

当涉及到假设检验时,贝叶斯方法可以取代经典的统计方法。这里将使用web分析的具体案例来演示我们的演示。
贝叶斯方法在经典统计中的重要性在此链接。https://towardsdatascience.com/from-frequentism-to-bayesianism-hypothesis-testing-a-simple-illustration-11213232e551
假设检验是统计学中的一个中心话题,它的应用范围很广,超出了数学的范围,即使不是全部科学领域,也可以扩展到大多数科学领域。
我们将高度重视常规统计频率的方法的局限性,并提出一个相关的贝叶斯框架,以解决数据科学家在零售或营销工作中可能遇到的最常见的情况之一:A/B测试。
问题陈述
A/B测试(也称为分桶测试)为一种随机测试,将两个不同的东西(即A和B)进行假设比较。该测试运用统计学上的假设检定和双母体假设检定。A/B测试可以用来测试某一个变量两个不同版本的差异,一般是让A和B只有该变量不同,再测试其他人对于A和B的反应差异,再判断A和B的方式何者较佳(维基百科)
也许我们想为我们的网站测试一个新的设计,新的功能,甚至是针对我们的客户的新策略,以衡量哪一个会导致最高的投资回报率。为了清晰起见,我们将考虑广告使用A和B两种创意的情况下试图提高转化率:每个交互广告的用户可以被看作是有两个可能的结果的伯努利试验:“转换”和“不转换”,根据用户购买我们产品后显示广告。
可以考虑两种设计来运行这个实验:
· 离线:可以理解为已缓存的本地数据集中进行实验
· 在线:在实验中进行分析和决策。
由于离线A/B测试问题需要截然不同的解决方案,因此本文只讨论离线情况。
频率方法:p值法和roc曲线法
每个用户被展示为创意A或B的概率为0.5,并直接以未知的概率p_A=0.04或p_B=0.05进行转换。
import scipy.stats as stats #真实概率 p_A = 0.05 p_B = 0.04 #用户流量 n_users = 13500 n_A = stats.binom.rvs(n=n_users, p=0.5, size=1)[0] n_B = n_users - n_A #转换策略 conversions_A = stats.bernoulli.rvs(p_A, size=n_A) conversions_B = stats.bernoulli.rvs(p_B, size=n_B) print("creative A was observed {} times and led to {} conversions".format(n_A, sum(conversions_A))) print("creative B was observed {} times and led to {} conversions".format(n_B, sum(conversions_B))) |
第一个困难很快出现:为了确定一个广告素材是否比另一个更好,我们应该使用哪种测试?下表总结了常见的测试,由我们来选择最适合我们的问题的测试。
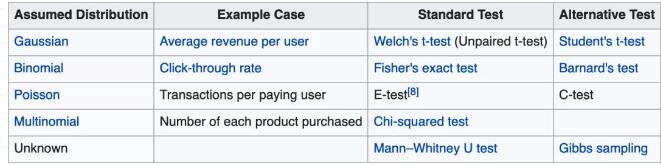
在我们的例子中,Fisher’s exact test和 Barnard’s test似乎是最相关的,因为我们关注从二项式分布获得的转化率
我们将使用Fisher检验,它具有属于精确检验类别的特点,之所以这样称呼它,是因为它的p值可以精确计算
· H0:广告素材的效果相当(p_A = p_B)
· H1:一个广告素材的效果要好于另一个
优良作法要求我们确定测试的统计能力。可以根据给定环境设计的仿真结果进行计算。我们的目标是0.8,我们使用的观测量将被校准,以达到这个阈值。为了方便起见,我们仅考虑替代假设H1-“替代假设p_A = 0.04或p_B = 0.05”,这将使我们能够轻松地计算检验的效果。

通常,α= 0.05是p值(即误报率)的拒绝区域接受的极限。对于此阈值,将至少需要13500次观测。
解释测试结果
我们会问一个问题。从我们的测试结果和p值中我们可以得出什么结论?
1、我们是否可以估算广告素材A优于广告素材B的可能性?
2、如果是的话,我们可以估计他们之间的进步吗?
两个问题的答案都是否定的。我们已经了解到,在假设(H0)下,p值仅仅是观察结果的可能性至少是极端的。但这也凸显了p值最重要的局限性:
p值不是效果大小的度量!即使获得了积极的结果,它也没有提供关于A的效果优于B的信息。
为了提取有关效果大小的知识,可以使用另一个更强大的工具:置信区间。
置信区间(CI)
置信区间表示与真实参数在建议范围内的置信度相关的未知参数的合理值范围。
这给了我们更多的理解和丰富的见解,为我们提供了关于我们估计的概率和不确定性的知识。然而,它们也有自己的缺点:
1、我们需要选择不同的方法来定义这些区间,这取决于一些假设:二项分布的置信区间。
2、p_A和p_B值的置信区间不会直接转换为p_A和p_B之间的差值的置信区间!幸运的是,存在直接计算差值的置信区间的方法,但是我们仍然需要从几十种方法中选择一种。
例如,我们可以使用“最简单的”,即不需要连续性校正的Wald方法:
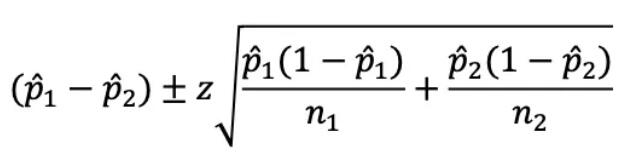
用𝑝̂的经验估计p_A和p_B,并且z对应于正态分布的α/2-百分位数。因此,对于95%置信区间(即α= 0.05),相应的z值将为1.96。
数值应用将给我们间隔[0.0009; 0.0171]以0.009为中心,不像我们希望的那样与0重叠!
