

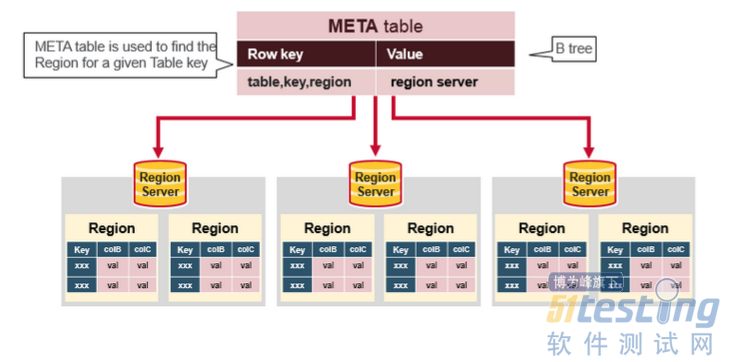
HBase Meta Table
1.META表是一个保存的了系统中所有region列表的HBase表。
2.META表就像一颗B—tree
3.METa的结构如下:
Key: region start key,region id
Values: RegionServer
Region Server Components
Region Server运行在HDFS的DataNode,并且具备以下组件:
1.WAL:预写日志是分布式文件系统上的文件。WAL用于存储尚未被永久保存的新数据,用于故障情况下的恢复。
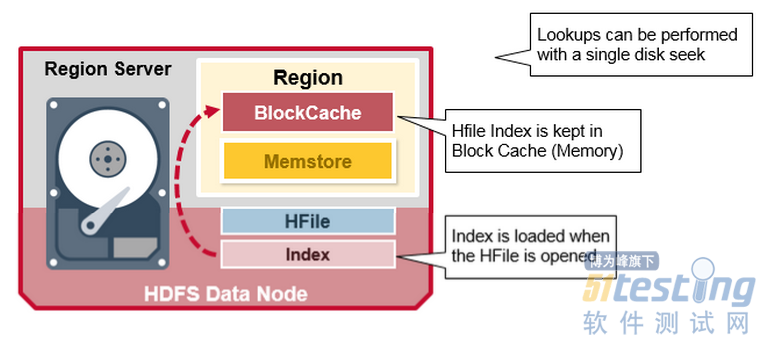
2.BlockCache: 是读取缓存。在内存中存储频繁读取的数据,近期最少使用的数据在满时被删除。
3.MemStore:是写入缓存。存储尚未写入磁盘的数据。在写入磁盘之前进行排序,每个region的每个column family有一个MemStore。
4.在磁盘上,Hfiles将行存储为已排序的KeyValues。

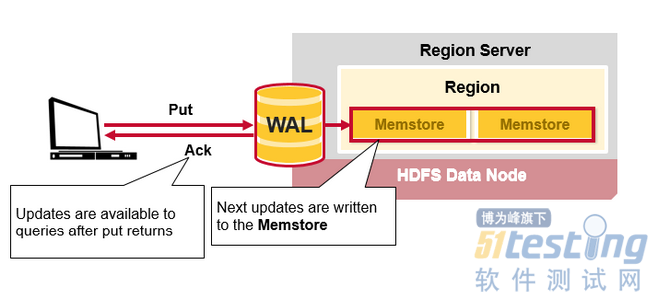
HBase Write Steps (1)
当客户端发起Put请求时,第一步是将数据写入于写日志,WAL:
1.发布的内容将被添加到存储在磁盘上的WAL文件末尾。
2.WAL用于在服务器崩溃的情况下恢复尚未保存的数据。

HBase Write Steps (2)
一旦数据写入WAL,将会被写入MemStore中,然后放入Put请求确认信息返回给客户端。
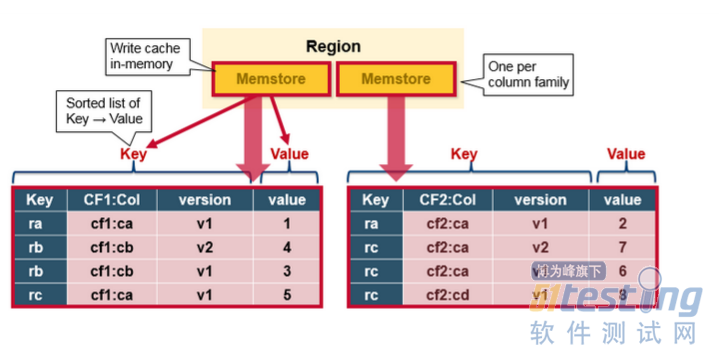
HBase MemStore
MemStore 将更新的内容排序并以KeyValues的形式存储到内存中,与将其存储在HFile中相同。每个列族只有一个MenStorre,更新内容按照列族排序。
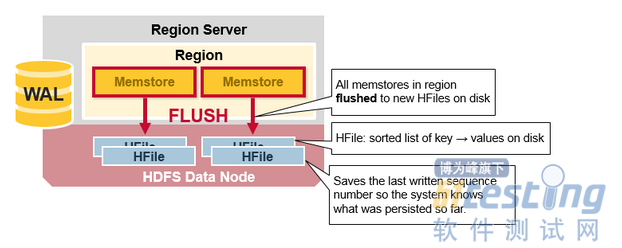
HBase Region Flush
