

ЎЎЎЎchrome.proxy КЗУГУЪ№ЬАн Chrome дЇААЖчµДґъАн·юОсЖчЙиЦГµД APIЈ¬ЙПГжµДґъВлНЁ№эЖдМṩµД·Ѕ·Ё chrome.proxy.settings.set() ЙиЦГБЛТ»ёцґъАн·юОсЖчµШЦ·Ј¬mode µДЦµОЄ fixed_servers ±нКѕёщѕЭПВГжµД rules АґЦё¶ЁДіёц№М¶ЁµДґъАн·юОсЖчЈ¬ґъАнАаРНїЙТФКЗ HTTP »т HTTPSЈ¬»№їЙТФКЗ SOCKS ґъАнЎЈmode µДЦµ»№їЙТФКЗ directЈЁОЮРиґъАнЈ©Ј¬auto_detectЈЁНЁ№э WPAD РТйЧФ¶ЇјмІвґъАнЈ©Ј¬pac_scriptЈЁНЁ№э PAC ЅЕ±ѕ¶ЇМ¬СЎИЎґъАнЈ©єН systemЈЁК№УГПµНіґъАнЈ©ЎЈ№ШУЪХвёц API µДПкПёЛµГчїЙТФІОїґ Chrome µД №Щ·ЅОДµµЈ¬ХвАпУРТ»·Э ЦРОД·ТлЎЈ
ЎЎЎЎНЁ№эЙПГжµДґъВлТІЦ»КЗЙиЦГБЛґъАн·юОсЖчµД IP µШЦ·єН¶ЛїЪ¶шТСЈ¬УГ»§ГыєНГЬВл»№Г»УРЙиЦГЈ¬ХвєНК№УГГьБоРРІОКэГ»КІГґЗш±рЎЈЛщТФ»№РиТЄПВГжµДµЪ¶юРРґъВлЈє
chrome.webRequest.onAuthRequired.addListener( function (details) { return { authCredentials: { username: "username", password: "password" } }; }, { urls: ["<all_urls>"] }, [ 'blocking' ] ); |
ЎЎЎЎОТГЗПИїґїґПВГжХвХЕНјЈ¬БЛЅвПВ Chrome дЇААЖчЅУКЬНшВзЗлЗуµДХыёцБчіМЈ¬Т»ёціЙ№¦µДЗлЗу»бѕАъТ»ПµБРµДКВјюЈЁНјЖ¬АґФґЈ©Јє
ЎЎЎЎ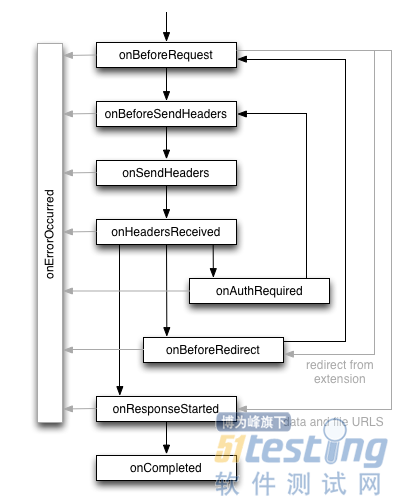
ЎЎЎЎХвР©КВјю¶јКЗУЙ chrome.webRequest API МṩЈ¬ЖдЦРµД onAuthRequired ЧоЦµµГОТГЗЧўТвЈ¬ЛьКЗУГУЪґъАнЙн·ЭИПЦ¤µД№ШјьЎЈЛщУРµДКВјю¶јїЙТФНЁ№э addListener ·Ѕ·ЁЧўІбТ»ёц»ШµчєЇКэЧчОЄјаМэЖчЈ¬µ±ЗлЗуРиТЄЙн·ЭИПЦ¤К±Ј¬»ШµчєЇКэ·µ»ШґъАнµДУГ»§ГыєНГЬВлЎЈіэБЛ»Шµч·Ѕ·ЁЈ¬addListener µЪ¶юёцІОКэУГУЪЦё¶ЁёГґъАнККУГУЪДДР© urlЈ¬ХвАпµД <all_urls> КЗ№М¶ЁµДМШКвУп·ЁЈ¬±нКѕЛщУРµД urlЈ¬µЪИэёцІОКэЧЦ·ыґ® blocking ±нКѕЗлЗуЅ«±»ЧиИыЈ¬»ШµчєЇКэЅ«ТФН¬ІЅµД·ЅКЅЦґРРЎЈХвёц API ТІїЙТФІОїј Chrome µД №Щ·ЅОДµµЈ¬ХвАпКЗ ЦРОД·ТлЎЈ
ЎЎЎЎЧЫЙПЈ¬ОТГЗѕНїЙТФРґТ»ёцјтµҐµДґъАнІејюБЛЈ¬ЙхЦБЅ«ІејюЧціЙ¶ЇМ¬ЙъіЙµДЈ¬И»єу Selenium ¶ЇМ¬µДјУФШЙъіЙµДІејюЎЈНкХыµДФґВлФЪ ХвАпЎЈ