贝叶斯方法:简单之美
对于本部分,我们将使用python的PyMC3库,这使我们能够轻松地构建贝叶斯非参数模型。
重要的是要记住,我们作为统计学家或数据科学家的目标显然是为了构想准确和相关的结果,而且同样重要的是,生成可以被任何其他利益相关者(甚至是非科学利益相关者)共享和理解的KPI。它将携带尽可能多的信息。贝叶斯方法为我们提供了执行此操作所需的工具,它允许我们精确地计算所需的内容:p_A和p_B的后验分布,即P(p_A | X)和P(p_B | X)以及P(p_A — p_B> 0 | X),即,广告素材A比广告素材B产生更多转化的概率。
这里的贝叶斯模型还是很简单的,因为我们已经用数学方法设计了环境,我们只需要用贝叶斯语言来复制它。
优先选择的问题不可避免地出现。我们将为p_A和p_B选择无信息的统一先验。
import pymc3 as pm with pm.Model() as model: n_users = 10000 #定义随机和确定性变量(构建网络) #用户的数量 n_A = pm.Binomial("n_A", n_users, 0.5) n_B = pm.Deterministic("n_B", n_users - n_A) # 数量的转换 conversions_A = pm.Binomial("conversions_A", n_A, p_A) conversions_B = pm.Binomial("conversions_B", n_B, p_B) observed_conversions_A = pm.Deterministic('observed_conversions_A', conversions_A) observed_conversions_B = pm.Deterministic('observed_conversions_B', conversions_B) p_estimates = pm.Uniform("p_estimates", 0, 1, shape=2) delta = pm.Deterministic("delta", p_estimates[1] - p_estimates[0]) #向网络提供观测数据 obs_A = pm.Binomial("obs_A", n_A, p_estimates[0], observed=observed_conversions_A) obs_B = pm.Binomial("obs_B", n_B, p_estimates[1], observed=observed_conversions_B) #运行MCMC算法 start = pm.find_MAP() step = pm.Metropolis() trace = pm.sample(50000, step=step) burned_trace = trace[1000:] |
我们也可以计算贝叶斯网络的图形表示:
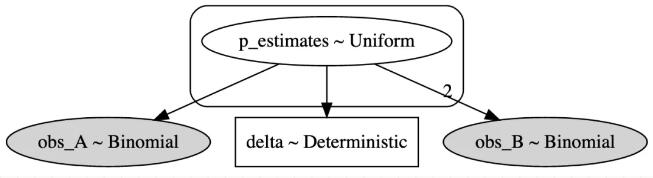
就这么简单,我们的工作结束了!我们剩下的全部工作就是通过网络运行MCMC算法,以计算后验分布。与现在的方法相比,这些将为我们提供更多的见解,因为现在我们可以通过从后验对象中直接采样来得出任何α水平的置信区间。
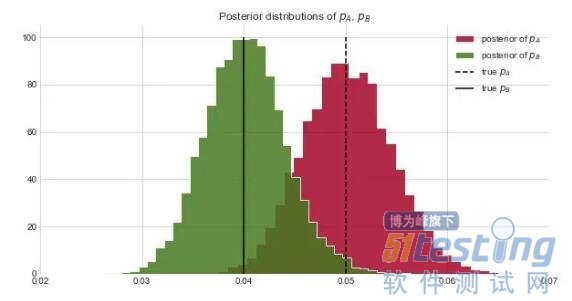
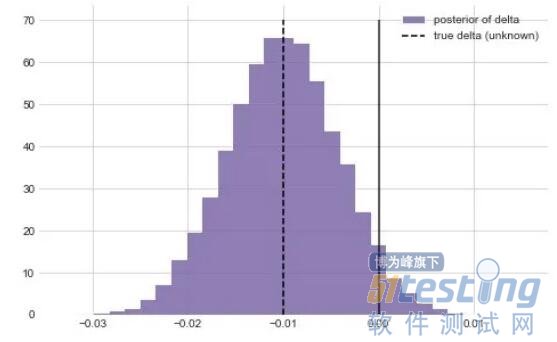
(很重要的一点是,由于p_A和p_B可能是依赖的,因此无法从p_A和p_B的后验值计算出增量)
结果
我们可以简单地计算出小于0的后验概率:
np.mean (delta_samples < 0)
在这里,我们得到了0.956,这意味着广告素材A产生的转化率比广告素材B高出96%!
但我们可以更进一步。想象一下,从设计B转换到设计A是很昂贵的,并且只有至少提高5%的性能才能盈利。我们有办法计算它!只需在我们的网络中插入一个新的确定性变量Tau = p_A/p_B,然后对后验分布进行采样。
tau = pm.Deterministic(“tau”, p_estimates[0] / p_estimates[1])
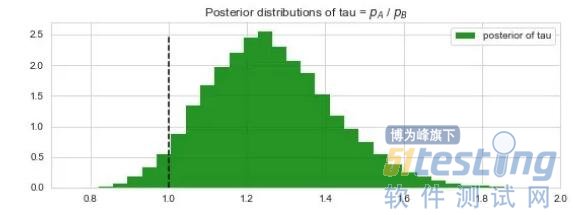
根据MCMC抽样估计的Tau的后验分布
np.mean (tau_samples > 1.05)
这次我们得到0.91...并不像我们通常希望的95%那样具有决定性。如果我们需要更多的信心,我们只需要运行A / B测试更长的时间。
结论
贝叶斯框架为经典的A/B检验方法提供了一个易于执行和阅读的替代方法,并允许我们通过简单地计算后验分布来检验任何假设。
贝叶斯方法使我们能够在A/B测试的情况下实现更高效的离线决策,以及更高效的在线决策。
注意:
不同的先验会给我们带来不同的后验。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












