

ЁЁЁЁЖдвЛИіЭјеОЭкОђЕФЩюЧГРДЫЕЃЌаХЯЂЪеМЏЪЧЗЧГЃЕФживЊЕФЃЌетЦЊЮФеТжївЊЗжЯэБОШЫдкЩјЭИВтЪдаХЯЂЪеМЏНзЖЮЕФвЛаЉаФЕУЃЌШчгаУ§ЮѓПвЧыжИГіЁЃ
ЁЁЁЁзггђУћЪеМЏ
ЁЁЁЁзггђУћЪеМЏЪЧзюМђЕЅЕФЪеМЏЪжЗЈжЎвЛЃЌгаКмЖрдкЯпЕФЙЄОпПЩвджБНгЬзгУЃЌетРяЗжЯэМИИіЮвОГЃгУЕФЁЃ
ЁЁЁЁПЊаФЕФЪБКђгУгУетИіЩЈУшЦї
ЁЁЁЁЮЊЪВУДетУДЫЕЃЌвђЮЊетЪЧЮваДЕФЃК
import requests ЁЁЁЁimport threading ЁЁЁЁfrom bs4 import BeautifulSoup ЁЁЁЁimport re ЁЁЁЁimport time ЁЁЁЁurl = input( 'url(Шчbaidu.com): ' ) ЁЁЁЁhead={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'} ЁЁЁЁip = 'http://site.ip138.com/{}'.format( url ) ЁЁЁЁ# domain_url = url.split('.') ЁЁЁЁ# domain_url = domain_url[1]+'.'+domain_url[2] ЁЁЁЁdomain_url = url ЁЁЁЁdomain = 'http://site.ip138.com/{}/domain.htm'.format( domain_url ) ЁЁЁЁt = time.strftime("%Y-%m-%d"+'_', time.localtime()) ЁЁЁЁhtml_file = open( url+'_'+t+'.html','w' ) ЁЁЁЁhtml_file.write( ''' ЁЁЁЁ<head> ЁЁЁЁ<title>%sЕФЩЈУшНсЙћ</title> ЁЁЁЁ<link rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/css/bootstrap.min.css"> ЁЁЁЁ<script src="https://cdn.staticfile.org/jquery/2.1.1/jquery.min.js"></script> ЁЁЁЁ<script src="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/js/bootstrap.min.js"></script> ЁЁЁЁ<style> ЁЁЁЁpre{ ЁЁЁЁmargin: 0 0 0px; ЁЁЁЁ} ЁЁЁЁ</style> ЁЁЁЁ</head> ЁЁЁЁ<ul id="myTab" class="nav nav-tabs navbar-fixed-top navbar navbar-default"> ЁЁЁЁ<li class="active"> ЁЁЁЁ<a href="#ip" data-toggle="tab"> ЁЁЁЁIPРњЪЗНтЮі ЁЁЁЁ</a> ЁЁЁЁ</li> ЁЁЁЁ<li><a