ЎЎЎЎИэЎўSelenium ИзєО№эВЛ·З±ШТЄЗлЗуЈї
ЎЎЎЎSelenium ЕдєПґъАнЈ¬ДгµДЕАіжјёєхТСѕОЮЛщІ»ДЬБЛЎЈЙПГжЛµ№эЈ¬Selenium ЕАіжЛдИ»єГУГЈ¬µ«УРёцЧоґуµДМШµгКЗВэЈ¬УРК±єтМ«ВэБЛТІІ»КЗ°м·ЁЎЈУЙУЪГїґОґтїЄТ»ёцТіГж Selenium ¶јТЄµИґэТіГжјУФШНкіЙЈ¬°ьАЁТіГжЙПµДНјЖ¬ЧКФґЈ¬JS єН CSS ОДјюµДјУФШЈ¬¶шЗТёьН·МЫµДКЗЈ¬Из№ыТіГжЙПУРТ»Р©ЗЅНвЧКФґЈ¬±ИИзАґЧФ Google »т Facebook µИХѕµгµДБґЅУЈ¬Из№ыІ»К№УГѕіНвґъАнЈ¬дЇААЖчТЄТ»Ц±µИµЅХвР©ЧКФґБ¬ЅУі¬К±ІЕЛгТіГжјУФШНкіЙЈ¬¶шХвР©ЧКФґ¶ФОТГЗµДЕАіжГ»УРИОєОУГґ¦ЎЈ
ЎЎЎЎОТГЗДЬІ»ДЬИГ Selenium №эВЛµфДЗР©ОТГЗІ»РиТЄµДЗлЗуДШЈї
ЎЎЎЎYi Zeng ФЪЛыµДТ»ЖЄІ©їН Exclude Selenium WebDriver traffic from Google Analytics ЙПЧЬЅбБЛєЬ¶аЦЦ·Ѕ·ЁАґ№эВЛ Google Analytics µДЗлЗуЈ¬ЛдИ»ЛыµДІ©їНКЗЧЁГЕХл¶Ф Google Analytics µДЗлЗ󣬵«ЖдЦРУРєЬ¶аЛјВ·»№КЗєЬЦµµГОТГЗЅијшµДЎЈЖдЦРУРПВГжµДјёЦЦЅвѕц·Ѕ°ёЈє
ЎЎЎЎНЁ№эРЮёД hosts ОДјюЈ¬Ѕ« google.comЎўfacebook.com µИЦШ¶ЁПтµЅ±ѕµШЈ¬ХвЦЦ·Ѕ·ЁРиТЄРЮёДПµНіОДјюЈ¬І»·Ѕ±гіМРтµДІїК𣬶шЗТІ»ДЬ¶ЇМ¬µДМнјУТЄ№эВЛµДЗлЗуЈ»
ЎЎЎЎЅыУГдЇААЖчµД JavaScript №¦ДЬЈ¬Ж©Из Chrome Ц§іЦІОКэ --disable-javascript АґЅыУГ JavaScriptЈ¬µ«ХвЦЦ·Ѕ·ЁУРєЬґуµДѕЦПЮРФЈ¬НјЖ¬єН CSS ЧКФґ»№КЗГ»УР№эВЛµфЈ¬¶шЗТТіГжЙПЙЩБЛ JavaScriptЈ¬їЙДЬХѕµгµДєЬ¶а№¦ДЬОЮ·ЁК№УГБЛЈ»
ЎЎЎЎК№УГдЇААЖчІејюЈ¬Yi Zeng µДІ©їНЦРЦ»МбµЅБЛ Google-Analytics-Opt-out-Add-on ІејюУГУЪЅыУГ Google AnalyticsЈ¬КµјКЙПОТГЗєЬИЭТЧПлµЅ AdBlock ІејюЈ¬ХвёцІејюУГАґ№эВЛТіГжЙПµДТ»Р©№гёжЈ¬ХвєНОТГЗПлТЄµДР§№ыУРР©АаЛЖЎЈОТГЗїЙТФЧФјєРґТ»ёцІејюЈ¬А№ЅШІ»РиТЄµДЗлЗуЈ¬ПаРЕНЁ№эЙПТ»ЅЪµДЅйЙЬЈ¬ТІїЙТФЧціцАґЎЈ
ЎЎЎЎК№УГґъАн·юОсЖч BrowserMob ProxyЈ¬НЁ№эґъАн·юОсЖчАґА№ЅШІ»РиТЄµДЗлЗуЈ¬іэБЛ BrowserMob ProxyЈ¬»№УРєЬ¶аґъАнИнјюТІѕЯУРА№ЅШЗлЗуµД№¦ДЬЈ¬Ж©Из Fiddler µД AutoResponder »тХЯ НЁ№э whistle ЙиЦГ Rules ¶јїЙТФА№ЅШ»тРЮёДЗлЗуЈ»
