

Apache Airflow 是一个用于编排复杂计算工作流和数据处理流水线的开源工具。 如果您发现自己运行的是执行时间超长的 cron 脚本任务,或者是大数据的批处理任务,Airflow 可能是能帮助您解决目前困境的神器。本文将为那些想要寻找新的工具或者说不知道有这款工具的同学了解 Airflow 编写工作线提供入门教程。
Airflow 工作流设计称为有向非循环图(DAG)。这意味着,在编写工作流时,您应该考虑如何将你的任务划分为多个可独立执行的任务,然后,将这些任务合并为一个逻辑整体,将其组合成一个图,从而实现我们的工作流结果,例如:
图的形状决定了你工作流的整体逻辑。 Airflow DAG 可以包括多个分支,您可以决定在工作流执行时要走哪些分支或者说跳过哪一个分支。这就为我们的工作创建了一个非常有弹性的设计,因为如果发生错误,每个任务可以重试多次,甚至可以完全停止,并通过重新启动最后一个未完成的任务来恢复运行的工作流程。
在设计 Airflow 操作节点时,务必要记住,它们可能被执行不止一次。 每个任务应该是 幂等的,即具有多次应用的能力,而不会产生意想不到的后果。
Airflow 术语
以下是设计 Airflow 工作流程时使用的一些术语的简要概述:
1.Airflow DAGs 是很多 Tasks 的组合.
2.每个 Task 都被实现为一个 Operator
4.当一个任务执行的时候,实际上是创建了一个 Task 实例运行,它运行在 DagRun 的上下文中。
5.AIRFLOW_HOME 是 Airflow 寻找 DAG 和插件的基准目录。
环境准备
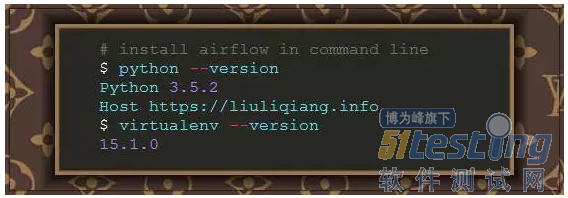
Airflow 是使用 Python 语言编写的,这让我们可以非常简单得在机器上安装。我这里使用的是 Python3.5 版本的 Python,还在使用 Python2 的兄弟们,赶紧出坑吧,3 会让你对 Python 更加痴迷的。虽然 Airflow 是支持 Python2 版本的,好像最低可以支持到 Python2.6,但是我墙裂推荐大家使用 Python3.接下来,我将使用 virtualenv 来管理开发环境,并且进行后续的一系列实验。
安装 Airflow
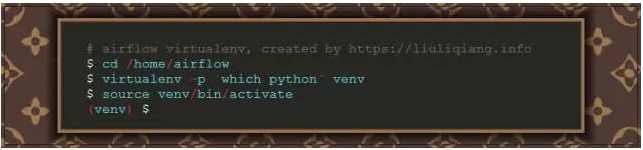
为了方便,我这里单独创建了一个 airflow 的用户用于实验,同时使用这个用户的 home 目录 /home/airflow 作为 airflow 的工作目录,如果你希望和我看到一样的效果,那么我希望是跟着我的步骤一起来:
这里只是进入 virtualenv 环境,接下来才是安装 airflow 的步骤,截止到我写博客的时候,airflow 的最新版本是 1.8,所以我这里就使用 1.8 的版本:
(venv) $ pip install airflow==1.8.0
经过一段稍长的等待时间之后,我们的 airflow 应该是安装成功了,在安装过程我们可以看到,airflow 依赖于大量的其他库,这个我们后续都会慢慢道来。现在是是否配置 airflow 的环境了。
第一个需要配置的就是 AIRFLOW_HOME 环境变量,这个是 airflow 工作的基础,后续的 DAG 和 Plugin 都将以此为基础展开,因为他们都是以 AIRFLOW_HOME 作为根目录进行查找。根据我们之前的描述,我们的 HOME 目录应该是 /home/airflow,所以可以这么设置:
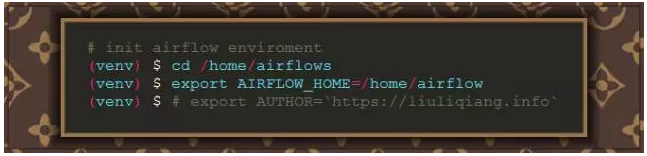
哈哈,到这里我们可以说一个最简单的配置就算是完成了,来看点有用的吧,尝试一下输入 airflow version 命令看看:
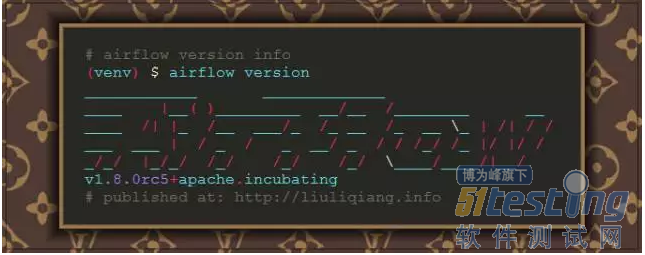
如果你看到了上面一般的输出,那么说明我们的 airflow 是安装和配置成功的,同时,我们使用 ls -al 命令看看,应该在 /home/airflow 目录上能够发现以下两个文件:
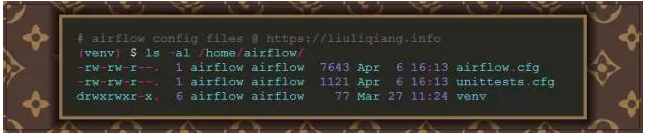
打开 airflow.cfg 文件你会发现里面有很多配置项,而且大部分都是有默认值的,这个文件就是 airflow 的配置文件,在以后的详解中我们会接触到很多需要修改的配置,目前就以默认的配置来进行试验。如果你现在就迫不及待得想自己修改着玩玩,那么 Airflow Configure 这篇文档可以帮助你了解各个配置项的含义。
