

摘要:本文根据某大型商业银行大数据平台建设实践,论述以Hadoop为基础通过引入前沿主流的大数据开源工具搭建商业银行大数据平台的整体架构方案,并具体讨论存储引擎、资源管理、计算引擎、分析引擎、交互前端以及数据管理、任务管理、用户管理等关键技术方案。
以移动互联网、云计算、大数据和人工智能为代表的新一轮科技创新,正在快速改变传统的生产与管理方式,对商业银行的经营模式甚至中介功能形成全面冲击,商业银行能否用好大数据,加快创新实现转型,决定了其未来的可持续发展能力。传统以关系型数据仓库为基础的数据分析平台已满足不了当前业务发展的需求,商业银行需要利用以云计算、大数据为核心的技术手段,将过去单一性的平台升级至一个多样化的生态系统,使之不仅能够满足基于数据容量大、类型多、流通快的大数据基本处理需求,能够支持大数据的采集、存储、处理和分析,而且能够满足架构在可用性、可扩展性、容错性等方面的基本准则和用原始的格式来实现数据分析的基本要求。Hadoop生态系统凭借其低廉的软硬件成本、强大的并行计算能力、丰富的数据采集通道和多样化的计算查询引擎,已成为大数据技术标准和企业标配,为商业银行搭建大数据平台提供了解决方案。
本文根据某大型商业银行大数据平台建设实践,论述以Hadoop为基础通过引入前沿主流的大数据开源工具搭建商业银行大数据平台的整体架构方案,并具体讨论存储引擎、资源管理、计算引擎、分析引擎、交互前端以及数据管理、任务管理、用户管理等关键技术方案。
一、整体架构
该行大数据平台是面向全行数据分析人员的大数据生态体系,是全行大数据分析工作的实验室、工具箱和知识库。该行在数据仓库基础上引入Hadoop技术,打造“MPP+Hadoop”的双擎架构。其中,对于Hadoop的定位:一是对于大规模结构化数据,需要利用其分布式计算、高性能内存计算等提高算法效率,满足海量数据探查与分析挖掘需要;二是满足对于文本、图像等非结构化数据的存储与计算以及运用深度学习等算法使其能够进行分析挖掘并支撑应用场景;三是提供流式数据处理功能,满足实时数据获取、数据分析、数据交付等应用场景;四是利用图分析能力,满足对关系网络探查、知识图谱构建等图分析需要;五是作为大数据前沿工具、算法、方法的探索环境,探索创新性应用。
在建设过程中,该行围绕Hadoop不断跟踪大数据及相关领域的最新技术成果,深入研究大数据领域相关技术应用,在传统的SAS数据挖掘工具基础上,引入了Python、R、TensorFlow、Zeppelin、Jupyter Notebook、JanusGraph等前沿的大数据开源工具,形成包括存储引擎、资源管理、计算引擎、分析引擎、交互前端、数据管理、任务管理、用户管理等为一体的企业级Hadoop大数据平台,从而为数据分析人员提供类SQL数据查询与批处理、结构化数据分析、非结构化数据分析、流式数据分析、图分析等应用模式,以满足不同应用场景的数据分析需要。该行大数据平台整体架构如图1所示。
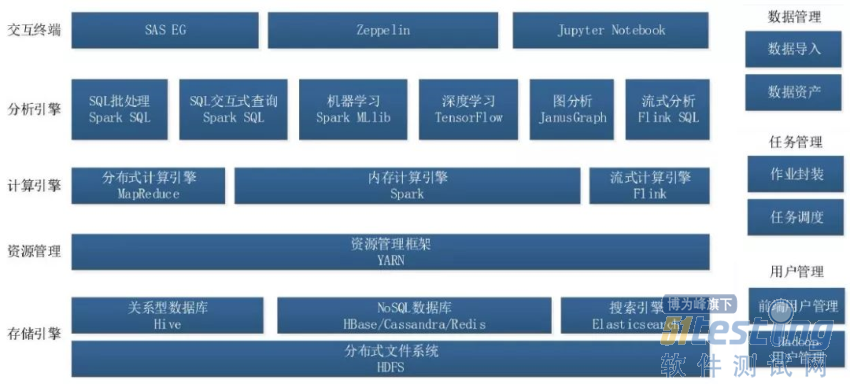
图1 大数据平台整体架构
二、关键技术方案
1.存储引擎
企业级Hadoop大数据平台需要对不同数据类型、不同应用类型的数据提供存储能力和解决方案。众所周知,商业银行多年的业务经营活动不仅积累了客户信息等大量的结构化数据,还积累了文本、图像等海量非结构化数据。同时,海量的结构化和非结构化数据聚集在一起需要进行规范、有序的管理。因此,该行Hadoop大数据平台在数据存储上,首先,根据不同数据类型划分了不同的数据区,包括半结构化数据区、结构化数据区、非结构化数据区等。其次,针对不同数据分区选择不同的存储技术实现对不同类型数据的存储需要:半结构化数据区利用HDFS组件实现对日志文件等半结构化数据的存储;结构化数据区利用Hive组件实现对客户、账户、交易等传统结构化数据的存储;非结构化数据区利用HBase的键值存储结构实现对图像等非结构化数据的存储。最后,又根据应用类型将各数据分区,细分了基础数据层和应用数据层;基础数据层作为大数据分析挖掘的基础共享数据源,应用数据层作为各个数据分析应用项目的数据加工存储区域,并按照项目周期进行数据生命周期管理。
另外,不同部门的数据访问权限控制也是一个关键点,需要在数据存储上加以考虑。该行通过Hive内外表机制和数据分区机制,实现对数据按照机构(例如分行)进行拆分,以达到控制数据访问权限的目的。
2.资源管理
