


我们该如何剔除各种炒作因素,潜心研究如何真正地将机器学习应用到网络安全之中呢?
首先是一条坏消息:与图像识别、自然语言处理等应用相比,机器学习在网络安全领域的落地,远达不到“银弹”的水平。
其次是一条好消息:机器学习可以协助我们完成包括回归、预测和分类在内的常见任务。这对于数据大爆炸和网络安全人才短缺的今天,无疑是一剂良药。
本文旨在向技术实务人员介绍机器学习在网络安全领域应用的现状和未来的发展方向。
机器学习术语
不要混淆“AI”一词,让我们来看看与之相关的术语。

AI(人工智能):是一个广义的概念。它是一门让机器变得聪明的科学,换言之,让机器(如:视觉识别、自然语言处理等)替人类处理各项任务。
请注意,AI 并不完全是机器学习或全面智能。它可能只是一段基本程序,被安装在扫地机器人上,用于判断墙角距离。
ML(机器学习):是将 AI 运用到系统中,实现从经验中学习的一种(或一组)方法。
其目标不仅是复制人类的行为,还旨在减少花费在诸如预测股票价格之类,繁简不同的任务上的时间和精力。
换句话说,机器学习通过使用样本和基于数据,而不是靠编程或算法,来识别模型并做出决策。
DL(深度学习):是采用机器学习,从样本中进行识别(如:图像识别)的一组技术。该系统主要识别物体的边缘、结构、类型以及对象本身。
深度学习不能完全等同于诸如 Deep Q-Learning(DQN)的深层强化神经网络(Deep Neural Networks)。
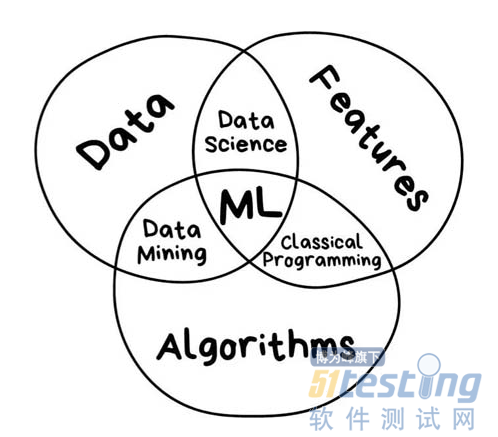
根据上述定义,由于网络安全的大部分自动化工作并不涉及到人工,所以该领域主要用到的会是机器学习,而非人工智能。即:根据获取到的数据,使用一些方法来处理某些任务。
机器学习的方法和网络安全
下面我们来讨论一下机器学习的各种方法、应用示例和能够解决的网络安全问题。
回归
回归(或称预测)是简单地通过现有数据的相关知识,来预测新的数据,例如我们可以用来预测房价的走势。
在网络安全方面,我们籍此可以根据诸如可疑交易的数量和位置等特征概率,来检查各种欺诈行为。
就回归的技术而言,我们可以分为机器学习和深度学习两大类。当然这种划分方式也适用于下面提到的其他方法。
机器学习的回归
机器学习的回归方法大致分为如下几种,它们各有利弊:
线性回归
多项式回归
岭回归
决策树
支持向量回归(Support Vector Regression,SVR)
随机森林
您可以通过以下链接,来进一步了解每一种方法:
| https://www.superdatascience.com/wp-content/uploads/2017/02/Regression-Pros-Cons.pdf |
深度学习的回归
以下是深度学习模型所采用的各种回归方法:
人工神经网络(ANN)
递归神经网络(RNN)
神经图灵机(NTM)
微神经计算机(DNC)
分类
分类是对图像进行区分,例如将两堆照片分为狗和猫两大类。在网络安全方面,我们可以籍此通过垃圾邮件过滤器,从各种邮件中甄别出真正垃圾邮件。
在事先准备好所有分类的定义和已知样本的分组之后,我们便可采用监督学习方法进行分类。
机器学习的分类:
逻辑回归(LR)
k-近邻(K-NN)
支持向量机(SVM)
核函数支持向量机(KernelSVM)
朴素贝叶斯
决策树分类
随机森林分类
业界普遍认为支持向量机和随机森林两种方法的效果最好。请记住,没有一种是放之四海而皆准的万能方法,“此之毒药,彼之蜜糖”。
深度学习的分类:
人工神经网络
卷积神经网络
只要您提供的数据越多,深度学习方法的效果就越好;不过在您的生产环境、和周期性再培训系统中,它也会消耗您更多的资源。
聚类
聚类与分类的唯一不同在于,前者面对的类信息是未知的,即:它并不知道数据是否能够被分类,因此属于无监督学习。
由于安全事件的原因、过程和后果存在着诸多不确定因素,而且需要对所有的行为进行分类,以发现蛛丝马迹,因此业界普遍认为聚类最适合取证分析。
例如,各种恶意软件防护或邮件安全网关之类的解决方案就能通过分析,从各种异常信息中发现与司法取证有关的文件。另外,聚类也可以被用于做用户行为的分析,进而将用户区分为不同的组。
通常情况下,聚类并不被用来单独地解决某项网络安全问题,而是被放置到某个处理任务的管道中,例如:将用户分为不同的组,以调整风险取值。