当MemStrore积聚了足够的数据,整个有序集合被写入到HDFS的HFile中。HBase每个列族使用多个HFile,其中包含真正的Cell或者KeyValue实例。随着时间的推移,在MenStore中跟据KeyValue排序,最终刷新到磁盘HFile文件中。
注意这也是HBase为什么限制列族数量的一个原因。每个列族只有一个MemStore;当一个MemStore数据满了,会刷新到磁盘文件中。它还保存了最近写入的序列号,以便让系统知道到目前为止持久化的情况。
高位序列号作为元字段存储在每个HFile中,以反映持久化结束位置以及继续执行的位置。在region启动时,序列号被读取后,然后最高位做为新编辑内容的序列号。
HBase HFile
数据存储在HFile中,其中包含排序的Key/Value。当MemStore累积足够的数据时,整个已排序的KeyValue集将被写入HDFS中的新HFile。这是一个顺序写入。它速度非常快,因为它避免了移动磁盘驱动器磁头。
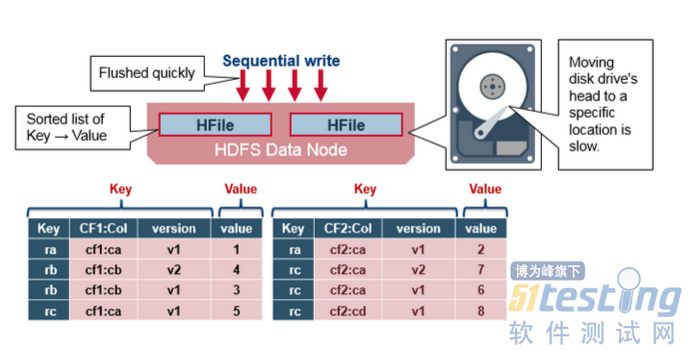
HBase HFile Structure
HBase包含一个多层索引,是HBase不必读取整个文件的情况下查找定位数据。多级索引就像一颗b+tree:
1.键值对按照升序存储
2.索引通过RowKey指向内容为key/value的64kb大小的block中。
3.每个block都有自己叶子索引
4.每个block的最后的key放进intermediate index(中间索引)
5.根索引指向中间索引
trailer指向元数据块,它写在文件中持久化数据的末尾。trailer也包含布隆过滤器和时间范围信息。布隆过滤器有助于跳过不包含某个row key的文件。如果时间范围信息不在读取的时间范围内,则时间范围信息对于跳过该文件非常有用。
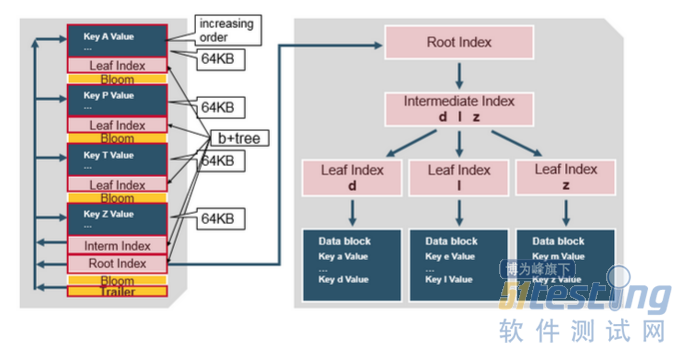
HFile Index
我们刚才讨论的索引是在HFile打开并保存在内存中时加载的。这允许查找通过单个磁盘寻道来执行。
HBase Read Merge
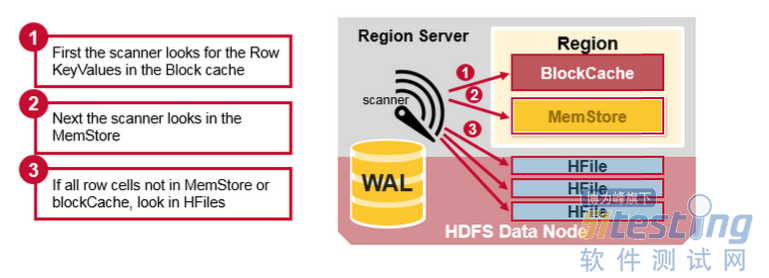
