

通过简单的代码就能实现一个简单的聊天机器人,今天小编就带领大家,利用自然语言处理技术和聊天机器人结合,做一个自动做诗的聊天机器人。
1.原理介绍
首先,让机器自动做诗,就需要运用自然语言处理的手段,让机器能够学会理解“诗句”,进而做出我们需要的诗句。如何让机器“理解”诗句呢?我们用到了深度学习中的长短期记忆网络(LSTM)。有点晕,不要急,我们后面会用白话给大家解释。
LSTM是循环神经网络(RNN)的一种变形,RNN能够很好的解决自然语言处理的任务,但是对于长依赖的句子表现却不是很好,例如:

上面的例子中后面使用“was”还是“were”取决于前面的单复数形式,但是由于“was”距离“dog”距离过长,所以RNN并不能够很好的解决这个问题。
为了解决上述的问题,便引入了LSTM,为了更加直观的解释,我这里引入一个不是很恰当的例子:
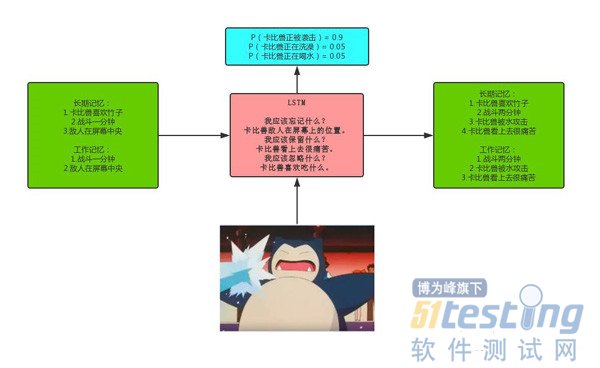
比如我们正在看一场电影,我们能够通过镜头的切换来了解故事的进展。而且随着故事的发展,我们会知道某些主角的性格,年龄,喜好等等,这些都不会随着镜头的切换而立马被忘掉,这些就是长期记忆,而当故事发生在某个特定的场景下,比如下面喜洋洋的这张图:

通过我们对于这部动漫的长期记忆,我们知道这是喜洋洋在思考,而在这个镜头中,我们利用到了长期记忆中关于“喜洋洋思考动作”的记忆,而在该镜头下需要被用到的长期记忆就被称为“工作记忆”。
2.白话解释LSTM
那么LSTM是如何工作的呢?
1).首先得让LSTM学会遗忘
比如,当一个镜头结束后,LSTM应该忘记该镜头的位置,时间,或者说忘记该镜头的所有信息。但是如果发生某一演员领了盒饭的事情,那么LSTM就应该记住这个人已经领盒饭了,这也跟我们观看影片一样,我们会选择忘记一些记忆,而保留我们需要的记忆。所以LSTM应该有能力知道当有新的镜头输入时,什么该记住,什么该忘记。
2).其次是添加保留机制
当LSTM输入新的镜头信息时,LSTM应该去学习什么样的信息值得使用和保存。然后是根据前面的两条,当有新的镜头输入时,LSTM会遗忘那些不需要的长期记忆,然后学习输入镜头中哪些值得使用,并将这些保存到长期记忆当中。
3).最后是需要知道长期记忆的哪些点要被立即使用
比如,我们看到影片当中有个人在写东西,那么我们可能会调用年龄这个长期记忆(小学生可能在写作业,而大人可能再写文案),但是年龄信息跟当前的场景可能不相关。
4).因此LSTM只是学习它需要关注的部分,而不是一次使用所有的记忆。因此LSTM能够很好的解决上述的问题。下图是对于LSTM的一个很形象的展示:
3.实战机器人
下面便是实战的环节,虽然LSTM效果非常出色,但是仍旧需要对于数据的预处理工作,LSTM需要将每个诗句处理成相同的长度,而且需要将汉字转换成为数字形式。那么如何进行预处理呢,主要分为3步 :
读入数据,我们收集了众多的诗词数据
统计每一个字出现的次数,同时以其出现的次数作为每个汉字的id。
在产生批量数据的时候,我们需要将每一个诗句的长度都统一到同样的长度,因此,对于长度不够的句子,我们会以“*”进行填充
所以在最后的效果展示的时候,可能在诗句中出现“*”的字样。数据预处理的部分代码如下图所示:

上述的代码中主要完成了下面几步:
1).首先是读入数据,并将句长大于100的进行缩减,删掉100个字符后面的部分。
2).然后在每个句子的开头和结尾加入‘^’和‘$’作为句子的标志。对于句长小于MIN_LENGTH的直接删除
3).最后将处理好的诗句,进行字数的统计,统计每个字出现的次数,并按照出现的次数作为每个汉字的id。
对于数据预处理部分的代码,我都进行了注释,方便大家进行理解,对于我们对于数据处理,以及python语句的理解都有极大的帮助。
模型的训练,需要确保电脑中已经配置了tensorflow和numpy库。当模型训练完成后,我们可以直接对于模型进行调用,嵌入到我们的聊天机器人程序中,来实现我们的聊天机器人(对于聊天机器人的介绍,可以参照文末历史文章)。
下面是部分代码的展示:
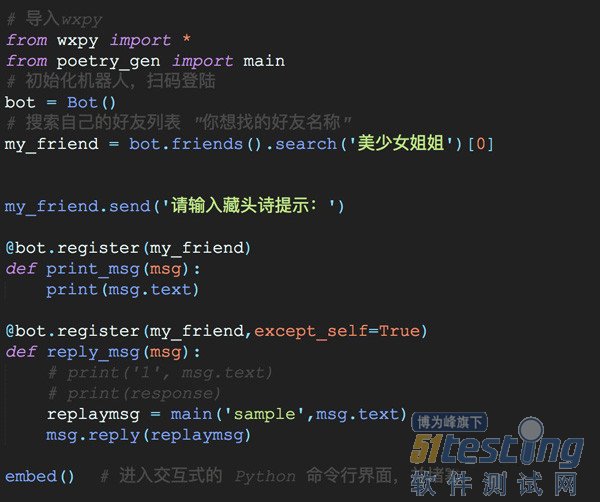
4. 效果展示
说了这么多,我们来看一些训练完的机器人作诗的效果
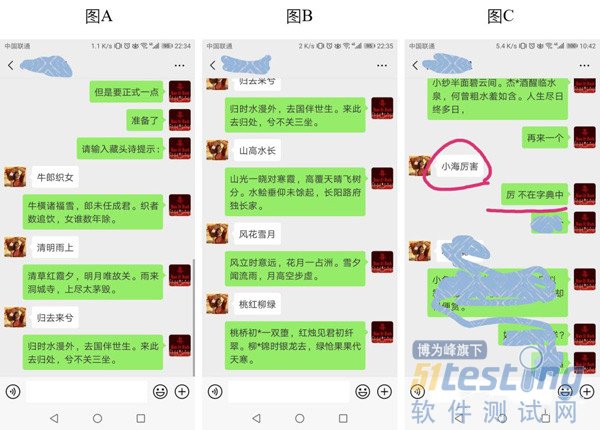
在图A中展示了做诗机器人效果,机器人输出“请输入藏头诗提示:”,当我们输入藏头诗提示时,机器人便会做出符合我们要求的藏头诗。
在图B中展示了有“*”字符存在的情况,当然由于中华文化的博大精深,也受制于训练资料的限制,当我们的藏头诗提示中存在没有在训练资料里出现的字符时,机器人便会提示该字符不在字典中,
在如图C中红色标识出来的部分,会处理异常的情况,提示不在字典中!
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