ЎЎЎЎХвАпЛдИ»·Ѕ·ЁУРєЬ¶аЈ¬µ«ОТЦ»НЖјцЧоєуТ»ЦЦЈєК№УГґъАн·юОсЖч BrowserMob ProxyЈ¬BrowserMob Proxy јтіЖ BMPЈ¬їЙТФХвГґЛµЈ¬BMP ѕш¶ФКЗОЄ Selenium ОЄЙъµДЈ¬Selenium + BMP µДНкГАґоЕдЈ¬їЙТФКµПЦєЬ¶аДгѕш¶ФПлПуІ»іцАґµД№¦ДЬЎЈ
ЎЎЎЎОТЦ®ЛщТФНЖјц BMPЈ¬КЗУЙУЪ BMP µДАнДо·ЗіЈЗЙГоЈ¬єНґ«НіµДґъАн·юОсЖчІ»Т»СщЈ¬ЛьІўІ»КЗТ»ёцјтµҐµДґъАнЈ¬¶шКЗТ»ёц RESTful µДґъАн·юОсЈ¬НЁ№э BMP МṩµДТ»МЧ RESTful ЅУїЪЈ¬ДгїЙТФґґЅЁ»тТЖіэґъАнЈ¬ЙиЦГєЪГыµҐ»т°ЧГыµҐЈ¬ЙиЦГ№эВЛЖч№жФтµИµИЈ¬їЙТФЛµЛьКЗТ»ёцїЙ±аіМКЅµДґъАн·юОсЖчЎЈBMP КЗК№УГ Java УпСФ±аРґµДЈ¬ЛьЗ°єуѕАъБЛБЅёцґу°ж±ѕµДµьґъЈ¬ЖдєЛРДТІКЗґУЧоіхµД Jetty СЭ±дОЄ LittleProxyЈ¬К№µГЛьёьРЎЗЙєНОИ¶ЁЈ¬ДгїЙТФґУ ХвАпПВФШ BMP µДїЙЦґРРОДјюЈ¬ФЪ Windows ПµНіЙПЈ¬ОТГЗЦ±ЅУЛ«»чЦґРР bin ДїВјПВµД browsermob-proxy.bat ОДјюЎЈ
ЎЎЎЎBMP Жф¶ЇєуЈ¬Д¬ИПФЪ 8080 ¶ЛїЪґґЅЁґъАн·юОсЈ¬ґЛК± BMP »№І»КЗТ»ёцґъАн·юОсЖчЈ¬РиТЄДгПИґґЅЁТ»ёцґъАнЈє
ЎЎЎЎcurl -X POST http://localhost:8080/proxy
ЎЎЎЎПт /proxy ЅУїЪ·ўЛН POST ЗлЗуЈ¬їЙТФґґЅЁТ»ёцґъАн·юОсЖчЎЈґЛК±Ј¬ОТГЗФЪдЇААЖч·ГОК http://localhost:8080/proxy ХвёцµШЦ·Ј¬їЙТФїґµЅОТГЗТСѕУРБЛТ»ёцґъАн·юОсЖчЈ¬¶ЛїЪєЕОЄ 8081Ј¬ПЦФЪОТГЗѕНїЙТФК№УГ 127.0.0.1:8081 ХвёцґъАнБЛЎЈ
ЎЎЎЎЅУПВАґОТГЗТЄ°С Google µДЗлЗуА№ЅШµфЈ¬BMP МṩБЛТ»ёц /proxy/[port]/blacklist ЅУїЪїЙТФК№УГЈ¬ИзПВЈє
ЎЎЎЎcurl -X PUT -d 'regex=.*google.*&status=404' http://localhost:8080/proxy/8081/blacklist
ЎЎЎЎХвСщЛщУРЖҐЕдµЅ .*google.* ХэФтµД urlЈ¬¶јЅ«Ц±ЅУ·µ»Ш 404 Not FoundЎЈ
ЎЎЎЎЦЄµАБЛ BMP ФхГґУГЈ¬ФЩЅУПВАґЈ¬ѕНКЗ±аРґґъВлБЛЎЈµ±И»ОТГЗїЙТФЧФјєРґґъВлАґµчУГ BMP МṩµД RESTful ЅУїЪЈ¬І»№эЛЧ»°ЛµµГєГЈ¬З°ИЛФФКчЈ¬єуИЛіЛБ№Ј¬ФзѕНУРИЛЅ« BMP µДЅУїЪ·вЧ°єГёшОТГЗЦ±ЅУК№УГЈ¬Ж©Из browsermob-proxy-py КЗ Python µДКµПЦЈ¬ОТГЗѕНАґКФКФЛьЎЈ
