

前言
被测试网页的HTML代码
<!DOCTYPE html> <html> <body> <meta charset="UTF-8"> <table width="400" border="1" id="table"> <tr> <td align="left">消费项目</td> <td align="right">一月</td> <td align="right">二月</td> </tr> <tr> <td align="left">衣服</td> <td align="right">1000元</td> <td align="right">500元</td> </tr> <tr> <td align="left">化妆品</td> <td align="right">3000元</td> <td align="right">500元</td> </tr> <tr> <td align="left">食物</td> <td align="right">3000元</td> <td align="right">650.00元</td> </tr> <tr> <td align="left">总计</td> <td align="right">7000元</td> <td align="right">1150元</td> </tr> </table> </body> </html> |
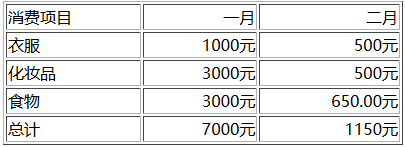
①遍历表格所有单元格
实例代码
1 from selenium import webdriver 2 driver = webdriver.Firefox() 3 driver.get(r'file:///D:/pythonSeleniumTestCode/pythonStu/src/table.html') 4 #id定位方式获取整个表格对象 5 table = driver.find_element_by_id('table') 6 #通过标签名获取表格中所有行 7 trlist = driver.find_elements_by_tag_name('tr') 8 print(len(trlist)) 9 for row in trlist: 10 #遍历行对象,获取每一个行中所有的列对象 11 tdlist = row.find_elements_by_tag_name('td') 12 for col in tdlist: 13 print(col.text + '\t',end='') 14 print('\n') 15 driver.quit() |
输出结果
消费项目 一月 二月 衣服 1000元 500元 化妆品 3000元 500元 食物 3000元 650.00元 总计 7000元 1150元 |
代码说明
1.先获取整个表格的页面对象
table=driver.find_element_by_id('table')
2.在表格页面元素对象中,获取所有tr元素对象,并存储在trlist中
trlist=table.find_elements_by_tag_name('tr')
3.循环遍历存储表格行对象的trlist对象,每获取一行中所有的单元格对象(存储到tdlist对象中),就循环遍历一次,并将每个单元格的文本内容输出
for row in trlist: #遍历行对象,获取每一个行中所有的列对象 tdlist = row.find_elements_by_tag_name('td') for col in tdlist: print(col.text + '\t',end='') print('\n') |
以上步骤完成表格中所有单元格的遍历输出,通过遍历可以实现读取任意单元格内容的操作。
②定位表格中的某个元素
目的
定位表格中第二行第二列单元格
XPATH表达式
| //table[@id='table']/tbody/tr[2]/td[2] |
python定位语句:
| element = driver.find_element_by_xpath('//table[@id='table']/tbody/tr[2]/td[2]') |
CSS表达式:
| table#table>tbody>tr:nth-child(2)>td:nth-child(2) |
python定位语句:
| element = driver.find_element_by_css_selector('table#table>tbody>tr:nth-child(2)>td:nth-child(2)') |
③定位表格中的子元素
被测试网页HTML代码
<!DOCTYPE html> <html> <body> <meta charset="UTF-8"> <table width="400" border="1" id="table"> <tr> <td align="left">消费项目</td> <td align="right">一月</td> <td align="right">二月</td> </tr> <tr> <td align="left">衣服: <input type="checkbox">外套</input> <input type="checkbox">内衣</input> </td> <td align="right">1000元</td> <td align="right">500元</td> </tr> <tr> <td align="left">化妆品: <input type="checkbox">面霜</input> <input type="checkbox">沐浴露</input> </td> <td align="right">3000元</td> <td align="right">500元</td> </tr> <tr> <td align="left">食物: <input type="checkbox">主食</input> <input type="checkbox">蔬菜</input> </td> <td align="right">3000元</td> <td align="right">650.00元</td> </tr> <tr> <td align="left">总计</td> <td align="right">7000元</td> <td align="right">1150元</td> </tr> </table> </body> </html> |
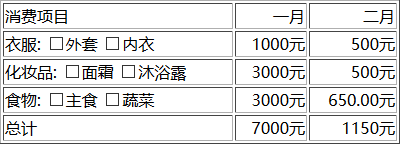
目的
在被测网页中,定位表格中第三行中的第一个“面霜”文字前的复选框。
| //td[contains(.,'化妆品')]/input[1] |
python定位语句:
| element = driver.find_element_by_xpath('//td[contains(.,'化妆品')]/input[1]') |
代码说明
先找到包含元素的单元格,在此单元格中再寻找子元素即可。表达式//td[contains(.,'化妆品')]表示模糊匹配文本内容包含“化妆”关键字的单元格td元素,//input[1]表示定位td下的第一个input子元素。
总结
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












