

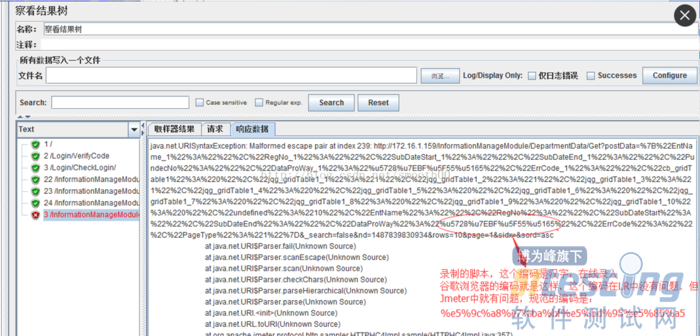
原因是本次系统页面用谷歌浏览器代理录制的脚本中(另外网上也提到IE和Firefox对于中文路径都是以UTF-8编码并带%号发送,IE和Firefox对于中文查询条件都是以GB2312编码发送,但是Firefox带%号,IE不带;而对于GET和POST发送的请求,编码是由页面编码决定的),发现汉字是Unicode编码而不是以基于UTF-8形式的URL编码呈现,但是由Jmeter发送的URL请求参数,必须是严格按照UTF-8的URL编码形式,否则就会引起不识别的错误。
解决办法有以下不同方式:
一、将汉字用URL编码工具替换成标准的URL编码格式
二、整个JSON内容不进行URL编码(保留未编码的标准汉字形式),并输入(如果抓包或录制的是已经被编码的串,可以通过网上的URL编码/解码工具进行解码,还原成初始状态)到Parameters值中,然后勾选编码选项(这样就交由jmeter来完成编码)
URL编码/解码可以用以下的在线工具
http://tool.chinaz.com/tools/urlencode.aspx
三、对于通过BODY发送的中文内容可以用Jmeter自带函数实现转码
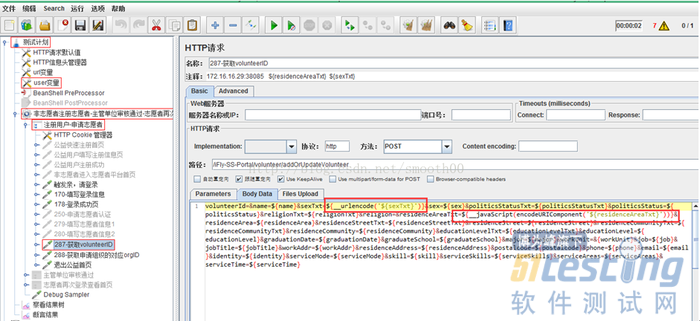
${__javaScript(encodeURIComponent('${token}'))}
${__urlencode('${token}'))}
我们借助这两个函数来实现,这样在变量或者csv参数文件中填写中文,然后在请求中调用这两个函数来实现编码,如图,这样就解决了URL编码问题
补充说明(如何在源端规范编码):
不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果。如果程序员要把每一种结果都考虑进去,是不是太恐怖了?有没有办法,能够保证客户端只用一种编码方法向服务器发出请求?
回答是有的,就是使用Javascript先对URL编码,然后再向服务器提交,不要给浏览器插手的机会。因为Javascript的输出总是一致 的,所以就保证了服务器得到的数据是格式统一的。
一、Javascript函数:escape()
Javascript语言用于编码的函数,一共有三个,最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了,但是由于历史原因, 很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果 是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。

它的具体规则是,除了ASCII字母、数字、标点符号“@ * _ + - . /”以外,对其他所有字符进行编码。在/u0000到/u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是 unescape()。
所以,“Hello World”的escape()编码就是“Hello%20World”。因为空格的Unicode值是20(十六进制)。

还有两个地方需要注意。
首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出, 默认都是Unicode字符。这一点对下面两个函数也适用。

其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处 理成空格。所以,使用的时候要小心。
二、Javascript函数:encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。

它对应的解码函数是decodeURI()。

需要注意的是,它不对单引号'编码。
三、Javascript函数:encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分 进行个别编码,而不用于对整个URL进行编码。
因此,“; / : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。

它对应的解码函数是decodeURIComponent()。
PS1 :
网页里的form编码其实不完全取决于网页编码,form标记中有一个accept-charset属性,在非ie浏览器种,如果将其赋值(比如 accept-charset="UTF-8"),则表单会按照这个值表示的编码方式进行提交。
在ie下,我的兼容解决办法是:
form1.onsubmit=function(){
document.charset=this.getAttribute('accept-charset');
}
四、中文编码转换样例
/** 中文字符串转UTF-8与GBK码示例 */ public static void tttt() throws Exception { String old = "手机银行"; //中文转换成UTF-8编码(16进制字符串) StringBuffer utf8Str = new StringBuffer(); byte[] utf8Decode = old.getBytes("utf-8"); for (byte b : utf8Decode) { utf8Str.append(Integer.toHexString(b & 0xFF)); } // utf8Str.toString()=====e6898be69cbae993b6e8a18c // System.out.println("UTF-8字符串e6898be69cbae993b6e8a18c转换成中文值======" + new String(utf8Decode, "utf-8"));//-------手机银行 //中文转换成GBK码(16进制字符串) StringBuffer gbkStr = new StringBuffer(); byte[] gbkDecode = old.getBytes("gbk"); for (byte b : gbkDecode) { gbkStr.append(Integer.toHexString(b & 0xFF)); } // gbkStr.toString()=====cad6bbfad2f8d0d0 // System.out.println("GBK字符串cad6bbfad2f8d0d0转换成中文值======" + new String(gbkDecode, "gbk"));//----------手机银行 //16进制字符串转换成中文 byte[] bb = HexString2Bytes(gbkStr.toString()); bb = HexString2Bytes("CAD6BBFAD2F8D0D0000000000000000000000000"); byte[] cc = hexToByte("CAD6BBFAD2F8D0D0000000000000000000000000", 20); String aa = new String(bb, "gbk"); System.out.println("aa====" + aa); } |
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