from selenium import webdriver from browsermobproxy import Server server = Server("D:/browsermob-proxy-2.1.4/bin/browsermob-proxy") server.start() proxy = server.create_proxy() proxy.blacklist(".*google.*", 404) proxy.blacklist(".*yahoo.*", 404) proxy.blacklist(".*facebook.*", 404) proxy.blacklist(".*twitter.*", 404) chrome_options = webdriver.ChromeOptions() chrome_options.add_argument("--proxy-server={0}".format(proxy.proxy)) browser = webdriver.Chrome( executable_path="./drivers/chromedriver.exe", chrome_options = chrome_options ) browser.get('http://www.flypeach.com/pc/hk') server.stop() browser.quit() |
ЎЎЎЎ№ШјьґъВлФЪЗ°ГжјёѕдЈ¬КЧПИґґЅЁґъАнЈ¬ФЩНЁ№э proxy.blacklist() Ѕ« googleЎўyahooЎўfacebookЎўtwitter µДЧКФґА№ЅШµфЎЈєуГжµДґъВлєНЗ°Т»ЅЪµДґъАнЙиЦГНкИ«Т»СщЎЈЦґРРіМРтЈ¬Ме»бТ»ПВЈ¬ПЦФЪХвёцТіГжµДґтїЄЛЩ¶ИїмБЛ¶аЙЩЈї
ЎЎЎЎBMP І»ЅцїЙТФА№ЅШЗлЗуЈ¬ТІїЙТФРЮёДЗлЗуЈ¬Хв¶ФЕАіжАґЛµїЙДЬТвТеІ»ґуЈ¬µ«ФЪЧФ¶Ї»ЇІвКФК±Ј¬їЙТФНЁ№эЛьО±ФмІвКФКэѕЭ»№КЗєЬУРТвТеµДЎЈЛьМṩБЛБЅёцЅУїЪ
/proxy/[port]/filter/request єН /proxy/[port]/filter/response УГУЪРЮёД HTTP µДЗлЗуєНПмУ¦Ј¬ѕЯМеµДУГ·ЁїЙТФІОїј №ЩНшµДОДµµЈ¬ґЛґ¦ВФ№эЎЈ proxy.request_interceptor( ''' request.headers().remove('User-Agent'); request.headers().add('User-Agent', 'My-Custom-User-Agent-String 1.0'); ''' ) proxy.response_interceptor( ''' if (messageInfo.getOriginalUrl().contains("remote/searchFlights")) { contents.setTextContents('Hello World'); } ''' ) |
ЎЎЎЎЛДЎўSelenium ИзєОЕАИЎ Ajax ЗлЗуЈї