href="#cms" data-toggle="tab">CMSЪЖБ№</a></li> ЁЁЁЁ<li><a href="#domain" data-toggle="tab">зггђУћаХЯЂ</a></li> ЁЁЁЁ</ul> ЁЁЁЁ<br> ЁЁЁЁ<br> ЁЁЁЁ<br> ЁЁЁЁ<br> ЁЁЁЁ<div id="myTabContent" class="tab-content"> ЁЁЁЁ'''%url ) ЁЁЁЁclass IP( threading.Thread ): ЁЁЁЁdef __init__(self, ip): ЁЁЁЁthreading.Thread.__init__(self) ЁЁЁЁself.ip = ip ЁЁЁЁdef run(self): ЁЁЁЁr = requests.get( self.ip,headers = head ) ЁЁЁЁhtml = r.text ЁЁЁЁbs = BeautifulSoup(html, "html.parser") ЁЁЁЁhtml_file.write('<div class="tab-pane fade in active" id="ip">') ЁЁЁЁfor i in bs.find_all('p'): ЁЁЁЁipc = i.get_text() ЁЁЁЁip_html = '<pre>{}</pre>'.format( ipc ) ЁЁЁЁhtml_file.write( ip_html ) ЁЁЁЁhtml_file.write('</div>') ЁЁЁЁclass CMS( threading.Thread ): ЁЁЁЁdef __init__(self, cms): ЁЁЁЁthreading.Thread.__init__(self) ЁЁЁЁself.cms = cms ЁЁЁЁdef run(self): ЁЁЁЁcms = requests.post('http://whatweb.bugscaner.com/what/', data={'url': self.cms}, headers = head) ЁЁЁЁtext = cms.text ЁЁЁЁWeb_Frameworks = re.search('"Web Frameworks": "(.*?)"]', text) ЁЁЁЁProgramming_Languages = re.search('"Programming Languages":(.*?)"]', text) ЁЁЁЁJavaScript_Frameworks = re.search('"JavaScript Frameworks": (.*?)"]', text) ЁЁЁЁCMS = re.search('"CMS": (.*?)"]', text) ЁЁЁЁWeb_Server = re.search('"Web Servers": (.