

ЎЎЎЎЦ±РґКЅЈЁWrite ThroughЈ©ЈєФЪКэѕЭРґИлКэѕЭївєуЈ¬Н¬К±ёьРВ»єґжЈ¬О¬іЦКэѕЭївУл»єґжµДТ»ЦВРФЎЈХвТІКЗµ±З°ґу¶аКэУ¦УГ»єґжїтјЬИзSpring CacheµД№¤Чч·ЅКЅЎЈХвЦЦКµПЦ·ЗіЈјтµҐЈ¬Н¬ІЅєГЈ¬µ«Р§ВКТ»°гЎЈ
ЎЎЎЎ»ШРґКЅЈЁWrite BackЈ©Јєµ±УРКэѕЭТЄРґИлКэѕЭївК±Ј¬Ц»»бёьРВ»єґжЈ¬И»єуТмІЅЕъБїµДЅ«»єґжКэѕЭН¬ІЅµЅКэѕЭївЙПЎЈХвЦЦКµПЦ±ИЅПёґФУЈ¬РиТЄЅП¶аµДУ¦УГВЯјЈ¬Н¬К±їЙДЬ»бІъЙъКэѕЭївУл»єґжµДІ»Н¬ІЅЈ¬µ«Р§ВК·ЗіЈёЯЎЈ
ЎЎЎЎЛДЎў±н·ЦЗш
ЎЎЎЎMySQLФЪ5.1°жТэИлµД·ЦЗшКЗТ»ЦЦјтµҐµДЛ®ЖЅІр·ЦЈ¬УГ»§РиТЄФЪЅЁ±нµДК±єтјУЙП·ЦЗшІОКэЈ¬¶ФУ¦УГКЗНёГчµДОЮРиРЮёДґъВлЎЈ
ЎЎЎЎ¶ФУГ»§АґЛµЈ¬·ЦЗш±нКЗТ»ёц¶АБўµДВЯј±нЈ¬µ«КЗµЧІгУЙ¶аёцОпАнЧУ±нЧйіЙЈ¬КµПЦ·ЦЗшµДґъВлКµјКЙПКЗНЁ№э¶ФТ»ЧйµЧІг±нµД¶ФПу·вЧ°Ј¬µ«¶ФSQLІгАґЛµКЗТ»ёцНкИ«·вЧ°µЧІгµДєЪєРЧУЎЈMySQLКµПЦ·ЦЗшµД·ЅКЅТІТвО¶ЧЕЛчТэТІКЗ°ґХХ·ЦЗшµДЧУ±н¶ЁТеЈ¬Г»УРИ«ѕЦЛчТэЎЈ
ЎЎЎЎУГ»§µДSQLУпѕдКЗРиТЄХл¶Ф·ЦЗш±нЧцУЕ»ЇЈ¬SQLМхјюЦРТЄґшЙП·ЦЗшМхјюµДБРЈ¬ґУ¶шК№ІйСЇ¶ЁО»µЅЙЩБїµД·ЦЗшЙПЈ¬·сФтѕН»бЙЁГиИ«Ії·ЦЗшЈ¬їЙТФНЁ№эEXPLAIN PARTITIONSАґІйїґДіМхSQLУпѕд»бВдФЪДЗР©·ЦЗшЙПЈ¬ґУ¶шЅшРРSQLУЕ»ЇЈ¬ИзПВНј5МхјЗВјВдФЪБЅёц·ЦЗшЙПЈє
