

1. 概述
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
1.1 MapReduce的诞生背景
背景原因:
(1) 海量数据在单机上处理因为硬件资源限制,无法胜任;
(2) 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度;
(3) 引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发商,而将分布式计算中的复杂度交由框架来处理;
可见在程序由单机版扩成分布式时,会引入大量的复杂工作。为了提高开发效率,可以将分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。而mapreduce就是这样一个分布式程序的通用框架。
2. MAPREDUCE框架结构及核心运行机制
2.1 框架架构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster(Mapreduce application master):负责整个程序的过程调度及状态协调
2、MapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
2.2 MapReduce程序运行流程
(1) 一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的map task实例数量,然后向集群申请机器启动相应数量的map task进程;
(2) map task进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
a) 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对;
b) 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存;
c) 将缓存中的KV对按照K分区排序后不断溢写到磁盘文件;
(3) MRAppMaster监控到所有map task进程任务完成之后,会根据客户指定的参数启动相应数量的reduce task进程,并告知reduce task进程要处理的数据范围(数据分区);
(4) Reduce task进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台map task运行所在机器上获取到若干个map task输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储。
2.2.1 MapReduce的示例wordcount运行过程解析
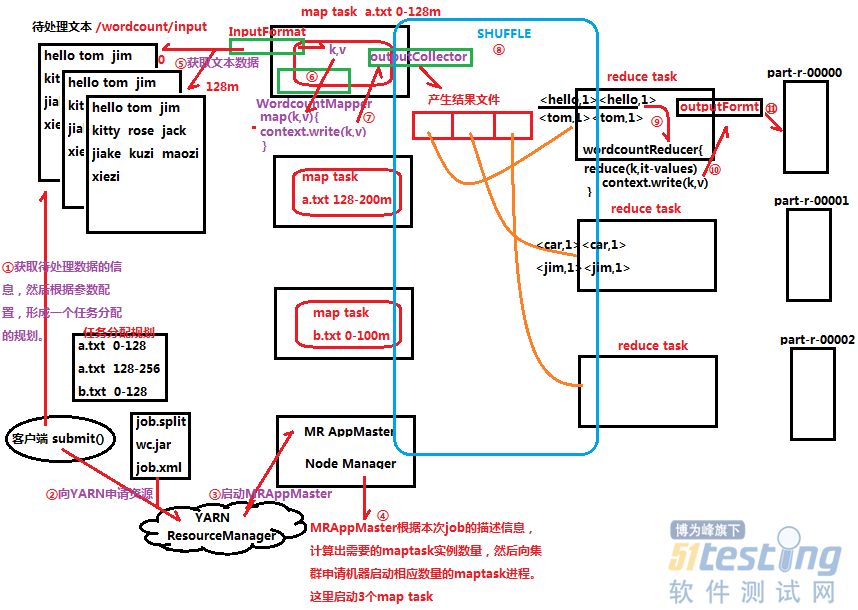
说明:
① client客户端获取待处理数据的信息(如多少个待处理的文件、待处理文件的大小),然后根据参数配置,形成一个任务分配的规划;
② client客户端向Yarn提交job.split、wc.jar和job.xml等相关文件,并申请资源;
③ Yarn首先启动Mr AppMaster;
④ MRAppMaster根据Yarn提供的本次job的描述信息,计算出需要的map task示例数量,然后向集群申请机器,启动相应的map task进程,这里启动3个map task;
⑤ map task根据任务分配规划分配的“a.txt 0-128”数据切片范围,通过InputFormat从中读取相应的数据,形成输入(K,V)键值对;
⑥ 再通过wordcountMapper的map()方法做逻辑运算处理输入(K,V)键值对;
⑦ 缓存map方法输出的(K,V)键值对到outputCollector;
⑧ map task输出的(K,V)键值对经过shuffle流程分区排序等操作,形成新的(K,V集合)键值对;
⑨ reduce task对(K,V集合)键值对进行逻辑处理;
⑩ reduce task输出(K,V)键值对到outputFormat;
outputFormat把传过来的(K,V)键值对输出到part-0000*等文本文件中;
3. 客户端向Yarn提交mr程序Job的流程
该流程即为“2.2.1 MapReduce的示例wordcount运行过程解析”中的第一、二步骤。
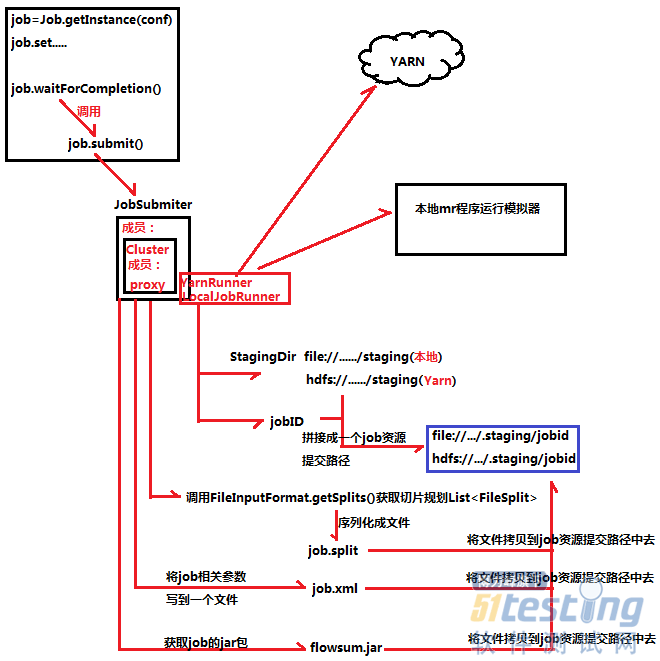
job.waitForCompletion()方法会调用job.submit方法,里面有JobSubmiter类,JobSubmiter类里面有Cluster类成员,Cluster类有个proxy代理成员,负责代理YarnRunner和代理LocalJobRunner。YarnRunner负责向Yarn提交job资源路径,而LocalJobRunner则是向本地提交job资源路径。YarnRunner和LocalJobRunner运行流程是一样,都是会产生StagingDir和JobID两个对象。JobSubmiter还会调用FileInputFormat.getSplits()方法获取切片规划List<FileSplit>并序列化生成job.split文件,根据客户端设置的job相关参数创建job.xml,最后还得获取job的jar包。StagingDir、JobID、job.spilt、job.xml和jar包共同拼接成一个job资源提交路径。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