*?)"]', text) ЁЁЁЁif CMS: ЁЁЁЁCMS = CMS.group(1)+'"]' ЁЁЁЁif Programming_Languages: ЁЁЁЁProgramming_Languages = Programming_Languages.group(1)+'"]' ЁЁЁЁif JavaScript_Frameworks: ЁЁЁЁJavaScript_Frameworks = JavaScript_Frameworks.group(1)+'"]' ЁЁЁЁif Web_Frameworks: ЁЁЁЁWeb_Frameworks = Web_Frameworks.group(1)+'"]' ЁЁЁЁif Web_Server: ЁЁЁЁWeb_Server = Web_Server.group(1)+'"]' ЁЁЁЁhtml = ''' ЁЁЁЁ<div class="tab-pane fade" id="cms"> ЁЁЁЁ<div class="table-responsive"> ЁЁЁЁ<table class="table table-condensed"> ЁЁЁЁ<tr> ЁЁЁЁ<th>webПђМм</th> ЁЁЁЁ<th>НХБОАцБО</th> ЁЁЁЁ<th>JavaScriptПђМм</th> ЁЁЁЁ<th>CMSПђМм</th> ЁЁЁЁ<th>webЗўЮёЦї</th> ЁЁЁЁ</tr> ЁЁЁЁ<tr> ЁЁЁЁ<td>{0}</td> ЁЁЁЁ<td>{1}</td> ЁЁЁЁ<td>{2}</td> ЁЁЁЁ<td>{3}</td> ЁЁЁЁ<td>{4}</td> ЁЁЁЁ</tr> ЁЁЁЁ</table> ЁЁЁЁ</div> ЁЁЁЁ</div> ЁЁЁЁ'''.format(Web_Frameworks,Programming_Languages,JavaScript_Frameworks,CMS,Web_Server) ЁЁЁЁhtml_file.write( html ) ЁЁЁЁclass DOMAIN( threading.Thread ): ЁЁЁЁdef __init__(self, domain): ЁЁЁЁthreading.Thread.__init__(self) ЁЁЁЁself.domain = domain ЁЁЁЁdef run(self): ЁЁЁЁr = requests.get( self.domain,headers = head ) ЁЁЁЁhtml = r.text ЁЁЁЁbs = BeautifulSoup(html, "html.parser") ЁЁЁЁhtml_file.write('<div class="tab-pane fade in active" id="domain"') ЁЁЁЁnum = 0 ЁЁЁЁfor i in bs.find_all('p'): ЁЁЁЁnum += 1 ЁЁЁЁhtml_file.write( '<br>' ) ЁЁЁЁdomainc = i.get_text() ЁЁЁЁdomain_html = '<pre>[{}]ЃК {}</pre>'.format( num,domainc ) ЁЁЁЁhtml_file.write( domain_html ) ЁЁЁЁprint( domain_html ) ЁЁЁЁhtml_file.write('</div>') ЁЁЁЁip_cls = IP(ip) ЁЁЁЁip_html = ip_cls.run() ЁЁЁЁcms_cls = CMS(url) ЁЁЁЁcms_html = cms_cls.run() ЁЁЁЁdomain_cls = DOMAIN( domain ) ЁЁЁЁdomain_html = domain_cls.run() |
