

作为一名在数据行业打拼了两年多的数据分析师,虽然目前收入还算ok,但每每想起房价,男儿三十还未立,内心就不免彷徨不已~
两年时间里曾经换过一份工作,一直都是从事大数据相关的行业。目前是一家企业的BI工程师,主要工作就是给业务部门出报表和业务分析报告。
回想自己过去的工作成绩也还算是不错的,多次通过自己分析告,解决了业务的疑难杂症,领导们各种离不开。
但安逸久了总会有点莫名的慌张,所以我所在的这个岗位未来会有多大发展空间,十年之后我能成为什么样的人呢?自己的收入空间还有多少?
一番惆怅之后,别再问路在何方了,于是抄起自己的“家伙”,花了一小会时间爬了智联招聘上BI岗位的数据信息,做了个分析。
PS:所用工具为Python+BI
数据分析的过程如同烧一顿饭,先要数据采集(买菜),然后数据建模(配菜)、数据清洗(洗菜)、数据分析(做菜)、数据可视化(摆盘上菜)。
所以第一步,要采集/选择数据。
一、Python爬取智联招聘岗位信息(附源码)
选择智联招聘,通过Python来进行“BI工程师”的关键数据信息的爬取,这里大家也可以试着爬取自己岗位的关键词,如“数据分析师”、“java开发工程师 ”等。经过F12分析调试,数据是以JSON的形式存储的,可以通过智联招聘提供的接口调用返回。
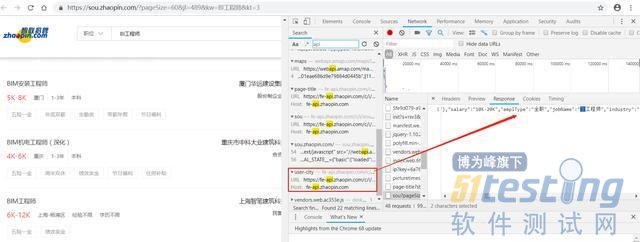
那么我这边通过Python对智联招聘网站的数据进行解析,爬取了30页数据,并且将岗位名称、公司名称、薪水、所在城市、所属行业、学历要求、工作年限这些关键信息用CSV文件保存下来。
附上完整Python源码:
import requests import json import csv from urllib.parse import urlencode import time def saveHtml(file_name,file_content): #保存conten对象为html文件 with open(file_name.replace('/','_')+'.html','wb') as f: f.write(file_content) def GetData(url,writer):#解析并将数据保存为CSV文件 response= requests.get(url) data=response.content saveHtml('zlzp',data) #保存html文件 jsondata=json.loads(data) dataList=jsondata['data']['results'] #print(jsondata) for dic in dataList: jobName=dic['jobName'] #岗位名称 company=dic['company']['name'] #公司名称 salary=dic['salary'] #薪水 city=dic['city']['display'] #城市 jobtype = dic['jobType']['display'] #所属行业 eduLevel=dic['eduLevel']['name'] #学历要求 workingExp=dic['workingExp']['name'] #工作经验 print(jobName,company,salary,city,jobtype,eduLevel,workingExp) writer.writerow([jobName,company,salary,city,jobtype,eduLevel,workingExp]) param={ 'start':0, 'pageSize':60, 'cityId':489, 'workExperience':-1, 'education':-1, 