

试想如果手工测试发现不了问题,那么基于测试用例转换的自动化测试,又怎么能帮我们发现更多的问题呢?虽然自动化测试的定义更多的是帮助我们回归并且验证核心功能是否受到影响。
总而言之,测试用例是测试工作的核心,是测试活动开展的重要依赖,是基线测试覆盖的重要支撑。
先回顾下上篇文章最后结尾处的一些内容:
“总之,测试有3种分析
基于需求的分析
基于用户的分析
基于风险的分析
测试也有2种设计
基于状态的设计
基于数据的设计”
这次,我们就把测试的2种设计,好好的讲一讲。
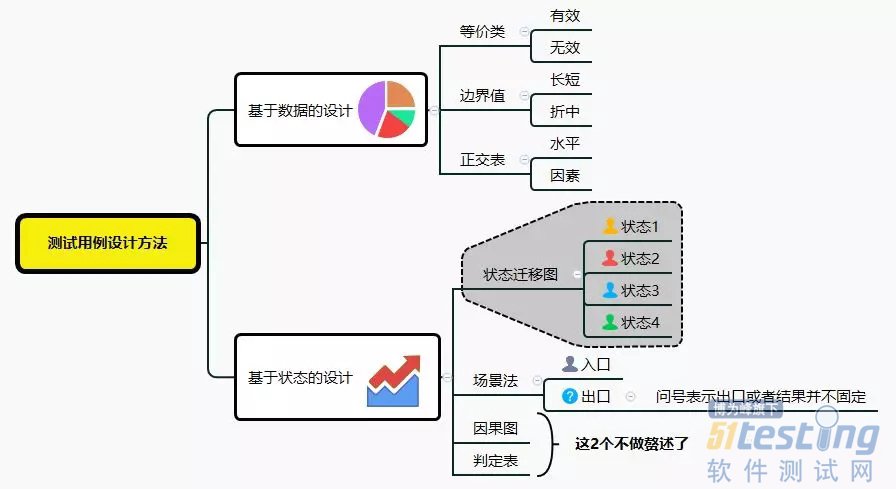
说起用例,大家不陌生的一定是测试用例的设计方法。等价类、边界值、因果图、判定表、状态迁移图、场景法、正交等等。。。(这里我们就暂时先忽略错误推测法及其他的设计方法吧,相比错误推测法,我更建议探索性测试,一定比错误推测、即兴测试来的更好,也更有迹可循。)
我们仔细分析下,首先,
结论一:
A,等价类和边界值,做为常用的组合,经常出现在数据设计类型上,比如登录、注册、表单、信息获取等等
B,因果图和判定表,常用于简单情况下的结果验证,更适用于不复杂的场景,或者权限、或者1个操作影响多个结果的时候
C,状态迁移图、场景法,更多的适合于一连串操作或者较复杂的场景结合、或者有多种状态之前切换且可能无序的时候,比如说账号的状态有正常、禁用、冻结、废弃等,那么每一种状态之间的转换,就极其适合状态迁移图,而经典的ATM机取钱的例子,就很好的解释了场景法是如何使用的。在于用户从开头到结尾,有多种可能,多种路径时的设计
D,正交法,大家用的较少,因为设计出来的用例很多,大部分适合于因素和水平不多的时候,那么当多的时候怎么办呢?首先,可以使用正交表用例生成器(这里大家可以自行百度下进行下载),完成后,按照单失效模式和双失效模式进行用例的优化(原文出自2011年,51testing上作者的分享,http://www.51testing.com/html/22/n-235122.html,如何有效减少测试用例数目)。当然,正交其实我们也可以认为是数据驱动的。
所以我们进一步归纳下:
结论二:
场景法、状态迁移图、因果图、判定表则为基于状态的设计(有人会写成基于场景的设计,大致一样),更多的应用到测试用例设计过程中,是测试用例基于面的覆盖,基于用户可能的覆盖,影响了用例的广度。同时,基于用户重点场景的验证,也是UI层最优先应该覆盖的地方。
等价类、边界值、正交表则为基于数据的设计,更多的应用到测试用例设计过程中,是测试用例基于面覆盖之后,基于点的设计,影响了用例的深度。同时这部分用例可能数量较多、而优先级较低,所以,这部分是API接口层最好覆盖的地方。
总结起来如下图
接下来,我们回顾下到底什么是测试用例,这里引用一句话:
“A test case is a set of conditions or variables under which a tester will determine whether a system under test satisfies requirements and works correctly.”
