2) 将bug预测作为持续集成的一部分。在开发者提交代码时,利用bug预测计算当前代码改动引入新bug的概率。对于超过门限概率的代码改动,阻止其合入代码库。
(3) 将bug预测作为代码评审的参考。在代码评审页面,对发生修改的高风险源文件(即上述20%源文件)进行显式标记,提醒reviewer对这部分改动进行更严格评审。
(4) 将bug预测作为测试选择的参考。建立测试用例和代码的依赖关系,对依赖高风险源代码的用例,优先执行。或者,对于高风险的代码改动,优先执行回归测试。两种方法都有望提高测试效率,更早发现问题。
以上思路能不能稳定落地,受很多因素,例如模型准确率,实现成本,收益大小,开发者接受度等影响,无法一概而论。就结果而言,由于这些因素的作用,bug预测鲜有直接落地的成功案例,但是间接落地的案例有值得一提的。
例如,第(4)点利用bug预测结果辅助回归测试,在Facebook的持续集成平台中就实现了规模化部署,且成效显著:在一年时间里,仅仅执行三分之一的测试用例,就发现了99.9%的回归问题。详情参见https://engineering.fb.com/developer-too ls/predictive-test-selection/。
凡是过往,皆为序章。如何看待bug预测的未来呢?可以肯定的是,bug预测作为软件工程的热点将继续受到重点研究;可以期待的是,bug预测的研究成果将用来辅助持续集成、持续测试等工作,为更多项目带来实际好处。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