| ЎЎЎЎmysql> explain partitions select count(1) from user_partition where id in (1,2,3,4,5); ЎЎЎЎ+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+ ЎЎЎЎ| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra | ЎЎЎЎ| 1 | SIMPLE | user_partition | p1,p4 | range | PRIMARY | PRIMARY | 8 | | 5 | Using where; Using index | ЎЎЎЎ1 row in set (0.00 sec) |
ЎЎЎЎ·ЦЗшµДєГґ¦КЗЈє
ЎЎЎЎїЙТФИГµҐ±нґжґўёь¶аµДКэѕЭЈ»
ЎЎЎЎ·ЦЗш±нµДКэѕЭёьИЭТЧО¬»¤Ј¬їЙТФНЁ№эЗеіюХыёц·ЦЗшЕъБїЙѕіэґуБїКэѕЭЈ¬ТІїЙТФФцјУРВµД·ЦЗшАґЦ§іЦРВІеИлµДКэѕЭЈ¬БнНвЈ¬»№їЙТФ¶ФТ»ёц¶АБў·ЦЗшЅшРРУЕ»ЇЎўјмІйЎўРЮёґµИІЩЧчЈ»
ЎЎЎЎІї·ЦІйСЇДЬ№»ґУІйСЇМхјюИ·¶ЁЦ»ВдФЪЙЩКэ·ЦЗшЙПЈ¬ЛЩ¶И»бєЬїмЈ»
ЎЎЎЎ·ЦЗш±нµДКэѕЭ»№їЙТФ·ЦІјФЪІ»Н¬µДОпАнЙи±ёЙПЈ¬ґУ¶шёгР¦АыУГ¶аёцУІјюЙи±ёЈ»
ЎЎЎЎїЙТФК№УГ·ЦЗш±нАµ±ЬГвДіР©МШКвЖїѕ±Ј¬АэИзInnoDBµҐёцЛчТэµД»Ґів·ГОКЎўext3ОДјюПµНіµДinodeЛшѕєХщЈ»
ЎЎЎЎїЙТФ±ё·ЭєН»ЦёґµҐёц·ЦЗшЎЈ
ЎЎЎЎ·ЦЗшµДПЮЦЖєНИ±µгЈє
ЎЎЎЎТ»ёц±нЧо¶аЦ»ДЬУР1024ёц·ЦЗшЈ»
ЎЎЎЎИз№ы·ЦЗшЧЦ¶ОЦРУРЦчјь»тХЯОЁТ»ЛчТэµДБРЈ¬ДЗГґЛщУРЦчјьБРєНОЁТ»ЛчТэБР¶ј±ШРл°ьє¬ЅшАґЈ»
ЎЎЎЎ·ЦЗш±нОЮ·ЁК№УГНвјьФјКшЈ»
ЎЎЎЎЦµ»бК№·ЦЗш№эВЛОЮР§Ј»
ЎЎЎЎЛщУР·ЦЗш±ШРлК№УГПаН¬µДґжґўТэЗжЎЈ
ЎЎЎЎ·ЦЗшµДАаРНЈє
ЎЎЎЎRANGE·ЦЗшЈє»щУЪКфУЪТ»ёцёш¶ЁБ¬РшЗшјдµДБРЦµЈ¬°С¶аРР·ЦЕдёш·ЦЗшЎЈ