关键词:
条件、数据、满足要求、正常工作
这应该算是非常正确的测试用例的解释了,同时我在补充一句吧,测试用例是控制、度量测试行为的重要产物。
另外,再给大家一些建议,是如何更好的划分用例的优先级的。
大部分公司会采用3级或者4级的用例,貌似更多的是4级,这里我们用4级来举个例子,同时常规的用例占比大致如此:
Smoking Test(S):冒烟级别用例,大概占用例的10%~15%,是最核心的功能
Hign Lever Test(H):高优先级的用例,大概占用例的25%~30%,同时,包含Smoking Test
Regression Test(R):回归测试用例,大概占用例的50%左右,同时,向上包含前2种用例
Function Test(F):功能用例,100%,全部用例。
建议用例级别的划分标准和设计方法对应关系:
场景法:
基本流为S级别用例
备选流按照操作频率为H或者R
状态迁移图:
正向状态或者核心状态为S级别
其余为H或者R
因果图和判定表:
如果不涉及核心功能或者重要场景,则按照H、R处理
等价类:
有效为S或者H
无效为R、F
边界值:
中间为R、两边为F(这里应该和很多人想的不一样了,因为级别已经比较低了)
正交表:
单失效模式为H,双失效为R,其余为F(当然很多时候其余可能不会写入测试用例中)
这样子的话,测试用例的设计和级别就出来了。他就已经构成一个立体式的测试用例了。有的人会发现还少了测试数据,这个测试用例的重要组成部分,是条件或者结果中重要的内容。我们也一并说下吧
测试数据大致有3种设计方法:
A,如果被测物为更新版本,则表示之前已经有实际数据产生,则通过实际数据的挖掘进而设计测试数据
B,如果被测物为新产品,同时又有很多竞品可以参考,则通过竞品的分析,目标用户,用户行为,用户量的分析进行设计
C,如果被测物为新产品,而又没有可借鉴的同类产品进行分析,则就得完全通过需求、用户可能的场景进行分析,同时考虑上线后一段时间的目标进而得出综合的设计
其实有2点可以判断测试用例是否足够好(这里我们假定测试用例没有明显的遗漏缺失)
A,是否可以让新人不用看产品文档,就能轻松理解执行并能有很好的覆盖
B,是否有冗余
最后,可以提供一个用例管理思路

上图是一个代码分支管理的图例,没错,其实用例的版本管理可以像代码分支管理一样,不过没有那么复杂,他有几个原则
1,可以针对新功能设计用例,从而对新功能进行深度的测试,但是在系统测试前,用例需要合并到整体内容中并且优化为一份完整的系统用例
PS:如果仅针对新功能设计用例,他的比例不一定严格按照我们刚才说的比例,但合并完成的用例,一定遵循正常的用例级别的比例
2,可以有多个版本,hotfix版本、私有云版本,但一定会有当前最新系统的版本。
感谢大家能看到这里,把这么无聊的内容看完,到这里,黑盒测试也就差不多了吧,后续几篇文章,我们一起聊聊接口测试,当然网上的资料已经够多了,我并不会比其他人说的更多,说得更好,但也算是我这个系列继续往下走吧,这样回过头来,发现自己的体系很健全,读者也能在一个地方找到不同的东西,应该蛮不错的。
最后,给大家share一个我认为的测试覆盖的公式:测试覆盖 = 测试方法 + 测试数据 + 测试执行 + 测试范围
其中的测试执行,考虑到了人为的因素,所以他不一定等于我们圈定的测试范围。而测试范围,又随着阶段的推进、环境的变更会越来越少,这个时候则尤其担心修复引发的问题。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