ЎЎЎЎµЅХвАпЈ¬ОКМв±дµГФЅАґФЅУРТвЛјБЛЎЈ¶шЗТОТГЗ·ўПЦЈ¬УГ Selenium ЧцЕАіжЈ¬ЦРНѕИ·Кµ»бУцµЅёчЦЦёчСщµДОКМвЈ¬µ«ЛжЧЕОКМвµД·ўПЦµЅЅвѕцЈ¬ОТГЗ»ЁФЪ Selenium ЙПГжµДК±јдФЅАґФЅЙЩБЛЈ¬ёь¶аµДКЗФЪСРѕїЖдЛыµД¶«ОчЈ¬ИздЇААЖчµДМШРФЈ¬дЇААЖчІејюµД±аРґЈ¬їЙ±аіМКЅµДґъАн·юОсЖчЈ¬ТФґЛАґёЁЦъ Selenium ЧцµДёьєГЎЈ
ЎЎЎЎ»№јЗµГЗ°ГжМбµЅµДТ»ёцОКМвВрЈїИз№ыТЄЕАИЎµДДЪИЭФЪ Ajax ЗлЗуµДПмУ¦ЦРЈ¬¶шФЪТіГжЙПІўГ»УРМеПЦЈ¬ХвЦЦЗйїцёГИзєОЕАИЎДШЈїОТГЗїЙТФЦ±ЅУЕА Ajax ЗлЗуВрЈїКВКµЙПЈ¬ОТГЗєЬДСЧцµЅЈ¬µ«І»КЗЧцІ»µЅЎЈ
ЎЎЎЎНЁ№эЙПТ»ЅЪ¶Ф BMP µДЅйЙЬЈ¬ОТГЗБЛЅвµЅ BMP їЙТФА№ЅШІўРЮёДЗлЗуµД±ЁОДЈ¬ОТГЗїЙТФЅшТ»ІЅІВПлЈ¬јИИ»ЛьїЙТФРЮёД±ЁОДЈ¬ДЗїП¶ЁТІїЙТФДГµЅ±ЁОДЈ¬Ц»КЗХвёц±ЁОДОТГЗµДіМРтёГИзєОµГµЅЈїЙПТ»ЅЪОТГЗМбµЅБЛБЅёцЅУїЪ /proxy/[port]/filter/request єН /proxy/[port]/filter/responseЈ¬ЛьГЗїЙТФЅУКЬТ»¶О JS ґъВлАґРЮёД HTTP µДЗлЗуєНПмУ¦Ј¬ЖдЦРОТГЗїЙТФНЁ№э contents.getTextContents() Аґ·ГОКПмУ¦µД±ЁОДЈ¬Ц»КЗХв¶ОґъВлФЛРРФЪФ¶іМ·юОсЖчЙПЈ¬єНОТГЗµДґъВлФЪБЅёцНкИ«І»Н¬µДКАЅзАпЈ¬ИзєО°СЛьґ«ёшОТГЗДШЈї¶шЗТЈ¬Хв¶О JS ґъВлµДПЮЦЖ·ЗіЈСПёсЈ¬ОТГЗПлНЁ№эХвёцµШ·ЅДГµЅХвёц±ЁОДјёєхКЗІ»їЙДЬµДЎЈ
ЎЎЎЎµ«Ј¬В·ЧЬКЗУРµДЎЈ
ЎЎЎЎОТГЗ»Ш№эН·Аґїґ BMP µДОДµµЈ¬·ўПЦ BMP МṩБЛБЅЦЦДЈКЅ№©ОТГЗК№УГЈє¶АБўДЈКЅЈЁStandaloneЈ©єН З¶ИлДЈКЅЈЁEmbedded ModeЈ©ЎЈ¶АБўДЈКЅѕНКЗПсЙПГжДЗСщЈ¬BMP ЧчОЄТ»ёц¶АБўµДУ¦УГ·юОсЈ¬ОТГЗµДіМРтНЁ№э RESTful ЅУїЪУлЖдЅ»»ҐЎЈ¶шЗ¶ИлДЈКЅФтІ»РиТЄПВФШ BMP їЙЦґРРОДјюЈ¬Ц±ЅУНЁ№э°ьµДРОКЅТэИлµЅОТГЗµДіМРтЦРАґЎЈїЙП§µДКЗЈ¬З¶ИлДЈКЅЦ»Ц§іЦ Java УпСФЈ¬µ«ХвТІБДК¤УЪОЮЈ¬УЪКЗОТК№УГ Java РґБЛёцІвКФіМРтіўКФБЛТ»°СЎЈ
ЎЎЎЎКЧПИТэИл browsermob-core °ьЈ¬
ЎЎЎЎ<dependency>
ЎЎЎЎ<groupId>net.lightbody.bmp</groupId>
ЎЎЎЎ<artifactId>browsermob-core</artifactId>
ЎЎЎЎ<version>2.1.5</version>
ЎЎЎЎ</dependency>
