

一. 知识图谱和金融领域简述
什么是知识图谱?
借鉴其中一个理解:
知识图谱主要的目标是用来描述真实世界中间存在的各种实体和概念,以及它们之间的关联关系。
具体理论知识就不在此赘述,对于这个抽象的概念会有一篇文章来列举一个代表性的例子。
知识图谱起源于语义网络,最初由Google提出用与优化搜索结果,发展至今已经应用于各个垂直化领域。从商业概念上,知识图谱可分为“通用知识图谱”和“行业知识图谱”。通用知识图谱顾名思义是面向全领域的,强调的是“广度”,比较著名的知识库有Freebase, Wikidata, Yago, DBPedia等。
行业知识图谱是面向特定的垂直领域,对于数据有更严格的前置数据模式和更准确的准确度要求,强调的是“深度”。两者之间的主要区别在于前者是“自底向上”构建的知识库,后者是“自顶向下”构建的知识库。
金融领域数据是典型的具有”4V”特征的大数据(数量海量Volume、多结构多维度Variety、价值巨大Value、及时性要求Velocity)。进一步,金融领域是最能把数据变现的行业。金融业类别业非常广,大类主要包括:银行类、投资类、保险类等。再小粒度可分为:货币、债券、基金、信托等资管计划、要素市场、征信贷款等。知识图谱在金融领域的应用主要包括:风控、征信、审计、反欺诈、数据分析、自动化报告等,本文主要讨论知识图谱在小微风控的应用。
风控是指如何当项目或企业在一定的风险的环境里,把风险减至最低的管理过程。它的基本程序包括风险识别、风险估测、风险评价、风险控制和风险管理效果评价等环节。
风险控制的最大两个分类为企业风险监控和个人贷款审核。企业数据包括:企业基础数据、投资关系、任职关系、企业专利数据、企业招投标数据、企业招聘数据、企业诉讼数据、企业失信数据、企业新闻数据。个人贷款的数据包括:个人的基本信息、行为信息、信用信息、社交信息、消费信息等。
本文将主要讨论知识图谱在风控领域的图谱构建过程。
二. 风控的知识图谱构建
知识图谱的逻辑结构分为两个层次:数据层和模式层。
在知识图谱的数据层,数据如果以『实体-关系-实体』或者『实体-属性-值』作为基本表达方式,我们把这种表达方式称为“三元组”,则存储在图数据库中的所有数据将构成庞大的实体关系网络,形成知识的图谱。
模式层在数据层之上,是知识图谱的核心,在模式层存储的是经过提炼的知识,通常采用本体库来管理知识图谱的模式层,借助本体库对公理、规则和约束条件的支持能力来规范实体、关系以及实体的类型和属性等对象之间的联系。本体库在知识图谱中的地位相当于知识库的模具,拥有本体库的知识库冗余知识较少。
这里涉及知识图谱的另外一个重要概念是“本体( Ontology)”。本体的概念最早起源于哲学领域, 指的是对客观存在系统的解释和说明。在众多概念中,维基上的定义更加通俗些:本体实际上就是对特定领域之中某套概念及其相互之间关系的形式化表达。具体到金融风控领域,本体目的就是对风控领域的知识术语进行分类,同时规定各个分类之间的关系和它们自身的属性。
本体可以采用人工编辑的方式手动构建(借助本体编辑软件),也可以以数据驱动的自动化方式构建本体。自动化构建包含3个阶段:实体并列关系相似度计算、实体上下位关系抽取、本体的生成。在领域本体构建的实际工程中,领域本体所涉及的实体类型非常有限(最多数量也不会过百),与其花很高的成本去做自动化,不如人工构建本体。所以本章节也主要讨论风控领域的手动本体构建过程。
本体和知识图谱的构建方法有很多,这里分享一个在实际工作中初略的知识图谱构建流程:
本体库构建;
知识图谱构建;
知识图谱应用。
三. 风控的本体构建
如前所述,构建风控领域知识图谱的首要工作是构建本体模型,即定义行业的通用概念为实体,以及实体之间的关系。