ЁЁЁЁgithubПЊдДЕФзггђУћЩЈУшЦї
ЁЁЁЁhttps://github.com/lijiejie/subDomainsBrutehttps://github.com/chuhades/dnsbrute
ЁЁЁЁдкЯпЭјеОЪеМЏ
ЁЁЁЁ1.https://d.chinacycc.com/ЃЈЗЧГЃЭЦМіЃЉ
ЁЁЁЁ
ЁЁЁЁШЛКѓВЛЕН30УыОЭГіНсЙћСЫЃК
ЁЁЁЁ
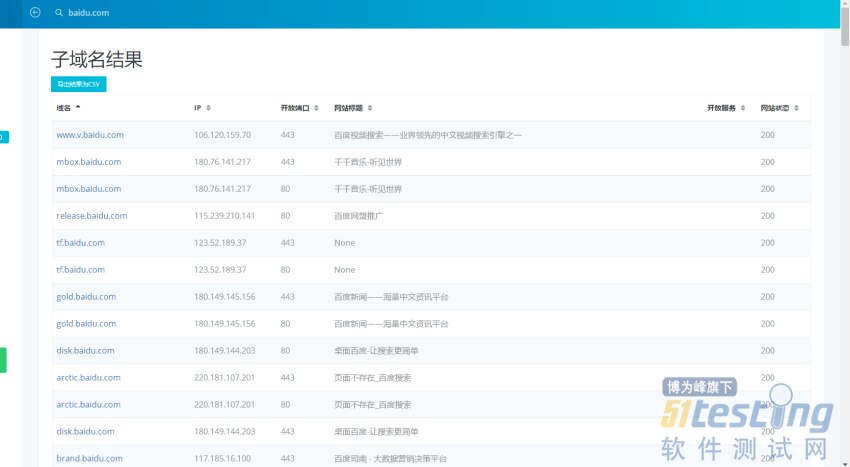
ЁЁЁЁ2.http://z.zcjun.com/https://phpinfo.me/domain/
ЁЁЁЁЖЫПкаХЯЂЪеМЏ
ЁЁЁЁЩЈУшЖЫПкВЂЧвБъМЧПЩвдБЌЦЦЕФЗўЮё
| ЁЁnmap ФПБъ --script=ftp-brute,imap-brute,smtp-brute,pop3-brute,mongodb-brute,redis-brute,ms-sql-brute,rlogin-brute,rsync-brute,mysql-brute,pgsql-brute,oracle-sid-brute,oracle-brute,rtsp-url-brute,snmp-brute,svn-brute,telnet-brute,vnc-brute,xmpp-brute |
ЁЁЁЁХаЖЯГЃМћЕФТЉЖДВЂЩЈУшЖЫПк
| nmap ФПБъ --script=auth,vuln |
ЁЁЁЁОЋШЗХаЖЯТЉЖДВЂЩЈУшЖЫПк
| nmap ФПБъ --script=dns-zone-transfer,ftp-anon,ftp-proftpd-backdoor,ftp-vsftpd-backdoor,ftp-vuln-cve2010-4221,http-backup-finder,http-cisco-anyconnect,http-iis-short-name-brute,http-put,http-php-version,http-shellshock,http-robots.txt,http-svn-enum,http-webdav-scan,iis-buffer-overflow,iax2-version,memcached-info,mongodb-info,msrpc-enum,ms-sql-info,mysql-info,nrpe-enum,pptp-version,redis-info,rpcinfo,samba-vuln-cve-2012-1182,smb-vuln-ms08-067,smb-vuln-ms17-010,snmp-info,sshv1,xmpp-info,tftp-enum,teamspeak2-version |
ЁЁЁЁЮвЯВЛЖетбљзіЃК
ЁЁЁЁ1.ЩЈУшзггђУћ

ЁЁЁЁЬсШЁГігђУћ/ipЃК
ЁЁЁЁ
ЁЁЁЁШЛКѓАбгђУћЗХЕН975.txtЁЃ
