

Hadoop的运行模式
单机模式是Hadoop的默认模式,在该模式下无需任何守护进程,所有程序都在单个JVM上运行,该模式主要用于开发和调试mapreduce的应用逻辑;
伪分布式模式下,Hadoop守护进程运行在一台机器上,模拟一个小规模的集群。该模式在单机模式的基础上增加了代码调试的功能,允许你检查NameNode,DataNode,Jobtracker,Tasktracker等模拟节点的运行情况;
单机模式和伪分布式模式均用于开发和调试的目的,真实Hadoop集群的运行采用的是完全分布式模式
单机模式安装步骤
一个干净的linux基础环境(重要,这个环境如果有问题后续就全是问题了)
为了方便大家我已经安装好了一个,大家只需下载导入到vm里即可使用。
关闭防火墙(适用于centos7,低版本不适用)
分别执行如下两条命令:
systemctl stop firewalld.service
systemctl disable firewalld.service
修改host name
vi /etc/hosts
然后把自己虚机的名字追加到两行的末尾,如果用的是我们提供的虚机,名字就是linux,追加之后的效果如图

重启网络:/etc/rc.d/init.d/network restart
设置无密码登录(用于hadoop启动)
cd ~ #进入当前用户的目录
mkdir -p /root/.ssh #我们用的root用户
cd ~/.ssh/
ssh-keygen -t rsa #如有提示,直接按回车cat id_rsa.pub >> authorized_keys # 加入授权
安装jdk1.8并配置环境变量
tar解压
cp解压后的包到/usr/lib/java/(如果没有java目录就创建一下)
vi /etc/profile,末尾添加如下内容:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_11
export JRE_HOME=/usr/lib/java/jdk1.8.0_11/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
执行source /etc/profile使得环境变量生效
验证是否成功,如下图

安装hadoop2.7.4
tar解压
cp解压后的包到/usr/lib/hadoop/(如果没有hadoop目录就创建一下)
设置hadoop-env.sh
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh
找到# The java implementation to use.这句话,在下面添加如下内容:
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/java/jdk1.8.0_11
export HADOOP_HOME=/usr/lib/hadoop/hadoop-2.7.4
export PATH=$PATH:/usr/lib/hadoop/hadoop-2.7.4/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
执行source /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh,使得环境变量生效
验证是否成功,如下图

配置相关的xml文件
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/core-site.xml(hadoop全局配置)
内容如下:
fs.defaultFS
hdfs://127.0.0.1:9000
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hdfs-site.xml(hdfs配置)
内容如下:
dfs.replication
1
cd /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml(MapReduce的配置)
内容如下:
mapreduce.framework.name
yarn
vi yarn-site.xml(yarn配置)
内容如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
格式化hdfs文件系统
初次运行hadoop时一定要有该操作,命令如下:
/usr/lib/hadoop/hadoop-2.7.4/bin/hadoop namenode -format
执行期间可能需要确认是否继续,如果有,就输入y回车即可
当你看到如下的内容时证明成功了

如果看到的是exiting with status 1,那么请运行如下命令,之后在进行hdfs的格式化
mkdir -pv /tmp/hadoop-root/dfs/name
启动hadoop(hdfs和yarn)
sh /usr/lib/hadoop/hadoop-2.7.4/sbin/start-all.sh
sh /usr/lib/hadoop/hadoop-2.7.4/sbin/stop-all.sh #停止
如果没有报错说明就成功了
使用jps命令查看进程,如果出现下面的内容就说明确定以及肯定成功啦
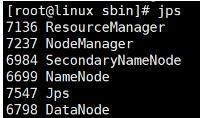
PS:如果修改了上面的xml文件需要重启服务哦
使用web查看Hadoop运行状态
http://你的服务器ip地址:50070/
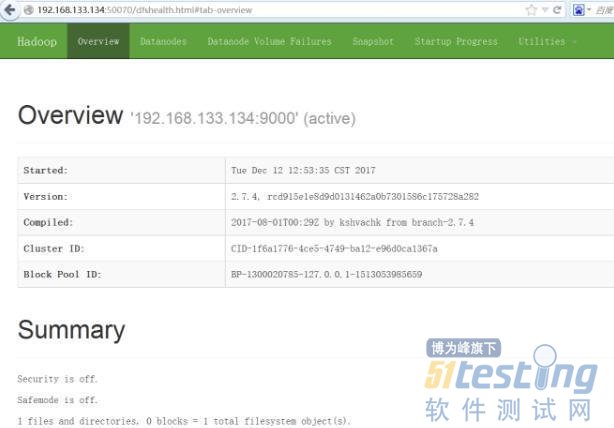
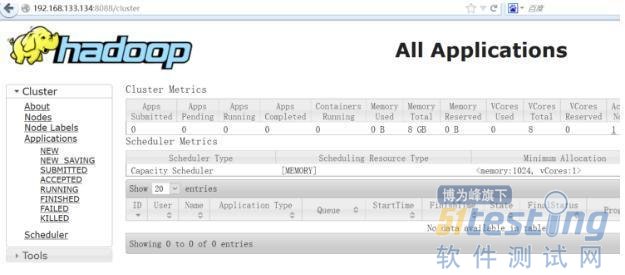
使用web查看集群状态
http://你的服务器IP地址:8088
可能会遇到的问题
如果你多次进行了hdfs的格式化操作,可能会无法启动datanode,原因是id不一致,一般的解决方法为将namenode clusterID和datanode clusterID改成一样的就行了。修改的文件为/tmp/hadoop-root/dfs/下的name or data文件下的VERSION里的内容。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