'companyType': -1, 'employmentType': -1, 'jobWelfareTag': -1, 'kw': 'BI工程师', #搜索关键词,可以根据你需要爬取的岗位信息进行更换 'kt': 3, 'lastUrlQuery': {"p":1,"pageSize":"60","jl":"681","kw":"python","kt":"3"} }#参数配置 pages=range(1,31)#爬取1-30页数据 out_f = open('test.csv', 'w', newline='') writer = csv.writer(out_f) writer.writerow(['jobName','company','salary','city','jobtype','eduLevel','workingExp']) for p in pages: #自动翻页 param['start']=(p-1)*60 param['lastUrlQuery']['p']=p url = 'https://fe-api.zhaopin.com/c/i/sou?' + urlencode(param) GetData(url,writer) time.sleep(3)#间隔休眠3秒,防止IP被封 print(p) out_f.close() |
经过一番编译调试,代码成功运行。

全部数据爬取完毕,一共1800条,保存在本地CSV文件中。
数据是爬到了,具体我想了解哪些信息呢:各城市的BI岗位需求情况以及薪资水平;薪水随工作经验的涨幅情况,以及有哪些具体的高薪岗。
由此可见,想要分析的角度很多,且看了源数据,还要做不少的数据处理。最简单快速出可视化的方法自然是用BI工具,来对数据做简单清洗加工,并呈现可视化。
BI能应付绝大多数场景的数据分析,尤其擅长多维数据切片,不需要建模;甚至数据清洗环节也能放在前端,通过过滤筛选、新建计算公式等来解决。最后呈现可视化,并可设计数据报告。
这里我用FineBI来做这样一份分析。
FineBI做分析大体是这样的流程:连接/导入数据——数据处理/清洗(过滤、筛选、新增公式列)——探索式分析——数据可视化——出报告。
二、数据清洗加工
1.薪水上下限分割:
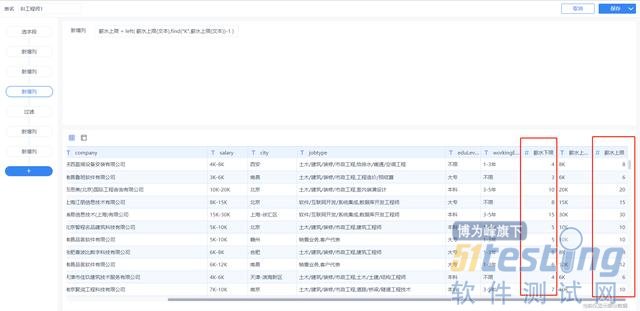
将CSV文件数据导入FineBI中(新建数据链接,建立一个分析业务包,然后导入这张excel表)。因为薪水是以xxK-xxk(还有一些类似校招/薪资面议的数据)的形式进行存储的,我这边使用FineBI新增公式列(类似excel函数)将这些字符进行分割:
薪水下限(数值):left( indexofarray ( split (salary,"-") ,1),find( "K",INDEXOFARRAY( split(salary,"-") ,1))-1)
薪水上限(含K字符):right ( indexofarray( split(salary,"-") ,2),len(salary)- find("K",indexofarray(split(salary,"-"),2 ) ) )
薪水上限(数值):left( 薪水上限(文本),find("K",薪水上限(文本))-1 )
这样就得到每个岗位的数值格式的薪水区间了:
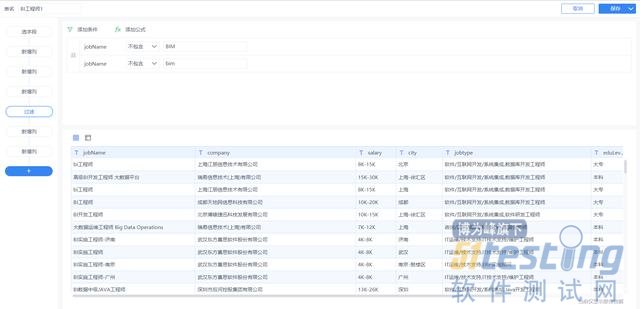
2.脏数据清洗:
浏览了一下数据,没有大问题,但是发现里面有一些类似BIM工程师的岗位信息,这些应该都是土木行业的工程师,这边我直接过滤掉即可(不包含“BIM”且不包含“bim”)。
3.岗位平均数据计算
再新增列,平均薪水=(薪水下限+薪水上限)/2,即可得到每个岗位的平均薪水。