ЎЎЎЎИ»єуІОїј№ЩНшОДµµРґПВПВГжµДґъВлЈЁНкХыґъВлјы ХвАпЈ©Ј¬ХвАпѕНїЙТФїґµЅЗ¶ИлДЈКЅµДєГґ¦БЛЈ¬УГУЪ BMP А№ЅШґ¦АнµДґъВлєНОТГЗЧФјєµДґъВ봦УЪН¬Т»ёц»·ѕіПВЈ¬¶шЗТ Java УпСФѕЯУР±Х°ьµДМШРФЈ¬ОТГЗїЙТФєЬјтµҐµДИЎµЅ Ajax ЗлЗуµДПмУ¦±ЁОДЈє
BrowserMobProxyproxyServer=newBrowserMobProxyServer(); proxyServer.start(0); proxyServer.addRequestFilter((request,contents,messageInfo)->{ System.out.println("ЗлЗуїЄКјЈє"+messageInfo.getOriginalUrl()); returnnull; }); StringajaxContent=null; proxyServer.addResponseFilter((response,contents,messageInfo)->{ System.out.println("ЗлЗуЅбКшЈє"+messageInfo.getOriginalUrl()); if(messageInfo.getOriginalUrl().contains("ajax")){ ajaxContent=contents.getTextContents(); } }); |
ЎЎЎЎИз№ыДгКЗёц .Net guyЈ¬їЙТФК№УГ Fiddler МṩµД FiddlerCoreЈ¬FiddlerCore ѕНПаµ±УЪ BMP µДЗ¶ИлДЈКЅЈ¬єНХвАпµД·Ѕ·ЁАаЛЖЎЈХвАпУРТ»ЖЄєЬєГµДОДХВЅІЅвБЛИзєОК№УГ .Net єН FiddlerCore А№ЅШЗлЗуЎЈ
ЎЎЎЎјИИ»ФЪ Java »·ѕіПВЅвѕцБЛХвёцОКМвЈ¬ДЗГґ Python У¦ёГТІГ»ОКМвЈ¬µ«КЗ BMP µДЗ¶ИлДЈКЅІўІ»Ц§іЦ Python ФхГґ°мДШЈїУЪКЗОТТ»Ц±ФЪС°ХТТ»їо»щУЪ Python µДДЬМжґъ BMP µД№¤ѕЯЈ¬їЙП§Т»Ц±І»ИзФёЈ¬ОґДЬХТµЅВъТвµДЎЈµЅЧоєуЈ¬ОТјёєхТЄПВЅбВЫЈєPython + Selenium єЬДСКµПЦ Ajax ЗлЗуµДЕАИЎЎЈ
ЎЎЎЎМмОЮѕшИЛЦ®В·Ј¬Ц±µЅОТУцµЅБЛ harЎЈ
ЎЎЎЎУРТ»МмОТѕІПВРДАґ°С BMP µДОДµµ·АґёІИҐїґБЛєГјё±йЈ¬Ц®З°ОТїґОДµµµДП°№Я¶јКЗУГК±ФЩІйЈ¬µ«ХвґО°С BMP µДОДµµґУН·µЅОІїґБЛјё±йЈ¬ТІКЗПЈНыДЬґУЦРС°ХТµгЦлЛїВнјЈЎЈ¶шКВКµЙПЈ¬»№Хж±»ОТ·ўПЦБЛµгКІГґЎЈТтОЄ Python Ц»ДЬНЁ№э RESTful ЅУїЪУл BMP Ѕ»»ҐЈ¬ДЗГґГїТ»ёцЅУїЪОТ¶јІ»ДЬ·Е№эЈ¬УРТ»ёцЅУїЪТэЖрБЛОТµДЧўТвЈє/proxy/[port]/harЎЈ
