

1. 请求页面场景:这种场景通常是直接对URL页面的请求,通常不包含用户私有化的交易数据,通常使用浏览器请求的GET方式 。
2. 数据提交场景:这种场景通常是浏览器展示的页面上的用户输入要素提交后台的过程,这种提交可以有两种方式 ,简单的方式是GET方式,只需要将提交页面的目标URL附加上输入要素即可, 复杂的方式是POST方式,需要在HTTP通信体中包含提交的用户输入要素。这其中用户数据格式又有 JSON等格式。
3. 模拟浏览器用户输入和点击等场景:这种场景的目的是数据的输入,目标数据输入后,实际应用的结果是转化成了上述的数据提交场景。
所以 ,场景3实现了用户视觉化的提交,而场景2可以实现用户非视觉化的提交。如果在在场景1和场景2之间实现一个数据程序写入的过程。则3个场景的过程就完全转化为2个场景的过程。
一个典型的历经三个场景的过程是用户登陆的过程:
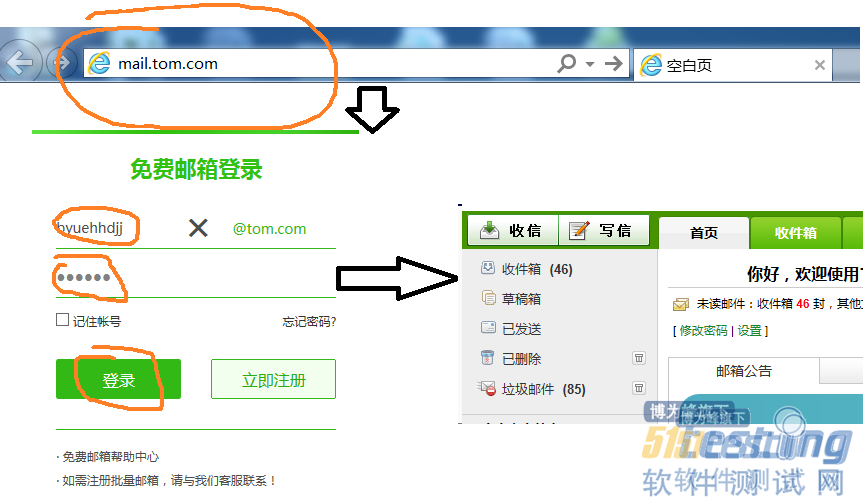
可以看到,在登录以后,写邮件或处理邮件的过程,又是场景1到场景3的重复,但与登录不同的是,写邮件或处理邮件的过程会包含数据处理的过程。 要实现数据自动处理过程,就要实现页面接入数据的读取与分析,浏览器的网络捕获器可以辅助实现该功能,有助于python编程人员进行数据读取与分析,而无需再安装专门的网络截包软件、代理软件或专用性能测试之软件,从而较方便快捷地实现2场景的编程过程和调试过程。
Python对场景1的编程过程示范代码如下:
import urllib.request import urllib.request booksurl="http://www.xxxx.com/bookshelf" response = urllib.request.urlopen(booksurl) html = response.read() #print(html) htmlstr=html.decode() |
Python对场景2的编程过程示范代码如下:
1.GET方式:
import urllib.request booksurl="http://www.xxxx.com/bookshelfask.jsp?id=37" response = urllib.request.urlopen(booksurl) html = response.read() #print(html) htmlstr=html.decode() |
......
查看更多精彩内容,请点击下载:
版权声明:本文出自《51测试天地》第五十五期。51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。