信贷最核心的主体就是贷款申请者,贷款申请者可能是个人也可能是公司,通过申请者的基本信息、行为信息、经营状况、社会关系等评估贷款的风险。因此可以列举信贷相关的核心实体为:人、企业、银行账户、银行、抵押物、申请事件、诉讼事件等,以及基本信息实体:电话、邮件、地址等。实体与实体之间的关系为 亲属、任职、所有权、事件参与方等。如图所示为一个简化版的信贷风控本体模型。
为什么要将人和公司的电话地址设计为单独的实体节点,是基于风控的业务关注点,当两个贷款申请者有相同的电话或者地址时候,可能就是一个需要关注的风险点。把这两个信息作为单独的节点,基于图谱理论,当统计“电话”类型节点的边数量超过一个就能很方便找出高风险申请者。
本体构建完成后,需要对比实际业务对本体进行验证,确保本体能够正确描述当前业务,并且包含了所有的业务流程。
四. 风控的图谱构建
知识图谱的构建是图谱应用的前提,构建的主要工作是把数据从不同的数据源中按照本体模型所规定的规则抽取出来。对于垂直领域的知识图谱来说,数据的主要来源是是业务本身的数据,其通常是机构自己的私有数据以结构化的形式存储。通过ETL处理,将数据抽取转换为图谱数据。图谱数据的存储形式目前有两种:基于RDF等存储和图数据库存储。
RDF图数据库存储三元组节点和关系拥有属性符合W3C标准图的遍历和扩展方便有标准的推理引擎拥有事务管理数据可移植性高工程化程度高多用于学术场景可视化效果好。
在实际工程应用中主要采用图库的方式对知识图谱进行存储,当前比较流行的图数据库为Neo4j,本篇不再详细介绍图数据库和Neo4j,重点在于如何根据本体将数据映射成为Neo4j要求的数据格式。Neo4j提供了多种加载数据的方式,对于小规模数据(1w – 10w条数据),可以采用加载CSV的方式进行,CSV的格式要求如Neo4j官网的操作手册所示。
五. 图谱的应用
当前,小微贷款和个人小额贷款还处于“蛮荒时代”,甚至出现了各种中介机构通过各种伪造的虚假信息帮助客户申请贷款。所以对于放贷方而言,借贷风险控制面临非常巨大的挑战。
1. 贷款申请方画像
可以在图谱中直接搜索某个具体的人名字或者公司名字,获取该人或者公司的基础信息画像,如电话,地址,关联方的信息。如图所示:
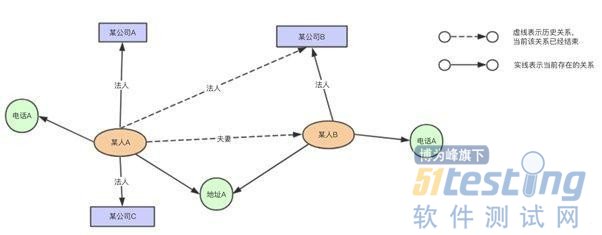
2. 关联方探查
通过图谱可以调查某个人或者某家申请贷款公司的关联方信息。在贷款审核期间,申请贷款主体的关联方信息中有借贷纠纷的诉讼事件,担保方过多等可关注的风险点。在贷款发放后,有时出现贷款方失联的情况,无法通过申请贷款时提交的信息联系到借款方,可以通探寻更“深远”的关联方找到失联的贷款方。
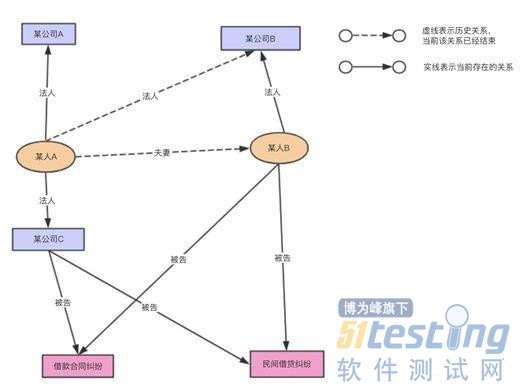
3. 反欺诈调查
在实际场景中,有不少人利用各种渠道而来身份证进行贷款申请。还有公司通过循环转账等方式提供虚假的经营流水信息。通过知识图谱可以识别以上风险点。如多个贷款申请人提供的身份证号吗不同,但是却有相同的联系电话号吗或者联系地址。银行作为借贷机构,可以调查申请人账户资金往来情况,识别是否存在循环转账等异常资金往来信息识别风险点。
在图谱中,通过条件搜索指定的节点可以筛选调查风险节点,如:“电话号码”节点的关联方大于1的节点。
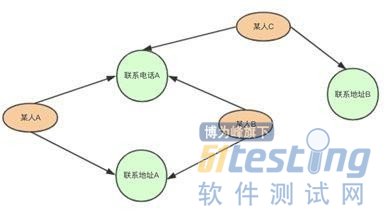
4. 风险指标报告
在风控处理中,贷款风险比率是衡量商业银行风险最重要的指标之一,主要包括不良贷款比率、贷款加权风险度、贷款分散化比率、不良贷款拨备覆盖率等。将知识图谱中贷款人节点和相关指标相结合,设定报警阈值,通过机器学习等技术,找到隐蔽的风险结构,指标特征,能够快速找出相关责任方和其关联方,形成报告供业务人员进行调。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