ЎЎЎЎLIST·ЦЗшЈєАаЛЖУЪ°ґRANGE·ЦЗшЈ¬Зш±рФЪУЪLIST·ЦЗшКЗ»щУЪБРЦµЖҐЕдТ»ёцАлЙўЦµјЇєПЦРµДДіёцЦµАґЅшРРСЎФсЎЈ
ЎЎЎЎHASH·ЦЗшЈє»щУЪУГ»§¶ЁТеµД±нґпКЅµД·µ»ШЦµАґЅшРРСЎФсµД·ЦЗшЈ¬ёГ±нґпКЅК№УГЅ«ТЄІеИлµЅ±нЦРµДХвР©РРµДБРЦµЅшРРјЖЛгЎЈХвёцєЇКэїЙТФ°ьє¬MySQLЦРУРР§µДЎўІъЙъ·ЗёєХыКэЦµµДИОєО±нґпКЅЎЈ
ЎЎЎЎKEY·ЦЗшЈєАаЛЖУЪ°ґHASH·ЦЗшЈ¬Зш±рФЪУЪKEY·ЦЗшЦ»Ц§іЦјЖЛгТ»БР»т¶аБРЈ¬ЗТMySQL·юОсЖчМṩЖдЧФЙнµД№юПЈєЇКэЎЈ±ШРлУРТ»БР»т¶аБР°ьє¬ХыКэЦµЎЈ
ЎЎЎЎ·ЦЗшККєПµДіЎѕ°УРЈє
ЎЎЎЎЧоККєПµДіЎѕ°КэѕЭµДК±јдРтБРРФ±ИЅПЗїЈ¬ФтїЙТФ°ґК±јдАґ·ЦЗшЈ¬ИзПВЛщКѕЈє
ЎЎЎЎCREATE TABLE members ( ЎЎЎЎfirstname VARCHAR(25) NOT , ЎЎЎЎlastname VARCHAR(25) NOT , ЎЎЎЎusername VARCHAR(16) NOT , ЎЎЎЎemail VARCHAR(35), ЎЎЎЎjoined DATE NOT ЎЎЎЎ)PARTITION BY RANGE( YEAR(joined) ) ( ЎЎЎЎPARTITION p0 VALUES LESS THAN (1960), ЎЎЎЎPARTITION p1 VALUES LESS THAN (1970), ЎЎЎЎPARTITION p2 VALUES LESS THAN (1980), ЎЎЎЎPARTITION p3 VALUES LESS THAN (1990), ЎЎЎЎPARTITION p4 VALUES LESS THAN MAXVALUE ЎЎЎЎ); |
ЎЎЎЎІйСЇК±јУЙПК±јд·¶О§МхјюР§ВК»б·ЗіЈёЯЈ¬Н¬К±¶ФУЪІ»РиТЄµДАъК·КэѕЭДЬєЬИЭµДЕъБїЙѕіэЎЈ