ЁЁЁЁ2.ХњСПЩЈУшЖЫПкКЭТЉЖДМьВт
| nmap -iL 975.txt --script=auth,vuln,ftp-brute,imap-brute,smtp-brute,pop3-brute,mongodb-brute,redis-brute,ms-sql-brute,rlogin-brute,rsync-brute,mysql-brute,pgsql-brute,oracle-sid-brute,oracle-brute,rtsp-url-brute,snmp-brute,svn-brute,telnet-brute,vnc-brute,xmpp-brute > scan.txt |
ЁЁЁЁШЛКѓИљОнЖдгІПЊЗХЕФЖЫПкНјааеыЖдадТЉЖДЭкОђЁЃ
ЁЁЁЁcЖЮаХЯЂЪеМЏ
ЁЁЁЁcЖЮЕФЛАЮввЛАуЖМЪЧЪЙгУiis putетПюЙЄОпРДЩЈУшЃЌПЩвдздЖЈвхЩЈУш1-255ЕФЖЫПкВЂЧвЛЙгаЗЕЛиЗўЮёЦїbannerаХЯЂЁЃ
ЁЁЁЁздЖЈвхЕФЖЫПк
| 135,139,80,8080,15672,873,8983,7001,4848,6379,2381,8161,11211,5335,5336,7809,2181,9200,50070,50075,5984,2375,7809,16992,16993 |
ЁЁ
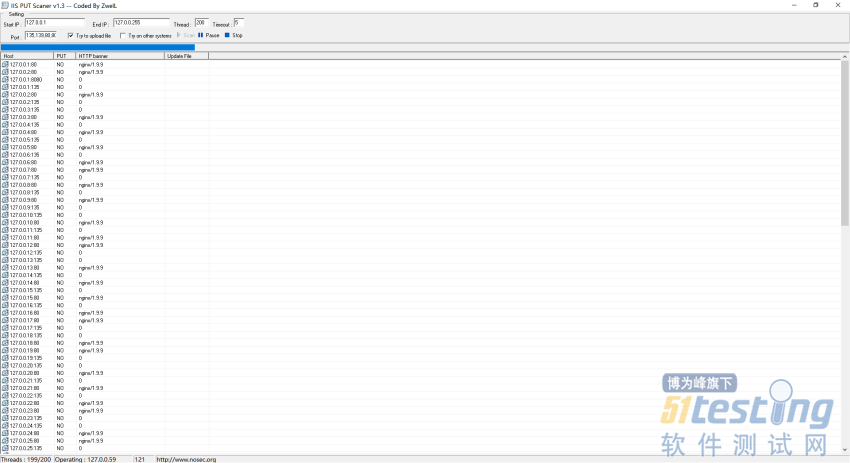
ЁЁЁЁетРяжЛЪЧбнЪОЯТЫћХмЦ№РДЕФУРЁЃ
ЁЁЁЁФПТМаХЯЂЪеМЏ
ЁЁЁЁФПТМЪеМЏЙЄОпгаКмЖрЃЌЕЋЪЧзюПДжиЕФЛЙЪЧФПТМзжЕфЃЌжЎЧАЮвФУСЫКмЖрЙЄОпЕФзжЕфШЅжиМЏКЯЦ№РДГЌМЖГЌМЖДѓЃЌжЛВЛЙ§ЪЧдкжЎЧАЕчФдФЧРяЛЙдЕФЪБКђЭќМЧСЫБИЗнЁЂЁЂЁЂЃЈЫЕетОфЛАжївЊЪЧЯыШУФуУЧвВПЩвдетбљзгзіЃЌЗНБуздМКЃЌШЛКѓЗЂЮввЛЗнЃЌЗНБуФуЮвЃЉ
ЁЁЁЁетРяЭЦМівЛИіЙЄОпЃК7kbstorm
ЁЁЁЁhttps://github.com/7kbstorm/7kbscan-WebPathBrute
ЁЁЁЁЯё403ЁЂ404етжжвГУцЧЇЭђВЛвЊЙиБеЃЌЗХФПТМРяУцЩЈОЭokЁЃ
ЁЁЁЁЙШИшгяЗЈЪеМЏУєИаЮФМў
ЁЁЁЁзюГЃМћЕФОЭЪЧгУЫбЫїв§Чц~
| site:ooxx.com filetype:xls |
ЁЁЁЁЪзЯШЪдЪдАйЖШЃК
ЁЁ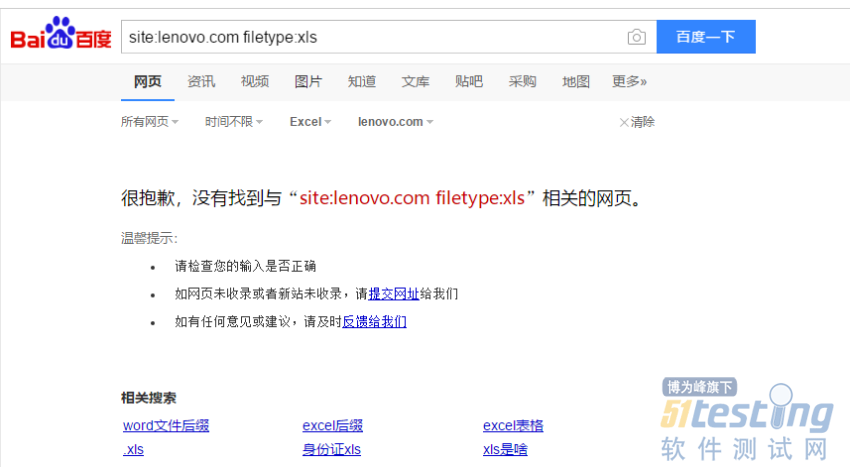
ЁЁЁЁ
| $!@!~~WDwadawicnm |
ЪдЪдБигІЃК
ЁЁЁЁ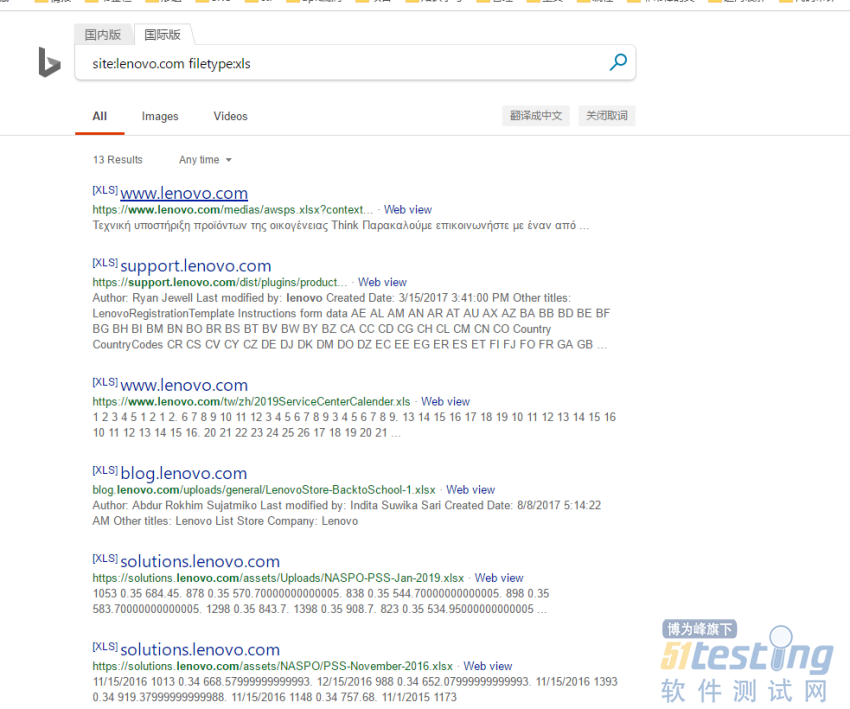
ЁЁЁЁЩЯЮФФкШнВЛгУгкЩЬвЕФПЕФЃЌШчЩцМАжЊЪЖВњШЈЮЪЬтЃЌЧыШЈРћШЫСЊЯЕВЉЮЊЗхаЁБр(021-64471599-8017)ЃЌЮвУЧНЋСЂМДДІРэЁЃ












