

Abstract
本文是爬虫项目第二篇,主要介绍了使用selenium爬取拉钩数据分析职位招聘信息的过程。
WHY
海投简历的了无音讯让我对自己对招聘市场的认知产生了怀疑,因此,想要对招聘市场行情进行分析,这是数据分析的前置步骤——数据获取。
HOW
本文使用python的selenium、BeautifulSoup、pandas等包爬取了拉钩搜索“数据分析”岗位所得的职位信息,并存入csv中。具体步骤:
response获取。
在拉钩主页搜索“数据分析”,定位为全国,取得url,构建bronser对象,使用bronser打开url
from selenium import webdriver from bs4 import BeautifulSoup import time import pandas as pd bronser = webdriver.Chrome() bronser.get('https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?px=default&city=%E5%85%A8%E5%9B%BD#order') |
url解析。
第一层是一个循环,用于翻页。
对于每一页,首先使用BeautifulSoup对html解析,使用soup.find()方法找到岗位列表,并使用bronser找到下一页按钮并构建对象。
然后对岗位列表中的每一条岗位的岗位信息进行提取,并存入job_info列表中,然后将每条岗位信息列表存入job列表中。每一页的数据爬取之后,判断下一步按钮是否可以执行,如果可以则使用button.click()点击下一步,并且未防止出现验证,停留10s后继续运行
job = [] while True: soup = BeautifulSoup(bronser.page_source) list_of_position = soup.find('div',class_='s_position_list').find('ul').find_all('li') next_button = bronser.find_element_by_class_name('pager_next ') for i in list_of_position: company = i.get('data-company') companyid = i.get('data-companyid') hrid=i.get('data-hrid') positionid=i.get('data-positionid') positionname=i.get('data-positionname') salary=i.get('data-salary') tpladword=i.get('data-tpladword') location = i.find('em').string hr_position = i.find('input',class_='hr_position').get('value') position_tag = i.find('div',class_='li_b_l').text.split('\n')[-2] experience = position_tag.split('/')[0] education = position_tag.split('/')[1] company_tag = i.find('div',class_='industry').text.strip().split('/') industry = company_tag[0] financing = company_tag[1] company_scale = company_tag[2] position_describe = i.find('div',class_='list_item_bot').find('span').text company_describe = i.find('div',class_='list_item_bot').find('div',class_="li_b_r").text job_info = [positionid,positionname,company,companyid,hrid,hr_position,salary,tpladword, location,experience,education,industry,financing,company_scale,position_describe,company_describe] job.append(job_info) if 'pager_next_disabled' in next_button.get_attribute('class'): break next_button.click() time.sleep(10) |
数据存储
这里不同以往,在解析网页时,直接将数据存入列表中而不是写入文件,最终获得所有数据的二维列表,然后使用pandas转为DataFrame(数据表)df并使用df.rename()重命名列名后使用df.to_csv()导出为csv文件。
| df = pd.DataFrame(job) columns = ['positionid','positionname','company','companyid','hrid','hr_position','salary','tpladword','location','experience','education','industry','financing','company_scale','position_describe','company_describe'] df.rename(columns=dict(enumerate(columns)),inplace=True) df.to_csv('拉钩招聘.csv') bronser.close() |
Result
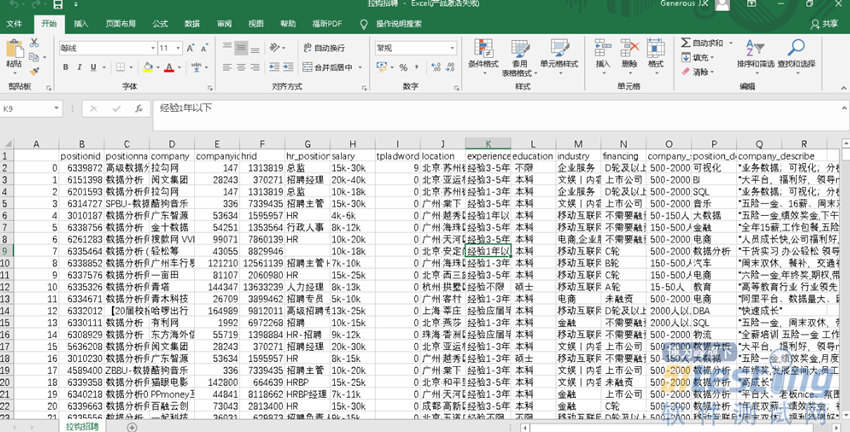
Summary
本次爬取过程相对比较顺利,只是在开始时由于未设定time.sleep()导致弹出登录框,之后尝试了1s、3s、5s分别在不同页面弹出登录框,最终使用10s获得了数据。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