ЎЎЎЎИз№ыКэѕЭУРГчПФµДИИµгЈ¬¶шЗТіэБЛХвІї·ЦКэѕЭЈ¬ЖдЛыКэѕЭєЬЙЩ±»·ГОКµЅЈ¬ДЗГґїЙТФЅ«ИИµгКэѕЭµҐ¶А·ЕФЪТ»ёц·ЦЗшЈ¬ИГХвёц·ЦЗшµДКэѕЭДЬ№»УР»ъ»б¶ј»єґжФЪДЪґжЦРЈ¬ІйСЇК±Ц»·ГОКТ»ёцєЬРЎµД·ЦЗш±нЈ¬ДЬ№»УРР§К№УГЛчТэєН»єґжЎЈ
ЎЎЎЎБнНвMySQLУРТ»ЦЦФзЖЪµДјтµҐµД·ЦЗшКµПЦ - єПІў±нЈЁmerge tableЈ©Ј¬ПЮЦЖЅП¶аЗТИ±·¦УЕ»ЇЈ¬І»ЅЁТйК№УГЈ¬У¦ёГУГРВµД·ЦЗш»ъЦЖАґМжґъЎЈ
ЎЎЎЎОеЎўґ№Ц±Ір·Ц
ЎЎЎЎґ№Ц±·ЦївКЗёщѕЭКэѕЭївАпГжµДКэѕЭ±нµДПа№ШРФЅшРРІр·ЦЈ¬±ИИзЈєТ»ёцКэѕЭївАпГжјИґжФЪУГ»§КэѕЭЈ¬УЦґжФЪ¶©µҐКэѕЭЈ¬ДЗГґґ№Ц±Ір·ЦїЙТФ°СУГ»§КэѕЭ·ЕµЅУГ»§ївЎў°С¶©µҐКэѕЭ·ЕµЅ¶©µҐївЎЈ
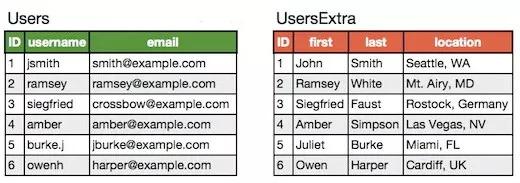
ЎЎЎЎґ№Ц±·Ц±нКЗ¶ФКэѕЭ±нЅшРРґ№Ц±Ір·ЦµДТ»ЦЦ·ЅКЅЈ¬іЈјыµДКЗ°СТ»ёц¶аЧЦ¶ОµДґу±н°ґіЈУГЧЦ¶ОєН·ЗіЈУГЧЦ¶ОЅшРРІр·ЦЈ¬Гїёц±нАпГжµДКэѕЭјЗВјКэТ»°гЗйїцПВКЗПаН¬µДЈ¬Ц»КЗЧЦ¶ОІ»Т»СщЈ¬К№УГЦчјь№ШБЄЎЈ
ЎЎЎЎ±ИИзФКјµДУГ»§±нКЗЈє

ЎЎЎЎґ№Ц±Ір·ЦєуКЗЈє
ЎЎЎЎґ№Ц±Ір·ЦµДУЕµгКЗЈє
ЎЎЎЎїЙТФК№µГРРКэѕЭ±дРЎЈ¬Т»ёцКэѕЭїй(Block)ѕНДЬґж·Еёь¶аµДКэѕЭЈ¬ФЪІйСЇК±ѕН»бјхЙЩI/OґОКэ(ГїґОІйСЇК±¶БИЎµДBlock ѕНЙЩ)Ј»
ЎЎЎЎїЙТФґпµЅЧоґу»ЇАыУГCacheµДДїµДЈ¬ѕЯМеФЪґ№Ц±Ір·ЦµДК±єтїЙТФЅ«І»іЈ±дµДЧЦ¶О·ЕТ»ЖрЈ¬Ѕ«ѕіЈёД±дµД·ЕТ»ЖрЈ»
ЎЎЎЎКэѕЭО¬»¤јтµҐЎЈ
ЎЎЎЎИ±µгКЗЈє
ЎЎЎЎЦчјьіцПЦИЯУаЈ¬РиТЄ№ЬАнИЯУаБРЈ»