机器学习的聚类:
k-近邻(K-NN)
K-means算法
混合模型(LDA)
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)
贝叶斯
高斯混合模型(Gaussian Mixture Model)
Agglomerative 层次聚类
均值偏移(Mean-shift)
深度学习的聚类:
自组织映射(SOM)或 Kohonen 神经网络
关联式规则学习(推荐系统)
正如 Netflix 和 SoundCloud 会根据您的电影和音乐偏好来进行推荐那样,在网络安全方面,我们可以运用该原理来进行事件响应。
在公司使用不同类型的响应策略,来应对一大波的安全事件时,我们可以使用该系统来学习某项特定事件响应类型,通过标记出误报,进而改变其对应的风险值,以方便调查。
另外,风险管理方案可以根据预定的特征描述来为新的漏洞和错误的配置,自动分配风险值。
机器学习的关联式规则:
先验
Euclat 算法
频繁模式增长(FP-Growth)算法
深度学习的关联式规则:
深度受限玻尔兹曼机(RBM)
深度信念网络(DBN)
栈式自动编码器
降维
虽然降维(或称概括)不像分类那样常用,但它对于那些处理未标记数据、和许多潜在功能的复杂系统来说,却是必须的。
降维可以被用来协助过滤掉不必要的特征。不过就像聚类一样,它通常只是某个更为复杂的模型中的子任务。在网络安全方面,降维常被 iPhone 之类的设备用在人脸识别的整体方案中。
机器学习的降维:
主成分分析(PCA)
奇异值分解(SVD)
T-分布领域嵌入算法(T-SNE)
线性判别分析(LDA)
潜在语义分析(LSA)
因子分析(FA)
独立成分分析(ICA)
非负矩阵分解(NMF)
您可以通过以下链接了解到更多有关降维的知识:
| https://arxiv.org/pdf/1403.2877.pdf |
生成模型
上面提到的方法是根据已有信息做出决策,而生成模型则是基于过往的决策,来模拟出真实的数据。
在网络安全方面,它通过生成一个带有输入参数的列表,来测试特定应用的各种注入类型的漏洞。
另外 Web 应用的漏洞扫描工具,可以用它来测试未经授权的访问,其原理是:通过变异的文件名来识别出新的文件。
例如,生成模型中的“爬虫”在检测到名为 login.php 的文件后,就会在任何可能的备份和副本中,查找类似的文件名,如:login_1.php、login_backup.php 或 login.php.2017。
机器学习的生成模型:
马尔可夫链(Markov Chains)
各种遗传算法
深度学习的生成模型:
变分自动编码
生成对抗网络(GANs)
玻尔兹曼机
网络安全的需求和机器学习
上面我们是从机器学习方法的角度出发,讨论了可应用到网络安全中的不同场景。
现在让我们从常见的网络安全需求出发,从 Why、What 和 How 三个层面来探讨使用机器学习的机会。
第一个层面:对应的是 Why,即目标或需求(如:检测威胁和预测攻击等)。
根据 Gartner 的 PPDR(Policy Protection Detection Response)模型,所有的安全需求都可分为五大类:
预测
防御
检测
响应
监控
第二个层面:用技术来回答“What”的问题(如:在哪个方面监控问题)。
大致包括如下方面:
网络(网络流量分析和入侵检测)
终端(反恶意软件)
应用(Web 应用防火墙或数据库防火墙)
用户(用户行为分析)
流程(反欺诈)
上述每个层面都有不同的子类。例如:网络安全可以包括有线、无线或云端环境。注意:根据不同的数据依赖性,最好不要跨层面地使用相同的算法。
第三个层面:应对的是“How”的问题(例如,如何检查某个特定区域的安全)。
大致包括如下方面:
实时流量
静态数据
历史记录
就终端保护而言,您可以按照入侵检测的思想,监控某个可执行文件的各个进程,采用静态的二进制分析,并对目标终端的历史行为进行深度解析。
显然,我们在此不可能面面俱到,下面就让我们从技术层面这个角度来探讨网络安全的各种解决方案。
网络防御中的机器学习
网络防御涉及到诸如以太网、无线、SCADA(Supervisory Control And Data Acquisition,数据采集与监视控制系统)和虚拟网络等方面的解决方案。