初始化 Airflow 数据库
可能你会有点震惊了,为啥要初始化数据库?是的,因为 airflow 需要维护 DAG 内部的状态,需要保存任务执行的历史信息,这些都是放在数据库里面的,也就是说我们需要先在数据库中创建表,但是,因为使用的是 Python,我们不需要自己使用原始的 SQL 来创建,airflow 为我们提供了方便的命令行,只需要简单得执行:
(venv) $ airflow initdb
这里值得注意的是,默认的配置使用的是 SQLite,所以初始化知道会在本地出现一个 airflow.db 的数据库文件,如果你想要使用其他数据库(例如 MySQL),都是可以的,只需要修改一下配置,我们后续会讲到:
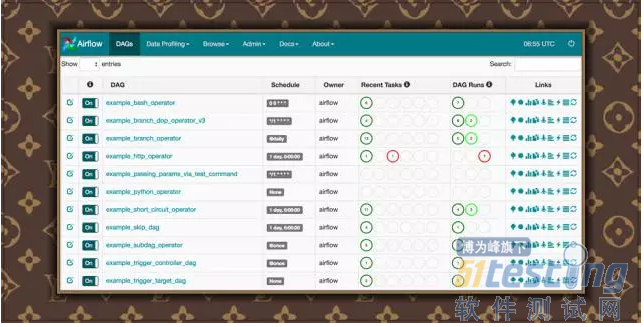
Airflow Web 界面
Airflow 提供了多种交互方式,主要使用到的有两种,分别是:命令行 和 Web UI。Airflow 的 Web UI 是通过 Flask 编写的,要启动起来也是很简单,直接在 AIRFLOW_HOME 目录运行这条命令:
(venv) $ airflow webserver
然后你就可以通过浏览器看到效果了,默认的访问端口是:8080,所以打开浏览器,访问以下 URL:http://localhost:8080/admin,神奇的事情就这么发生了,你将看到类似这样的页面:
第一个 DAG
从一开始就说了, Airflow 的两个重大功能就是 DAG 和 Plugin,但是直到现在我们才开始讲解 DAG。DAG 是离散数学中的一个概念,全称我们称之为:有向非循环图(directed acyclic graphs)。图的概念是由节点组成的,有向的意思就是说节点之间是有方向的,转成工业术语我们可以说节点之间有依赖关系;非循环的意思就是说节点直接的依赖关系只能是单向的,不能出现 A 依赖于 B,B 依赖于 C,然后 C 又反过来依赖于 A 这样的循环依赖关系。
那么在 Airflow 中,图的每个节点都是一个任务,可以是一条命令行(BashOperator),可以是一段 Python 脚本(PythonOperator)等等,然后这些节点根据依赖关系构成了一条流程,一个图,称为一个 DAG,每个 Dag 都是唯一的 DagId。
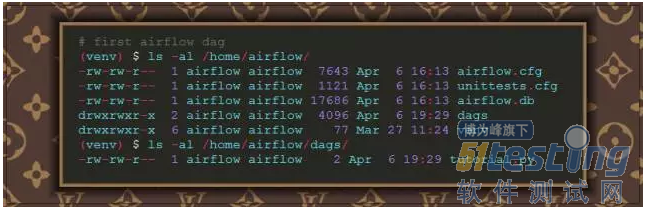
创建一个 DAG 也是很简单得,首先需要在 AIRFLOW_HOME 目录下创建一个 dags 目录,airflow 将会在这个目录下去查找 DAG,所以,这里我们先创建一个,创建完之后新建一个 tutorial.py 文件:

然后,再来看下我们的 DAG 文件是怎么写的:
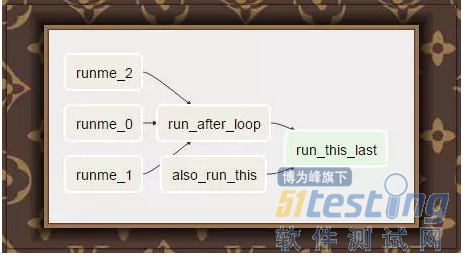
我们可以从 Web UI 上看到这个 DAG 的依赖情况:
这就定义了几个任务节点,然后组成了一个 DAG,同时也可以发现,依赖关系是通过 set_downstream 来实现的,这只是一种方式,在后面我们将会看到一个更加简便的方式。
让 DAG 跑起来
为了让 DAG 能够运行,我们需要触发 DAG 任务,这里有几种触发的方式,但是,最天然的当属定时器了,例如,在我们上面的任务中,可以发现设置了一个参数: schedule_interval,也就是任务触发的周期。但是,你光设置了周期是没有用的,我们还需要有个调度器让他调度起来,所以需要运行调度器:
我这里使用的是 LocalExecutor, Airflow 目前有三种执行器,分别是:
1.SequentialExecutor:顺序得指定 DAG
2.LocalExecutor:使用本地进程执行 DAG
3.CeleryExecutor:使用 Celery 执行 DAG
其中第一种 SequentialExecutor 可以用来在开发调试阶段使用,千万不要在生成环境中使用。第二种和第三种可以用于生产也可以用于开发测试,但是,对于任务较多的,推荐使用第三种: CeleryExecutor。
总结
本文从 Airflow 的环境安装出发,简单得介绍了一下如何使用 Airflow,但是本文的定位始终是一篇入门文章,对于 Airflow 的高级特性,在本博客中将会有大量的后续文章进行介绍,请大家自行搜索了解。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