ЎЎЎЎ»бТэЖр±нБ¬ЅУJOINІЩЧчЈЁФцјУCPUїЄПъЈ©їЙТФНЁ№эФЪТµОс·юОсЖчЙПЅшРРjoinАґјхЙЩКэѕЭївС№Б¦Ј»
ЎЎЎЎТАИ»ґжФЪµҐ±нКэѕЭБї№эґуµДОКМвЈЁРиТЄЛ®ЖЅІр·ЦЈ©ЎЈ
ЎЎЎЎКВОсґ¦АнёґФУЎЈ
ЎЎЎЎБщЎўЛ®ЖЅІр·Ц
ЎЎЎЎ1ёЕКц
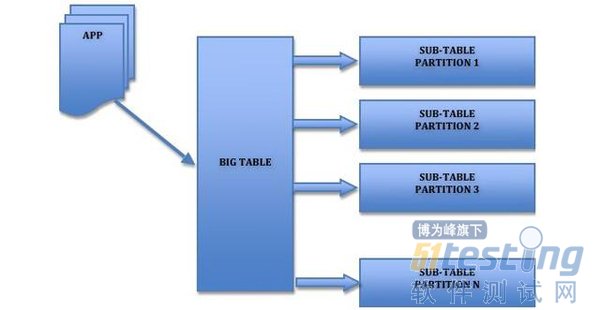
ЎЎЎЎЛ®ЖЅІр·ЦКЗНЁ№эДіЦЦІЯВФЅ«КэѕЭ·ЦЖ¬АґґжґўЈ¬·ЦївДЪ·Ц±нєН·ЦївБЅІї·ЦЈ¬ГїЖ¬КэѕЭ»б·ЦЙўµЅІ»Н¬µДMySQL±н»тївЈ¬ґпµЅ·ЦІјКЅµДР§№ыЈ¬ДЬ№»Ц§іЦ·ЗіЈґуµДКэѕЭБїЎЈЗ°ГжµД±н·ЦЗш±ѕЦКЙПТІКЗТ»ЦЦМШКвµДївДЪ·Ц±нЎЈ
ЎЎЎЎївДЪ·Ц±нЈ¬ЅцЅцКЗµҐґїµДЅвѕцБЛµҐТ»±нКэѕЭ№эґуµДОКМвЈ¬УЙУЪГ»УаѱнµДКэѕЭ·ЦІјµЅІ»Н¬µД»ъЖчЙПЈ¬ТтґЛ¶ФУЪјхЗбMySQL·юОсЖчµДС№Б¦АґЛµЈ¬ІўГ»УРМ«ґуµДЧчУГЈ¬ґујТ»№КЗѕєХщН¬Т»ёцОпАн»ъЙПµДIOЎўCPUЎўНшВзЈ¬ХвёцѕНТЄНЁ№э·ЦївАґЅвѕцЎЈ
ЎЎЎЎЗ°Гжґ№Ц±Ір·ЦµДУГ»§±нИз№ыЅшРРЛ®ЖЅІр·ЦЈ¬Ѕб№ыКЗЈє
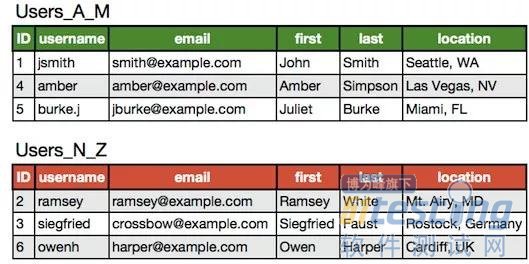
ЎЎЎЎКµјКЗйїцЦРНщНщ»бКЗґ№Ц±Ір·ЦєНЛ®ЖЅІр·ЦµДЅбєПЈ¬јґЅ«Users_A_MєНUsers_N_ZФЩІріЙUsersєНUserExtrasЈ¬ХвСщТ»№ІЛДХЕ±нЎЈ
ЎЎЎЎЛ®ЖЅІр·ЦµДУЕµгКЗЈє
ЎЎЎЎІ»ґжФЪµҐївґуКэѕЭєНёЯІў·ўµДРФДЬЖїѕ±Ј»
ЎЎЎЎУ¦УГ¶ЛёДФмЅПЙЩЈ»
ЎЎЎЎМбёЯБЛПµНіµДОИ¶ЁРФєНёєФШДЬБ¦ЎЈ
ЎЎЎЎИ±µгКЗЈє
ЎЎЎЎ·ЦЖ¬КВОсТ»ЦВРФДСТФЅвѕцЈ»
ЎЎЎЎїзЅЪµгJoinРФДЬІоЈ¬ВЯјёґФУЈ»
ЎЎЎЎКэѕЭ¶аґОА©Х№ДС¶ИёъО¬»¤Бїј«ґуЎЈ