在网络防御中,最著名的当属入侵检测系统(IDS)了。虽然它们大多数是基于签名方法的,但是近年来也一直尝试着采用机器学习来提高检测的准确度。
那么机器学习中网络安全中的一种应用就是:网络流量分析(NTA)。它通过对每个层面的网络流量进行深度分析,以发现各种攻击和异常。
下面是具体的应用示例:
通过回归算法,来预测网络包的各项参数,并将它们与正常的流量做比较。
通过分类算法,来识别诸如扫描、欺骗等不同类型的网络攻击。
通过聚类算法,来进行取证分析。
您可以通过如下 10 篇学术文章来做进一步的了解:
入侵检测中的机器学习技术
| https://arxiv.org/abs/1312.2177v2 |
在时序中运用长短时记忆网络进行异常检测
| https://www.elen.ucl.ac.be/Proceedings/esann/esannpdf/es2015-56.pdf |
通过规则提取的异常检测框架实现高效的入侵检测
| https://arxiv.org/abs/1410.7709v1 |
网络异常检测技术综述
| https://www.gta.ufrj.br/~alvarenga/files/CPE826/Ahmed2016-Survey.pdf |
深入浅出地对网络入侵检测系统进行分类与调研
| https://arxiv.org/abs/1701.02145v1 |
深度数据包:一种使用深度学习分类加密流量的新方法
| https://arxiv.org/abs/1709.02656v3 |
入侵检测系统和 Snort 系统中机器学习在应用中的性能比较
| https://arxiv.org/pdf/1710.04843v2.pdf |
在入侵检测系统中对机器学习算法的评估
| https://arxiv.org/pdf/1801.02330v1.pdf |
基于 LSTM 的类聚集式异常检测
| https://arxiv.org/pdf/1802.00324.pdf |
使用循环神经网络的流量异常检测
| https://arxiv.org/abs/1803.10769v1 |
在计算机网络流量中使用序列聚集规则进行异常检测
| https://arxiv.org/pdf/1805.03735v2.pdf |
IDS 方法大集合
| https://arxiv.org/pdf/1806.03517v1.pdf |
终端保护中的机器学习
新一代的反病毒软件是终端检测和响应(Endpoint Detection And Response),它更适合于学习各种可执行文件及其内部进程中的行为特征。

在使用机器学习来应对终端层面上的安全问题时,您的具体方案应根据终端的差异性而有所不同。
总的来说,对于工作站、服务器、容器、云实例、移动端、PLC(可编程逻辑控制器)和物联网设备等类型的终端而言,虽然它们各自的具体情况不尽相同,但是我们在方法上可以总结出如下的共性:
通过回归算法,来为可执行程序,预测下一次的系统调用,并将其与真实的进程做特征比较。
通过分类算法,将软件应用划分为恶意软件、间谍软件和勒索软件等类型。
通过聚类算法,保护邮件网关免受恶意软件的攻击,如过滤掉非法的附件。
您可以通过如下 3 篇学术文章来进一步了解终端保护和恶意软件:
恶意软件检测之:吃透可执行文件
| https://arxiv.org/pdf/1710.09435v1.pdf |
浅谈运用深度学习进行恶意软件分类
| https://arxiv.org/abs/1807.08265v1 |
跨时间与空间维度消除恶意软件分类中的实验偏差
| https://arxiv.org/abs/1807.07838v1 |
应用安全中的机器学习
应用安全不仅仅是 Web 应用防火墙和代码分析,还涉及到数据库、ERP 系统、SaaS 应用、和微服务等静态与动态方面。
因此,我们无法通过建立一个通用的机器学习模型,来有效地应对所有方面的威胁。