企业级Hadoop大数据平台需要解决不同部门、不同场景下的不同类型作业的资源管理问题。Hadoop平台资源具体又分为计算资源(CPU和内存等)和存储资源(目录空间等)。在计算资源管理上,脱胎于MapReduce1.0的YARN成为了Hadoop2.0通用资源管理,通过队列机制可实现计算资源的分配和管理以及不同的资源调度策略。在YARN基础上的多租户技术不仅可以满足计算资源的分配管理还可以满足存储资源的配额管理、服务资源(HBase)的管理等,为Hadoop大数据平台的整体资源管理提供了解决方案。因此,该行采用Hadoop多租户机制按照不同业务部门、不同类型的作业划分不同的租户,并对租户配置相应的计算资源、存储资源、服务资源等,以实现对Hadoop资源的分配和管理。
3.计算引擎
企业级Hadoop大数据平台需要提供分布式高性能计算、实时或准时计算能力等典型计算模型的计算引擎,作为上层分析引擎的基础支撑。MapReduce作为分布式计算框架,提供了大规模数据集的分布式并行运算能力。而MapReduce为业界所诟病的重度依赖磁盘缓存中间计算结果的问题,由Spark进行了改善,提供高性能内存迭代计算框架,大幅度提高并行计算速度,特别适合数据挖掘场景下需要多次迭代的复杂运算模式。除了性能上的提升,Spark具备另外一个独特的优势:依赖基于Spark Core之上的Spark SQL、Spark MLlib等组件,Spark可以支持批处理、即席分析、数据挖掘等使用场景,为上层分析引擎提供了诸多解决方案。Flink作为大数据处理领域最近冉冉升起的一颗新星,提供高吞吐量、低延迟的针对流数据和批数据的分布式实时处理引擎,并且比Spark拥有更好的实时处理性能,目前已成为大数据领域流式计算引擎的热门技术选择。经过调研分析和选型测试工作,该行选择MapReduce、Spark、Flink组件搭建计算引擎,作为上层分析引擎的基础。
4.分析引擎
企业级Hadoop大数据平台需要提供SQL批处理、SQL交互式查询、机器学习引擎、深度学习、流式分析、图分析等分析引擎,以满足不同场景的分析需要。经过调研分析和选型测试工作,该行选择Spark SQL作为SQL批处理和交互式查询的引擎、Spark MLlib作为机器学习引擎、TensorFlow作为深度学习引擎、Flink作为流式分析引擎以及JanusGraph作为图分析引擎。
SQL批处理引擎和SQL交互式查询引擎从技术上有Hive on MapReduce、Hive on Spark、Spark SQL等候选方案。其中,Hive on MapReduce相对于Hive on Spark、Spark SQL来说具有较高的时延,不宜作为交互式查询的首选方案。而Hive on Spark和Spark SQL都是基于Spark引擎的SQL解决方案,从社区活跃度和技术发展趋势来看,Spark SQL更被推荐作为SQL引擎。
Spark MLlib作为Spark的机器学习库,由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。Spark MLlib从1.2版本以后被分为两个包:Spark.MLlib,提供基于RDD的底层API;Spark.ML,提供基于DataFrame的高层API。目前Spark官方推荐使用Spark.ML。另外,近年来随着人工智能与数据分析的深度应用,Python也得到了前所未有的高度关注,在2018年9月跃居TIOBE指数排行榜前三,因此被推荐作为SparkMLlib数据分析挖掘的首选语言。
TensorFlow是目前主流的开源深度学习框架,提供卷积神经网络(CNN)模型和循环神经网络模型(RNN),为文本分析、图像分析、自然语言处理等提供分析引擎。基于Flink并结合Hadoop技术生态中的Kafka、Redis等组件可提供实时或准实时的数据获取、数据分析、数据存储与访问为一体的流式数据分析能力。JanusGraph是一个开源的分布式图数据库,通过与Hadoop、Spark集成,提供分布式图计算引擎支持数百亿的顶点和边的图数据分析。
5.交互前端
在企业级Hadoop大数据平台上,可视化交互式的分析环境至为关键,可以帮助数据人员聚焦在数据价值的挖掘上。根据Matt Turck每年发布的大数据全景图(Big Data Landscape)报告显示,除了SAS EG外,Zeppelin和Jupyter Notebook是主流的开源可视化交互式分析工具,支持基于Hadoop的数据挖掘程序编写以及即时的图形化表示。