ЎЎЎЎ2·ЦЖ¬ФФт
ЎЎЎЎДЬІ»·ЦѕНІ»·ЦЈ¬ІОїјµҐ±нУЕ»ЇЈ»
ЎЎЎЎ·ЦЖ¬КэБїѕЎБїЙЩЈ¬·ЦЖ¬ѕЎБїѕщФИ·ЦІјФЪ¶аёцКэѕЭЅбµгЙПЈ¬ТтОЄТ»ёцІйСЇSQLїз·ЦЖ¬ФЅ¶аЈ¬ФтЧЬМеРФДЬФЅІоЈ¬ЛдИ»ТЄєГУЪЛщУРКэѕЭФЪТ»ёц·ЦЖ¬µДЅб№ыЈ¬Ц»ФЪ±ШТЄµДК±єтЅшРРА©ИЭЈ¬ФцјУ·ЦЖ¬КэБїЈ»
ЎЎЎЎ·ЦЖ¬№жФтРиТЄЙчЦШСЎФсЧцєГМбЗ°№ж»®Ј¬·ЦЖ¬№жФтµДСЎФсЈ¬РиТЄїјВЗКэѕЭµДФці¤ДЈКЅЈ¬КэѕЭµД·ГОКДЈКЅЈ¬·ЦЖ¬№ШБЄРФОКМвЈ¬ТФј°·ЦЖ¬А©ИЭОКМвЈ¬ЧоЅьµД·ЦЖ¬ІЯВФОЄ·¶О§·ЦЖ¬Ј¬Г¶ѕЩ·ЦЖ¬Ј¬Т»ЦВРФHash·ЦЖ¬Ј¬ХвјёЦЦ·ЦЖ¬¶јУРАыУЪА©ИЭЈ»
ЎЎЎЎѕЎБїІ»ТЄФЪТ»ёцКВОсЦРµДSQLїзФЅ¶аёц·ЦЖ¬Ј¬·ЦІјКЅКВОсТ»Ц±КЗёцІ»єГґ¦АнµДОКМвЈ»
ЎЎЎЎІйСЇМхјюѕЎБїУЕ»ЇЈ¬ѕЎБї±ЬГвSelect * µД·ЅКЅЈ¬ґуБїКэѕЭЅб№ыјЇПВЈ¬»бПыєДґуБїґшїнєНCPUЧКФґЈ¬ІйСЇѕЎБї±ЬГв·µ»ШґуБїЅб№ыјЇЈ¬ІўЗТѕЎБїОЄЖµ·±К№УГµДІйСЇУпѕдЅЁБўЛчТэЈ»
ЎЎЎЎНЁ№эКэѕЭИЯУаєН±н·ЦЗшАµЅµµНїзївJoinµДїЙДЬЎЈ
ЎЎЎЎХвАпМШ±рЗїµчТ»ПВ·ЦЖ¬№жФтµДСЎФсОКМвЈ¬Из№ыДіёц±нµДКэѕЭУРГчПФµДК±јдМШХчЈ¬±ИИ綩µҐЎўЅ»ТЧјЗВјµИЈ¬ФтЛыГЗНЁіЈ±ИЅПєПККУГК±јд·¶О§·ЦЖ¬Ј¬ТтОЄѕЯУРК±Р§РФµДКэѕЭЈ¬ОТГЗНщНщ№ШЧўЖдЅьЖЪµДКэѕЭЈ¬ІйСЇМхјюЦРНщНщґшУРК±јдЧЦ¶ОЅшРР№эВЛЈ¬±ИЅПєГµД·Ѕ°ёКЗЈ¬µ±З°»оФѕµДКэѕЭЈ¬ІЙУГїз¶И±ИЅП¶МµДК±јд¶ОЅшРР·ЦЖ¬Ј¬¶шАъК·РФµДКэѕЭЈ¬ФтІЙУГ±ИЅПі¤µДїз¶ИґжґўЎЈ
