

persist支持的RDD持久化级别如下:

需要注意的问题: Cache或shuffle场景序列化时, spark序列化不支持protobuf message,需要java 可以serializable的对象。一旦在序列化用到不支持java serializable的对象就会出现上述错误。 Spark只要写磁盘,就会用到序列化。除了shuffle阶段和persist会序列化,其他时候RDD处理都在内存中,不会用到序列化。
Spark Streaming运行原理
spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理。
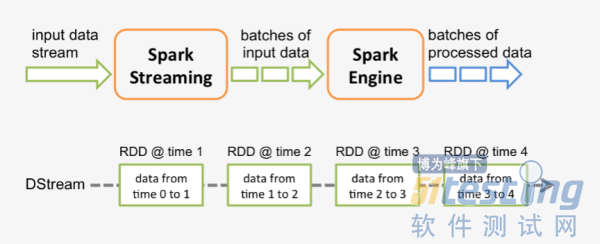
从原理上看,把传统的spark批处理程序变成streaming程序,spark需要构建什么?

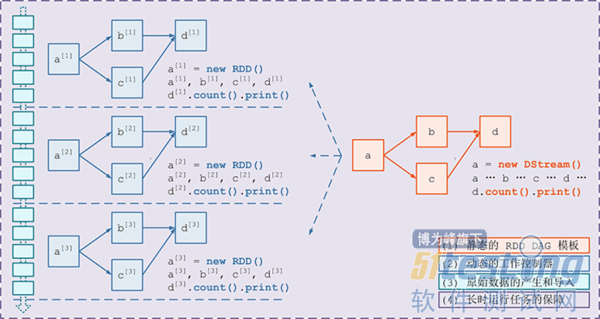
需要构建4个东西:
一个静态的 RDD DAG 的模板,来表示处理逻辑;
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD 3. DAG 的实例,对数据片段进行处理;
Receiver进行原始数据的产生和导入;Receiver将接收到的数据合并为数据块并存到内存或硬盘中,供后续batch RDD进行消费
对长时运行任务的保障,包括输入数据的失效后的重构,处理任务的失败后的重调。
具体streaming的详细原理可以参考广点通出品的源码解析文章:
https://github.com/lw-lin/CoolplaySpark/blob/master/Spark%20Streaming%20%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E7%B3%BB%E5%88%97/0.1%20Spark%20Streaming%20%E5%AE%9E%E7%8E%B0%E6%80%9D%E8%B7%AF%E4%B8%8E%E6%A8%A1%E5%9D%97%E6%A6%82%E8%BF%B0.md#24
对于spark streaming需要注意以下三点:
尽量保证每个work节点中的数据不要落盘,以提升执行效率。
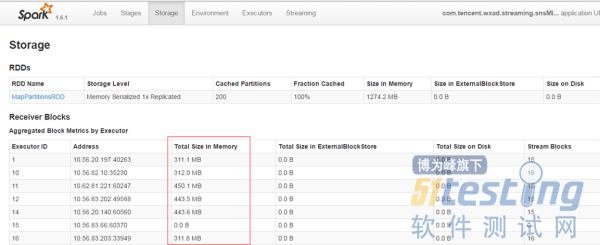
保证每个batch的数据能够在batch interval时间内处理完毕,以免造成数据堆积。
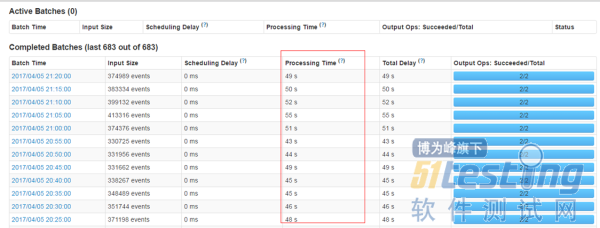
使用steven提供的框架进行数据接收时的预处理,减少不必要数据的存储和传输。从tdbank中接收后转储前进行过滤,而不是在task具体处理时才进行过滤。

Spark 资源调优
内存管理:
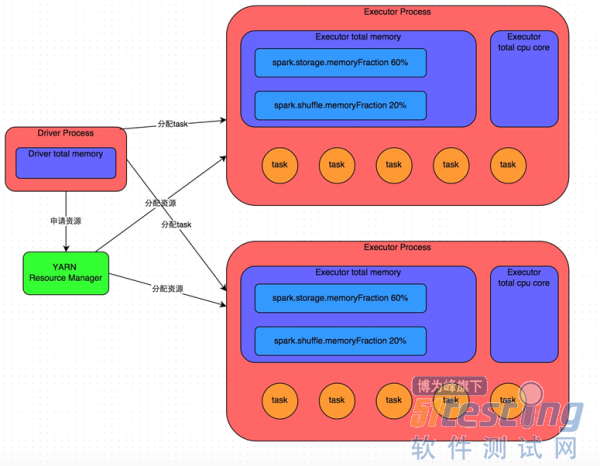
Executor的内存主要分为三块:
第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
每个task以及每个executor占用的内存需要分析一下。每个task处理一个partiiton的数据,分片太少,会造成内存不够。

Spark 环境搭建
spark tdw以及tdbank api文档:
http://git.code.oa.com/tdw/tdw-spark-common/wikis/api