我们已经看到,row对应的KeyValue cell可以在多个位置,row cell已经持久化到Hfile中,最近更新的cell在MemStore中,最近读取的cell在Block Cache中。因此,当读取一行数据时,系统是如何获得相应的cell并返回的?读取操作按照以下步骤从BlockCache,MemStore和HFile合并关键值:
首先,扫描器在BlockCache(读取缓存)中,查找Row Cells。最近读取的Key Values被缓存在这里,并且当需要内存时,最近最少使用的被清除。
其次,扫描器在MemStore中查找,内存写入缓存包含最近的写入。
如果扫描器在MenStore和BlockCache中没有找到Row cells,然后HBase使用BLock Cache的HFile索引和布隆过滤器把可能存在目标Row cells的HFile加载到内存中。
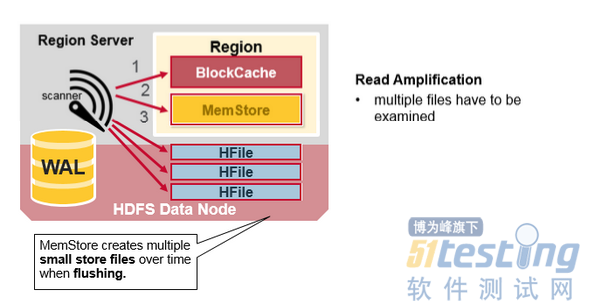
HBase Read Merge
正如前面所讨论的,每个MemStore可能有许多HFile,这意味着读取时可能需要检查多个HFile文件,这可能会影响性能。这被称为读取放大。
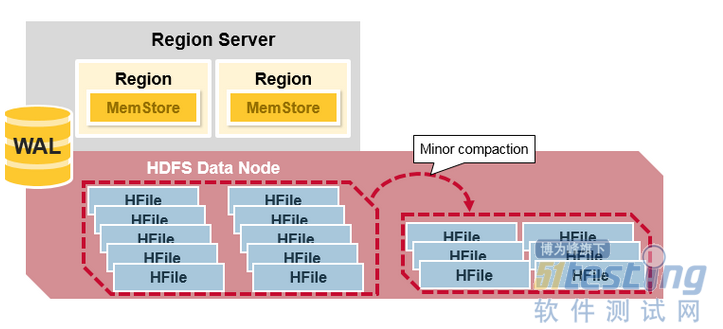
HBase Minor Compaction
HBase会自动选择一些较小的HFile,并将它们重写成更少且更大的Hfiles。这个过程称为Minor Compaction。Minor Compaction通过将较小的文件重写为较少但较大的文件来减少存储文件的数量,执行合并排序。
HBase Major Compaction
Major compaction将region所有的HFile合并并重写到一个HFile中,每个列族对应这样的一个HFile。并在此过程中,删除已删除或过期的Cell。这样提升了读取性能,由于Major compaction重写了所有HFile文件,因此在此过程中可能会发生大量磁盘I/O和网络流量。这被称为写入放大。
Major compaction执行计划可以自动运行。由于写入放大,通常计划在周末或晚上进行Major compaction。由于服务器故障或负载平衡,Major compaction还会使任何远程数据文件成为本地服务器的本地数据文件。