ЎЎЎЎЧЬМеЙПАґЛµЈ¬·ЦЖ¬µДСЎФсКЗИЎѕцУЪЧоЖµ·±µДІйСЇSQLµДМхјюЈ¬ТтОЄІ»ґшИОєОWhereУпѕдµДІйСЇSQLЈ¬»б±йАъЛщУРµД·ЦЖ¬Ј¬РФДЬПа¶ФЧоІоЈ¬ТтґЛХвЦЦSQLФЅ¶аЈ¬¶ФПµНіµДУ°ПмФЅґуЈ¬ЛщТФОТГЗТЄѕЎБї±ЬГвХвЦЦSQLµДІъЙъЎЈ
ЎЎЎЎ3Ѕвѕц·Ѕ°ё
ЎЎЎЎУЙУЪЛ®ЖЅІр·ЦЗЈЙжµДВЯј±ИЅПёґФУЈ¬µ±З°ТІУРБЛІ»ЙЩ±ИЅПіЙКмµДЅвѕц·Ѕ°ёЎЈХвР©·Ѕ°ё·ЦОЄБЅґуАаЈєїН»§¶ЛјЬ№№єНґъАнјЬ№№ЎЈ
ЎЎЎЎїН»§¶ЛјЬ№№
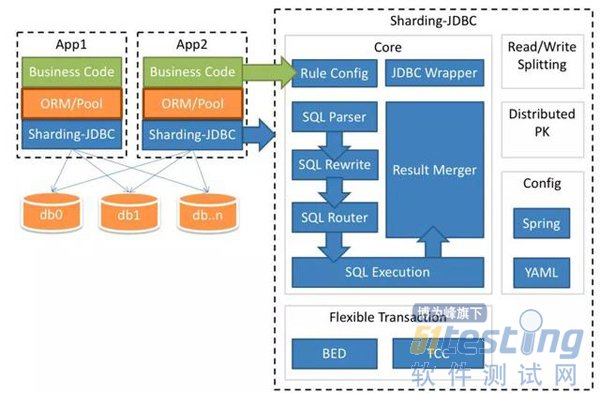
ЎЎЎЎНЁ№эРЮёДКэѕЭ·ГОКІгЈ¬ИзJDBCЎўData SourceЎўMyBatisЈ¬НЁ№эЕдЦГАґ№ЬАн¶аёцКэѕЭФґЈ¬Ц±Б¬КэѕЭївЈ¬ІўФЪДЈїйДЪНкіЙКэѕЭµД·ЦЖ¬ХыєПЈ¬Т»°гТФJar°ьµД·ЅКЅіКПЦЎЈ
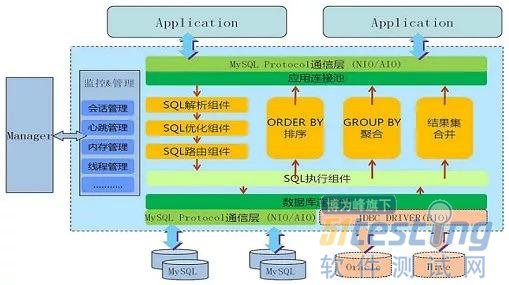
ЎЎЎЎХвКЗТ»ёцїН»§¶ЛјЬ№№µДАэЧУЈє
ЎЎЎЎїЙТФїґµЅ·ЦЖ¬µДКµПЦКЗєНУ¦УГ·юОсЖчФЪТ»ЖрµДЈ¬НЁ№эРЮёДSpring JDBCІгАґКµПЦЎЈ
ЎЎЎЎїН»§¶ЛјЬ№№µДУЕµгКЗЈє
ЎЎЎЎУ¦УГЦ±Б¬КэѕЭївЈ¬ЅµµННвО§ПµНіТААµЛщґшАґµДеґ»ъ·зПХЈ»
ЎЎЎЎјЇіЙіЙ±ѕµНЈ¬ОЮРи¶оНвФЛО¬µДЧйјюЎЈ
ЎЎЎЎИ±µгКЗЈє
ЎЎЎЎПЮУЪЦ»ДЬФЪКэѕЭїв·ГОКІгЙПЧцОДХВЈ¬А©Х№РФТ»°гЈ¬¶ФУЪ±ИЅПёґФУµДПµНіїЙДЬ»бБ¦І»ґУРДЈ»
ЎЎЎЎЅ«·ЦЖ¬ВЯјµДС№Б¦·ЕФЪУ¦УГ·юОсЖчЙПЈ¬ФміЙ¶оНв·зПХЎЈ
ЎЎЎЎґъАнјЬ№№
ЎЎЎЎНЁ№э¶АБўµДЦРјдјюАґНіТ»№ЬАнЛщУРКэѕЭФґєНКэѕЭ·ЦЖ¬ХыєПЈ¬єу¶ЛКэѕЭївјЇИє¶ФЗ°¶ЛУ¦УГіМРтНёГчЈ¬РиТЄ¶АБўІїКрєНФЛО¬ґъАнЧйјюЎЈ