4.真实城市截取
由于城市字段存储有的数据为“城市-区域”格式,例如“上海-徐汇区”,为了方便分析每个城市的数据,最后新增列“城市”,截取“-”前面的真实城市数据。
城市:if(find("-",city)>0 , left(city, find("-",city)-1 ),city)
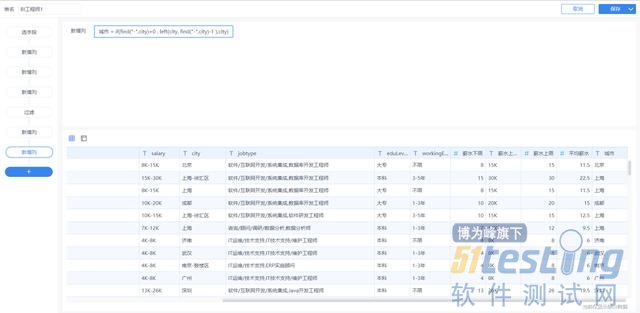
至此,18000多条数据差不多清洗完毕,食材已经全部准备好,下面可以正式开始数据可视化的美食下锅烹饪。
三、数据可视化
数据可视化可以说是很简单了,拖拽要分析的数据字段即可。
但是这里用finebi分析要理解一个思路。常规我们用excel做分析或者说做图表,是先选用钻则图表然后设定系列、数值。这里没有系列和数值的概念,只有横轴和竖轴。拖入什么字段,该字段就以该轴进行扩展,至于图表嘛,finebi会自动判别推荐。
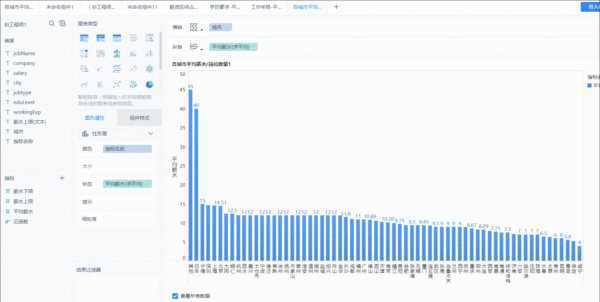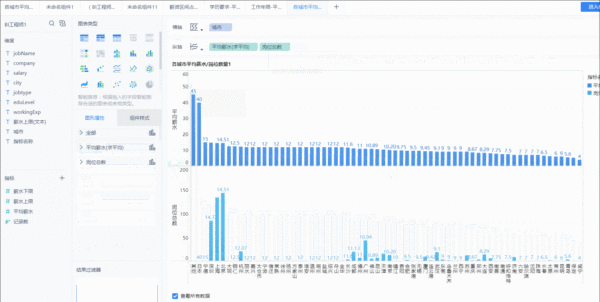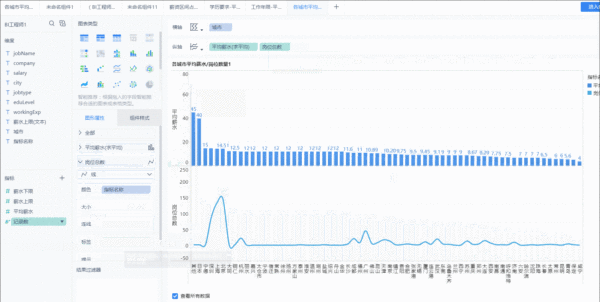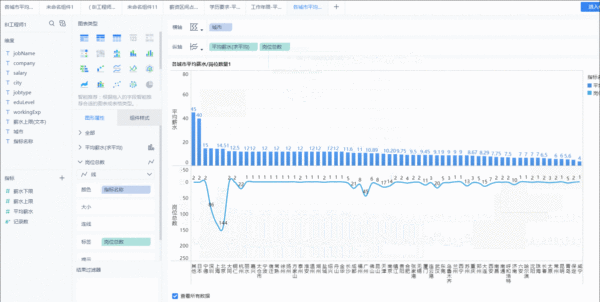
我这边以各城市平均薪水/岗位数量分析为例给大家简单展示FineBI的可视化呈现过程。
1、横轴以“城市”字段扩展,展现两类数据。先是薪水值,拖拽到纵轴,默认对数值类的字段是汇总求和的。点击字段可直接对改字段修改计算、过滤等操作。
此图来自官网,图中数据不是本次分析的数据,仅供参考
2、然后分析每个城市BI岗位的情况。将数据记录数这个指标拖入到纵轴展示。同样的方式,可以修改字段名。这里为了区分两者,将其修改为折线图,并且倒叙展示。
同理,其他图表也是这样的操作,想清楚展现什么样的数据,怎样展现,数据要作何处理。就得心应手了。其他图表就不一一赘述了。
最后,大概花了15分钟,一份完整的智联招聘网站-BI工程师岗位数据分析的可视化报告就制作完成啦~
审美有限,只能做成这样,其实这个FineBI还能做出这样的效果。


四、分析结果
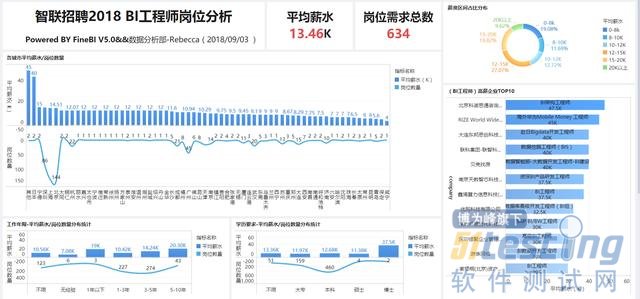
1.目前BI工程师岗位在智联招聘网站的平均薪资为13.46K(痛哭。。。拉低平均薪水的存在),主要薪水区间大概在12-15K(占比27.07%),相关工作需求总数为634个(仅仅为某一天的招聘需求数据)。
2.从城市岗位需求数量分布来看,BI工程师需求主要集中在北京、上海、深圳、广州区域;各城市BI工程师平均薪水方面,去除岗位需求量较少的城市来看,国内排在前面的分别为深圳(14.72K)、上海(14.59K)、北京(14.51)、杭州(12.07K)、成都(11.13K)、广州(10.94K)。
3.从工作年限的平均薪水和岗位需求数量来看,工作5-10年的资深BI工程师的平均薪水可以达到20K以上(朝资深BI工程师方向奋斗!!!1年以下年限的计算出来的平均薪水虽然为19K,但是由于样本量只有3个,所以参考意义不大),其中大部分的工作需求年限为3-5年,平均薪水为14.24K。
4.从学历方面来看,最低学历需求主要以本科/大专为主,本科和大专学历要求的平均薪资分别为12.68K和11.97K(感觉差距并不大,过硬的技术实力可能才是企业最为看重的吧),博士和硕士学历需求很少。
5.看了一些高薪的招聘企业,最高的可以给到30K~40K的薪酬水平,其中主要是互联网、IT类公司为主。
醍醐灌顶,顿时有了奋斗的动力~知识就是财富,继续好好学习去吧,少年!!!
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