Zeppelin是一个基于网页的notebook,提供了数据摄取、数据发现、数据分析、数据可视化与协作等功能,并且支持多用户管理。Zeppelin核心概念是解释器(Interpreter),通过提供Python、R、Python(Apache Spark)、Spark SQL、Hive、HBase、Flink等语言的解释器支持用户使用自己熟悉的特定程序语言或数据处理方式进行数据分析与挖掘。
Jupyter Notebook也是一个交互式notebook,支持运行Python等多种编程语言,可用于数据清理和转换、数值模拟、统计建模、机器学习等。Jupyter Notebook通过搭配Jupyter Hub可提供多用户管理功能。Zeppelin和Jupyter NoteBook各有千秋,该行的方案是同时部署Zeppelin和Jupyter Notebook作为Hadoop平台的交互式分析工具,将来根据用户使用的实际情况和社区的发展情况再行抉择。
6.数据管理
企业Hadoop大数据平台需要进行规范、有序的数据管理。该行大数据平台上的数据管理主要包括数据资产管理和数据导入管理。数据资产管理主要是规划HDFS存储目录结构、制定HBase命名空间与Hive库表对象等命名规范以及提供数据资产查询功能,实现对数据资产的有效管理以及帮助用户快速使用数据。其中,HDFS目录结构需要按照机构(例如分行)、应用类型(例如数据导入作业)等维度统一规划,以便对数据文件进行有效有序的管理。数据资产查询功能用于帮助用户清晰查看平台上有哪些数据以及数据的加载频度、时间范围如何,以便用户判断平台上的数据是否足以支持大数据分析应用以及针对数据缺口提出数据导入需求。
数据导入管理负责将大数据分析工作所需要的各类数据,通过运用数据复制技术组件等手段从企业级数据仓库等数据源导入到Hadoop平台。具体而言,包括数据导入申请流程管理、数据导入操作管理、数据生命周期管理等。
7.任务管理
在企业Hadoop大数据平台上,任务的自动化运行和管理是将其大数据应用价值嵌入到业务流程的重要触手。从软件工程IPO(Input-Process-Out)的角度来说,任务管理包括对数据导入作业、数据分析作业、数据交付作业等统一的调度与监控管理。具体而言,包括利用Shell/Perl等脚本封装作业程序、配置作业依赖形成作业流、作业流部署至Control-M作业调度服务器以及监控作业流的运行状态等内容,从而形成全流程自动化的任务运行机制。
数据分析作业是指将Spark SQL、Python(Apache Spark)等语言编写的数据分析挖掘程序,通过Shell/Perl脚本进行封装,使之支持周期性执行和自动化调度。数据交付作业是指将模型结果推送到短信平台、微信公众号以及各业务系统,实现数据的线上交付。
8.用户管理
在企业级Hadoop大数据平台上,多用户管理是推广平台使用、提升平台生命力的重要基础。Hadoop大数据平台用户管理包括Hadoop用户管理和交互终端用户管理。该行在Hadoop用户管理采用了标准的RBAC模型,通过角色来定义对象的访问权限,通过给用户绑定角色来赋予用户对对象的访问权限,并利用“用户-部门-角色-权限”关系链路来指定用户的操作权限。在用户维度上,按照业务部门、业务应用的粒度来创建用户。在角色维度上,对于每一个用户都绑定了普通角色和租户角色两个角色。普通角色赋予用户对HDFS、HBase、Hive等数据对象的操作权限,租户角色赋予用户访问租户服务和资源的权限。
交互终端用户管理的目标是实现SAS、Zeppelin、Jupyter NoteBook等工具的用户统一和权限统一,支持用户只需用一套的用户名和密码登录各个工具并拥有一致的权限。结合该行已采用了基于LDAP的技术为全行提供统一的用户认证体系以及上述工具也均支持LDAP认证机制的情况,通过对上述工具进行二次开发或集成配置,实现对终端用户的统一管理和统一认证。在权限统一上,利用“终端用户-操作系统用户-Hadoop用户”关系链路来赋予终端用户访问Hadoop的资源权限。具体而言,先通过建立终端用户与操作系统用户的映射关系,即将同属一个业务部门的用户映射到同一个操作系统用户;然后利用Hadoop代理用户机制,在操作系统用户空间使用Hadoop用户Keytab文件进行身份认证,实现终端用户与Hadoop的用户映射与权限传导。
在“互联网+”“数字化”国家战略的推动下,商业银行能否用好大数据,巩固其信息资源优势,决定了其未来的可持续发展能力。迎风而动,商业银行需要更为积极主动地拥抱金融科技,不断追踪业界最新发展动态与探索前沿技术,持续提升大数据平台的能力,为数字化转型提供更强大的驱动力。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