ЎЎЎЎХвКЗТ»ёцґъАнјЬ№№µДАэЧУЈє
ЎЎЎЎґъАнЧйјюОЄБЛ·ЦБчєН·АЦ№µҐµгЈ¬Т»°гТФјЇИєРОКЅґжФЪЈ¬Н¬К±їЙДЬРиТЄZookeeperЦ®АаµД·юОсЧйјюАґ№ЬАнЎЈ
ЎЎЎЎґъАнјЬ№№µДУЕµгКЗЈє
ЎЎЎЎДЬ№»ґ¦Ан·ЗіЈёґФУµДРиЗуЈ¬І»КЬКэѕЭїв·ГОКІгФАґКµПЦµДПЮЦЖЈ¬А©Х№РФЗїЈ»
ЎЎЎЎ¶ФУЪУ¦УГ·юОсЖчНёГчЗТГ»УРФцјУИОєО¶оНвёєФШЎЈ
ЎЎЎЎИ±µгКЗЈє
ЎЎЎЎРиІїКрєНФЛО¬¶АБўµДґъАнЦРјдјюЈ¬іЙ±ѕёЯЈ»
ЎЎЎЎУ¦УГРиѕ№эґъАнАґБ¬ЅУКэѕЭївЈ¬НшВзЙП¶аБЛТ»МшЈ¬РФДЬУРЛрК§ЗТУР¶оНв·зПХЎЈ
ЎЎЎЎДїЗ°АґЛµЈ¬ТµЅз»№КЗУРєЬ¶аµД·Ѕ°ёїЙ№©СЎФсЈ¬µ«У¦ёГИзєОЅшРРСЎФсЈїОТИПОЄЈ¬їЙТФ°ґТФПВЛјВ·АґїјВЗЈє
ЎЎЎЎИ·¶ЁКЗК№УГґъАнјЬ№№»№КЗїН»§¶ЛјЬ№№ЎЈЦРРЎРН№жДЈ»тКЗ±ИЅПјтµҐµДіЎѕ°ЗгПтУЪСЎФсїН»§¶ЛјЬ№№Ј¬ёґФУіЎѕ°»тґу№жДЈПµНіЗгПтСЎФсґъАнјЬ№№ЎЈ
ЎЎЎЎѕЯМ幦ДЬКЗ·сВъЧгЈ¬±ИИзРиТЄїзЅЪµгORDER BYЈ¬ДЗГґЦ§іЦёГ№¦ДЬµДУЕПИїјВЗЎЈ
ЎЎЎЎІ»їјВЗТ»ДкДЪГ»УРёьРВµДІъЖ·Ј¬ЛµГчїЄ·ўНЈЦНЈ¬ЙхЦБОЮИЛО¬»¤єНјјКхЦ§іЦЎЈ
ЎЎЎЎЧоєГ°ґґу№«ЛѕЎъЙзЗшЎъРЎ№«ЛѕЎъёцИЛХвСщµДіцЖ··ЅЛіРтАґСЎФсЎЈ
ЎЎЎЎСЎФсїЪ±®ЅПєГµДЈ¬±ИИзgithubРЗКэЎўК№УГХЯКэБїЦКБїєНК№УГХЯ·ґАЎЎЈ
ЎЎЎЎїЄФґµДУЕПИЈ¬НщНщПоДїУРМШКвРиЗуїЙДЬРиТЄёД¶ЇФґґъВлЎЈ
ЙПОДДЪИЭІ»УГУЪЙМТµДїµДЈ¬ИзЙжј°ЦЄК¶ІъИЁОКМвЈ¬ЗлИЁАыИЛБЄПµІ©ОЄ·еРЎ±а(021-64471599-8017)Ј¬ОТГЗЅ«Бўјґґ¦АнЎЈ












