

题记:众所周知,机器学习中有很多算法,像前面几期文章中介绍的逻辑回归算法、PageRank算法、K-means聚类算法等等。其实,每一种算法都有自己的优点和不足,都有自己特定的使用场景。这就要求我们在具体应用时,学会选择和比较,一般来说,我们会比较算法的时间复杂度、运行效率和正确率等因素,在某一特定的场景里,选择运行效率高且正确率高的算法。
言归正传,在这篇文章里,咖啡猫将带大家了解KNN算法的原理及Python的实现过程。希望小伙伴们能够掌握它。
一、什么是KNN算法
KNN算法的全称是K最近邻算法(即:K-NearestNeighbor)。它是机器学习数据挖掘分类技术中最简单的分类算法之一,它的核心思想是:每个样本的类别取决于它最近的K个邻居的类别。
如图1所示,要想知道绿色点属于哪一类(红色三角类或者蓝色方框类),我们可以选取离绿色点最近的K个点,统计这K个点中大部分点属于哪一类,那么这个绿色点就属于哪一类。如图当K取3时,绿色点属于红色三角类,当K取5时,绿色点属于蓝色方块类。
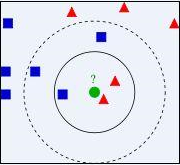
图1
二、KNN的算法流程
1.计算测试数据与各个训练数据的距离。
2.对训练数据按距离从小到大排序
3.取排序中前K个点
4.统计这K个点所在的类别(即统计每一种类别的元素个数)
5.以元素最多的类别作为测试数据所属类别
关于K值的选取:由图1中的例子可以知道,K值的选取对分类结果的影响很大:k过小,则受噪声的影响大;k过大,则利用较大邻域中的数据进行分类预测,算法时间复杂度就会上升。在实际应用中,常用的方法就是K从1开始取到N,统计不同K值下模型的正确率,最后选择正确率最高的K值。另外,K要尽量取奇数,来保证最后有只有一个类别的元素个数较多。
关于距离的计算公式:常用的距离计算公式有欧几里得距离、余弦值、相关度、曼哈顿距离等。在本文中我们选择欧几里得距离公式,即:
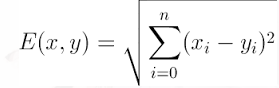
(其中,n为样本点的维数)
......
查看更多精彩内容,请点击下载:
版权声明:本文出自《51测试天地》第五十六期。51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。












