

2.3.2 单个元素定位实战
在 Selenium 自动化测试中,提供了单个元素定位方式和多个元素定位方式。两种方式都是根据元素属性 ID、NAME、CLASS_NAME、TAG_NAME、CSS_
SELECTOR、XPATH、LINK_TEXT、PARTIAL_LINK_TEXT 来进行定位。下面就通过具体的实例说明单个元素定位在 UI 自动化测试中的应用。
1. find_element_by_id
通过元素属性 ID 定位到元素,方法是 find_element_by_id。这里以百度搜索
输入框为例,它的代码是:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete ="off">
它的 ID 属性是 kw,在百度搜索输入框中输入搜索的关键字"selenium"的
代码如下:
#!/usr/bin/env python #-*-coding:utf-8-*- from selenium import webdriver driver=webdriver.Firefox() driver.maximize_window() driver.implicitly_wait(30) driver.get('http://www.baidu.com') driver.find_element_by_id('kw').send_keys('selenium') driver.quit() |
2. find_element_by_name
通过元素属性 NAME 定位到元素,方法是 find_element_by_name。它的
NAME 元素属性是 wd,在百度搜索输入框中输入中实现搜索关键字的代码如下:
#!/usr/bin/env python #-*-coding:utf-8-*- from selenium import webdriver driver=webdriver.Firefox() driver.maximize_window() driver.implicitly_wait(30) driver.get('http://www.baidu.com') driver.find_element_by_name('wd').send_keys('selenium') driver.quit() |
3. find_element_by_class_name
通过元素属性 CLASS_NAME 定位到元素,方法是 find_element_by_class_
name。还是以在百度搜索输入框中输入搜索关键字"selenium"为例,实现的代码如下:
#!/usr/bin/env python #-*-coding:utf-8-*- from selenium import webdriver driver=webdriver.Firefox() driver.maximize_window() driver.implicitly_wait(30) driver.get('http://www.baidu.com') driver.find_element_by_class_name('s_ipt').send_keys('selenium') driver.quit() |
4. find_element_by_xpath
通过 XPATH 定位百度搜索输入框的元素,方法是 find_element_ by_xpath,
原始属性是//*[@id="kw"]。获取的方式是定位到百度搜索输入框的元素属性后,用鼠标右键点击该属性,在弹出的快捷菜单中上选择"Copy"选项,在"Copy" 子选项中选择"Copy Xpath"选项,如图 2-3-4 所示。
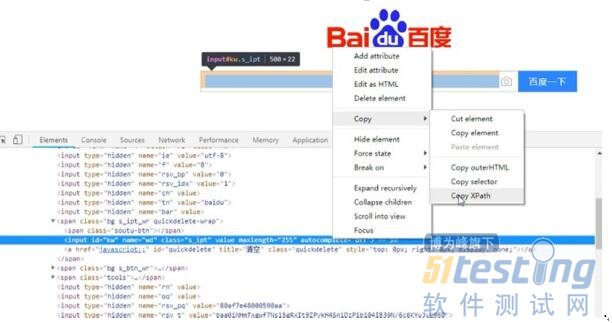
图 2-3-4
以在百度搜索输入框中输入搜索关键字"selenium"为例,实现的代码如下:
#!/usr/bin/env python #-*-coding:utf-8-*- from selenium import webdriver driver=webdriver.Firefox() driver.maximize_window() driver.implicitly_wait(30) driver.get('http://www.baidu.com') driver.find_element_by_xpath('//*[@id="kw"]').send_keys('selenium') driver.quit() |
5. find_element_by_link_text
LINK_TEXT 用于对超链接的处理。在 HTML 的代码中主要是以标签 a 对应,方法是 find_element_by_link_text。以点击百度首页的"新闻"链接为例,查看
"新闻"对应的代码:<a href="http://news.baidu.com" name="tj_trnews" class=
"mnav">新闻</a>。依据代码可以看到它是以 a 标签的。下面实现点击百度首页的"新闻"链接,实现的代码如下:
#!/usr/bin/env python #-*-coding:utf-8-*- from selenium import webdriver driver=webdriver.Firefox() driver.maximize_window() driver.implicitly_wait(30) driver.get('http://www.baidu.com') driver.find_element_by_link_text(u'新闻').click() driver.quit() |
6. find_element_by_partial_link_text
PARTIAL_LINK_TEXT 也用于对超链接的处理,它与 LINK_TEXT 不同的是,它是按模糊搜索方式处理的。例如,在百度首页包含"闻"字的只有新闻链接,那么操作的时候只需要填写"闻"字就可以定位成功,方法是 find_
element_by_partial_ link_text。仍以实现点击百度首页的"新闻"链接为例,代码如下:
#!/usr/bin/env python #-*-coding:utf-8-*- from selenium import webdriver driver=webdriver.Firefox() driver.maximize_window() driver.implicitly_wait(30) driver.get('http://www.baidu.com') driver.find_element_by_partial_link_text(u'闻').click() driver.quit() |
7. find_element_by_css_selector
当使用 ID、NAME 等方式定位不到元素的时候,可使用 CSS_SELECTOR,方法是 find_element_by_css_selector。这里以百度搜索输入框为例,获取的方式是定位到百度搜索输入框的元素属性后,用鼠标右键点击该属性,在弹出的快捷菜单中上选择"Copy"选项,在"Copy"子选项中选择"Copy selector"选项,就可以获取到基于 CSS_SELECTOR 的元素属性是#kw,如图 2-3-5 所示。
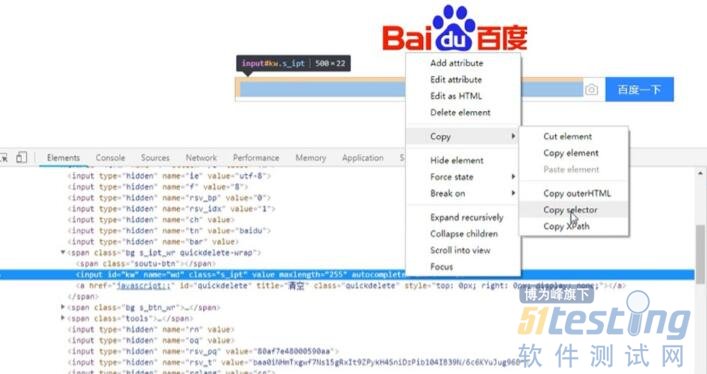
图 2-3-5
在百度搜索输入框中输入搜索关键字"selenium"的代码如下:
#!/usr/bin/env python #-*-coding:utf-8-*- from selenium import webdriver driver=webdriver.Firefox() driver.maximize_window() driver.implicitly_wait(30) driver.get('http://www.baidu.com') driver.find_element_by_css_selector('#kw').send_keys('Selenium') driver.quit() |
版权声明:51Testing软件测试网获得电子工业出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。











