

几个月前,记得群里一朋友说想用selenium去爬数据,关于爬数据,一般是模拟访问某些固定网站,将自己关注的信息进行爬取,然后再将爬出的数据进行处理。
他的需求是将文章直接导入到富文本编辑器去发布,其实这也是爬虫中的一种。
其实这也并不难,就是UI自动化的过程,下面让我们开始吧。
准备工具/原料
1、java语言
2、IDEA开发工具
3、jdk1.8
4、selenium-server-standalone(3.0以上版本)
步骤
1、分解需求:
需求重点主要是要保证原文格式样式都保留:
将要爬取文章,全选并复制
将复制后的文本,粘贴到富文本编辑器中即可
2、代码实现思路:
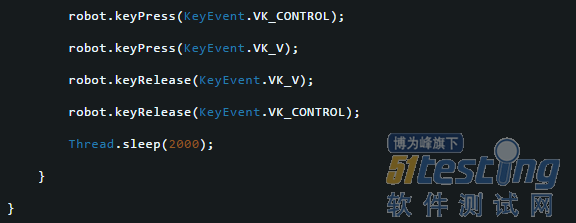
键盘事件模拟CTRL+A全选
键盘事件模拟CTRL+C复制
键盘事件模拟CTRL+V粘贴
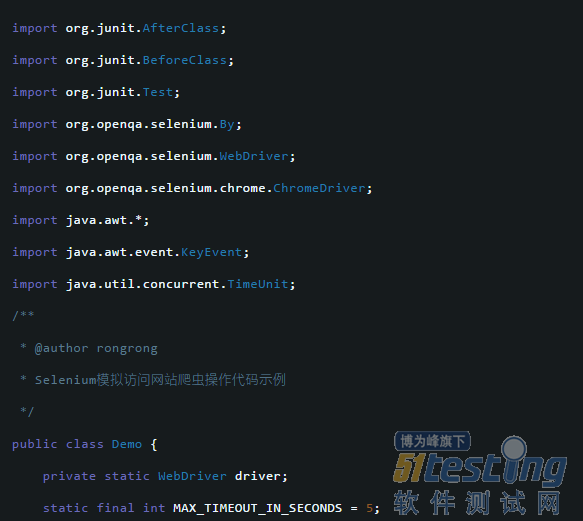
3、实例代码


写在后面
小编并不是特别建议使用selenium做爬虫,原因如下:
速度慢:
每次运行爬虫都要打开一个浏览器,初始化还需要加载图片、JS渲染等等一大堆东西;
占用资源太多:
有人说,把换成无头浏览器,原理都是一样的,都是打开浏览器,而且很多网站会验证参数,如果对方看到你恶意请求访问,会办了你的请求,然后你又要考虑更换请求头的事情,事情复杂程度不知道多了多少,还得去改代码,麻烦死了。
对网络的要求会更高:
加载了很多可能对您没有价值的补充文件(如css,js和图像文件)。 与真正需要的资源(使用单独的HTTP请求)相比,这可能会产生更多的流量。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。