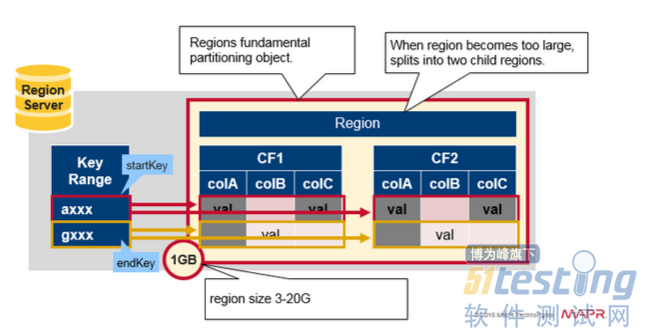
Region = Contiguous Keys
快速回顾一下region:
表格可以水平划分为一个或者多个region。早start key和end key之间包含连续的,排序的行范围。
每个region小为1GB(默认)
表的region通过RegionServer为客户端提供服务。
RegionServer可以提供大约1,000个region(可能属于同一个表或不同的表)
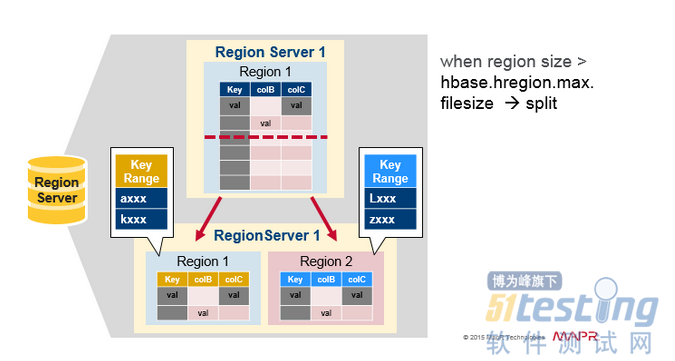
Region Split
最初每个表格有一个区域。当一个region变得太大时,它会分裂成两个子region。代表原region的一半的两个子region,在相同的RegionServer上并行打开,然后将分区报告给HMaster。由于负载平衡的原因,HMaster可以安排将新region移动到其他服务器。
Read Load Balancing
分裂最初发生在同一个RegionServer上,由于负载平衡的原因,HMaster可以安排将新region移动到其他服务器。这导致新RegionServer提供服务的数据来自远程HDFS节点,直到Major compaction将数据文件移动到RegionServer的本地节点。HBase数据在写入时是本地数据,但当某个区域被移动时(为了负载平衡或恢复),在Major compaction之前它不是本地数据。
HDFS Data Replication
所有的写入和读取都来自主节点。HDFS复制WAL和HFile块。HFile块复制自动发生。HBase依靠HDFS在存储文件时提供的数据安全性。在HDFS中写入数据时,本地写入一个副本,然后将其复制到第二个节点,并将第三个副本写入第三个节点。
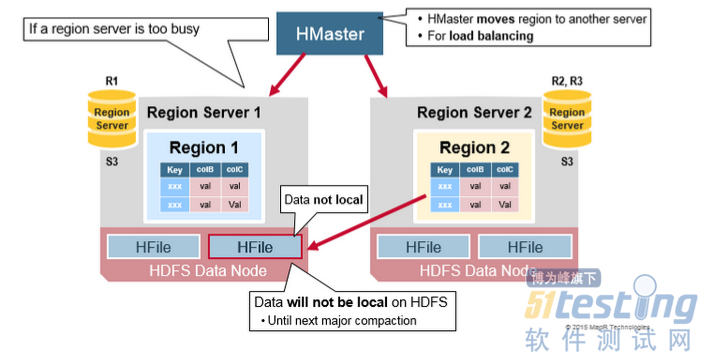
HDFS Data Replication (2)
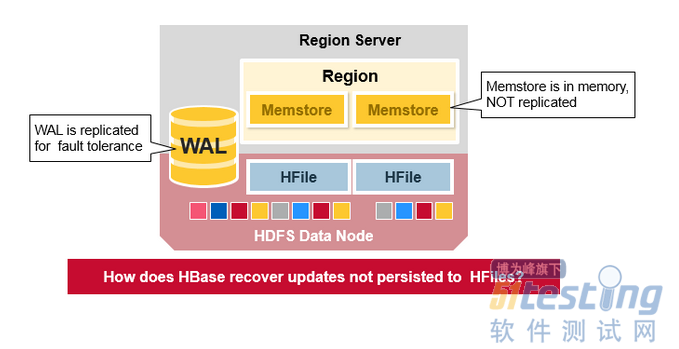
WAL文件和HFiles文件被持久化到磁盘并复制,那么HBase如何恢复没有报持久化到HFile的MemStore更新呢?请参阅下一节寻找答案。