下面让我们试着通过几个典型场景,来讨论如何将机器学习运用到应用安全之中:
通过回归算法,检测各种异常的 HTTP 请求,如:XML 外部实体(XXE)攻击、服务器端请求伪造(SSRF)攻击和认证旁路(auth bypass)等。
通过分类算法,检测已知类型的注入攻击,如:SQLi、跨站脚本攻击(XSS)和远程命令执行(RCE)等。
通过聚类算法,检测用户的活动,以发现 DDoS 攻击和大规模的漏洞利用。
您可以通过如下 3 篇学术文章来做进一步的了解:
Web 攻击中的自适应检测恶意查询
| https://arxiv.org/pdf/1701.07774.pdf |
采用 JavaScript 和 VBScript 研究恶意脚本的神经分类
| https://arxiv.org/abs/1805.05603v1 |
URLNet:深度学习 URL 的变形模式,检测恶意网址
| https://arxiv.org/abs/1802.03162v2 |
用户行为中的机器学习
该领域的最早应用案例是:安全信息和事件管理(SIEM)。通过恰当的配置,SIEM 能够凭借对用户行为的搜索和机器学习,来实现日志的关联与分析。
不过用户和实体行为分析(UEBA)理论则认为 SIEM 无法真正处理更新的、更先进的攻击类型,以及持续的用户行为改变。

UEBA 工具需要监控的用户类型包括:域用户、应用程序用户、SaaS 用户、社交网络用户和即时通信用户等。
不同于恶意软件检测的仅根据常见的攻击,训练分类器的概率;用户行为是一个更为复杂的层面,并会涉及到无监督学习。
由于此类数据集既未被标记,又没有清晰的查找方向;因此我们同样无法为所有用户的行为,创建统一的算法。
以下是各个公司通常用到的机器学习方法:
通过回归算法,来检测用户的异常行为,如:在非常规时间登录系统。
通过分类算法,对不同类型的用户采取组内特征分析。
通过聚类算法,将违规的用户从他们组中检测和分离出来。
您可以通过如下 2 篇学术文章来做进一步的了解:
通过企业案例,探究使用扩展式隔离森林算法检测异常用户行为
| https://arxiv.org/abs/1609.06676 |
在结构化的网络安全数据流中,通过深度学习实现无监督式内部威胁检测
| https://arxiv.org/abs/1710.00811 |
流程行为中的机器学习
不同企业的业务流程可能存在着巨大的差异,我们对于银行、零售系统、和制造业中,各种欺诈行为的检查也会有所不同。
因此,只有具备一定的行业背景知识,我们才能在机器学习的功能建模和算法的选择上,更具有流程行为的针对性。

下面是被运用到工业控制系统(ICS)和数据采集与监视控制系统(SCADA)领域的通用方法:
通过回归算法,预测用户的未来行为,并检测出诸如信用卡欺诈之类的异常活动。
通过分类算法,检测已知类型的欺诈。
通过聚类算法,从正常业务流程中分拣出异常进程。
您可以通过如下 3 篇学术文章来做进一步的了解:
自编码器式欺诈
| https://shiring.github.io/machine_learning/2017/05/01/fraud |
信用卡诈骗检测技术综述之:数据和技术
| https://arxiv.org/abs/1611.06439v1 |
异常检测、工业控制系统与卷积神经网络
| https://arxiv.org/abs/1806.08110v1 |
有关机器学习的网络安全丛书
当然,如果您想了解更多关于网络安全中的机器学习,还可以参阅如下书籍:

①《网络安全中的AI》(2017)--Cylance 出版
简介:本书不厚,却能很好地介绍网络安全中的机器学习基础知识,同时配有各种实践案例。
链接:
| https://pages.cylance.com/en-us-introduction-to-ai-book.html?_ga=2.89683291.1595385041.1538052662-139740503.1538052662 |
②《机器学习和安全》(2018/01)-- O'Reilly 出版
简介:迄今为止,该领域的最好书籍,机器学习的示例较多,深度学习的范例偏少。
链接:
| http://shop.oreilly.com/product/0636920065555.do |
③《渗透测试中的机器学习》(2018/07)-- Packt 出版
简介:知识难度上较前两本有所拔高,提供更多深度学习的方法。
链接:
| https://www.packtpub.com/networking-and-servers/mastering-machine-learning-penetration-testing |
④《恶意软件的数据科学:攻击检测和属性》(2018/09)
简介:本书聚焦于恶意软件。由于它是新近出版,故尚无评论,但必将成为终端保护团队的必备书籍。
链接:
| https://nostarch.com/malwaredatascience |
结论
本文上述讨论的只是机器学习在网络安全领域应用的冰山一角。随着企业数据量的增多、系统的复杂化以及深度学习应用的不断改进,我们需要不断地通过实践,让安全防御变得越来越智能。
当然,道高一尺魔高一丈,黑客们也在各个角落里通过机器学习,努力提升他们的攻击能力。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