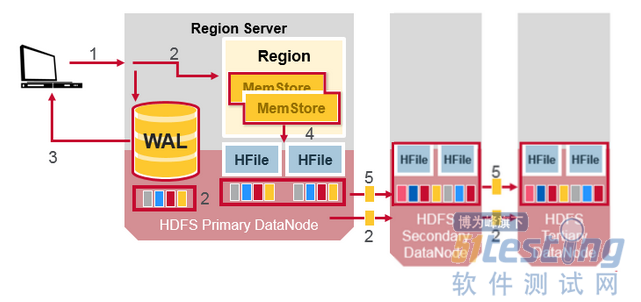
HBase Crash Recovery
当RegionServer失败时,崩溃的region将不可用,直到检测和恢复步骤发生。 Zookeeper会在失去与RegionServer心跳信号时确定节点故障。 HMaster将会被通知Region Server失败。HMaster将会被通知Region Server失败。
当HMaster确定RegionServer宕机时,HMaster重新分配宕机服务器的Region到活动的服务器。为了恢复宕机服务器未刷新到磁盘的memstore数据,HMaster将属于宕机RegionServer的WAL拆分成单独的文件并将这些文件存储在新RegionServer的数据节点中。每个Region Server然后进行重播WAL,从相应的WAL拆分文件,为region重建MemStore。
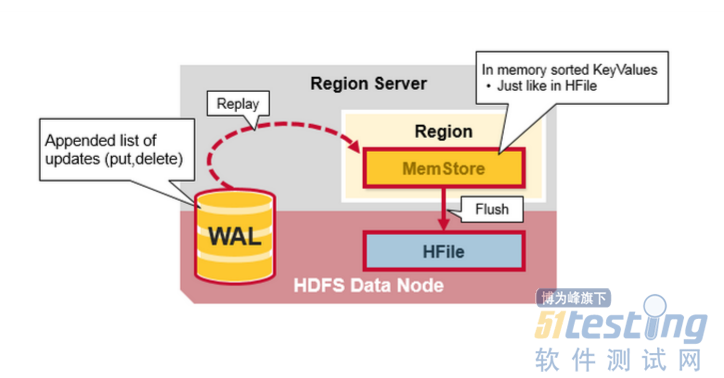
WAL的文件包含编辑列表,其中一个编辑表示单个放置或删除。一个编辑表示一个放置或删除。编辑按时间顺序编写,因此,对于持久化,添加内容将附加到存储在磁盘上的WAL文件的末尾。
如果数据仍在内存中并且未保存到HFile时发生故障会发生什么?WAL重播,重播WAL的过程是通过读取WAL,添加或者排序已知的编辑到当前MemStore。最后,Memtore将变化刷新到HFile。
Data Recovery

Apache HBase Architecture Benefits
HBase 优点:
1.强一致性模型
当写入返回时,所有读者将看到相同的值
2.自动扩展
数据增长过大时分割region
使用HDFS传播和复制数据
3.内置恢复机制
使用预写日志 (与文件系统上的日记类似)
4.集成Hadoop
MHBase上的MapReduce很简单
Apache HBase Has Problems Too…
Business continuity reliability:
1.WAL 重播缓慢
2.意外恢复缓慢
3.Major Compaction I/O 风暴