ЎЎЎЎХвёцЅУїЪЛдИ»Ц®З°ТІЙЁ№эјёСЫЈ¬µ«µ±К±ІўІ»ЦЄµАХвёц har КЗКІГґТвЛјЈ¬ЛщТФ¶јКЗТ»ВУ¶ш№эЎЈµ«ДЗМмРДСЄАґі±Ј¬МШТвИҐІйБЛТ»ПВ har µДЧКБПЈ¬ІЕ·ўПЦХвКЗТ»ЦЦМШКвµД JSON ёсКЅµД№йµµОДјюЎЈHAR И«іЖ HTTP Archive FormatЈ¬НЁіЈУГУЪјЗВјдЇААЖч·ГОКНшХѕµДЛщУРЅ»»ҐЗлЗуЈ¬ѕшґу¶аКэдЇААЖчєН Web ґъАн¶јЦ§іЦХвЦЦёсКЅµД№йµµОДјюЈ¬УГУЪ·ЦОц HTTP ЗлЗуЈ¬ТтОЄ№г·єµДУ¦УГЈ¬W3C ЙхЦБ»№Мбіц HAR µД№ж·¶Ј¬ДїЗ°»№ФЪІЭёеЅЧ¶ОЎЈ
ЎЎЎЎ/proxy/[port]/har ЅУїЪУГУЪґґЅЁТ»·ЭРВµД har ОДјюЈ¬Selenium Жф¶ЇдЇААЖчєуЛщУРµДЗлЗу¶јЅ«±»јЗВјµЅХв·Э har ОДјюЦРЈ¬И»єуНЁ№э GET ЗлЗуЈ¬їЙТФ»сИЎµЅХв·Э har ОДјюµДДЪИЭЈЁJSON ёсКЅЈ©ЎЈhar ОДјюµДДЪИЭАаЛЖУЪПВГжХвСщЈє
ЎЎЎЎ{
ЎЎЎЎ"log": {
ЎЎЎЎ"version" : "1.2",
ЎЎЎЎ"creator" : {},
ЎЎЎЎ"browser" : {},
ЎЎЎЎ"pages": [],
ЎЎЎЎ"entries": [],
ЎЎЎЎ"comment": ""
ЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎЖдЦР entries КэЧй°ьє¬БЛЛщУР HTTP ЗлЗуµДБР±нЈ¬Д¬ИПЗйїцПВ BMP ґґЅЁµД har ОДјюІўІ»°ьє¬ЗлЗуµДПмУ¦ДЪИЭЈ¬ОТГЗїЙТФНЁ№э captureContent ІОКэАґИГ BMP јЗВјПмУ¦ДЪИЭЈє
ЎЎЎЎcurl -X PUT -d 'captureContent=true' http://localhost:8080/proxy/8081/har
ЎЎЎЎНтКВѕг±ёЈ¬Ц»З·¶«·зЎЈОТГЗїЄКјРґґъВлЈ¬КЧПИНЁ№э proxy.new_har() ґґЅЁТ»·Э har ОДјюЈє
ЎЎЎЎproxy.new_har(options={
ЎЎЎЎ'captureContent': True
ЎЎЎЎ})
ЎЎЎЎИ»єуЖф¶ЇдЇААЖчЈ¬·ГОКТЄЕАИЎµДТіГжЈ¬µИґэТіГжјУФШЅбКшЈ¬ХвК±ОТГЗѕНїЙТФНЁ№э proxy.har Аґ·ГОК har ОДјюЦРµДЗлЗу±ЁОДБЛЈЁНкХыґъВлФЪ ХвАпЈ©Јє
ЎЎЎЎfor entry in proxy.har['log']['entries']:
ЎЎЎЎif 'remote/searchFlights' in entry['request']['url']:
ЎЎЎЎresult = json.loads(entry['response']['content']['text'])
ЎЎЎЎfor key, item in result['data']['flightInfo'].items():
ЎЎЎЎprint(key)
ЎЎЎЎЧЬЅб
ЎЎЎЎХвЖЄІ©їНЧЬЅбБЛ Selenium µДТ»Р©»щґЎУп·ЁЈ¬ІўіўКФК№УГ Python + Selenium їЄ·ўдЇААЖчЕАіжЎЈ±ѕОД»№·ЦПнБЛОТФЪКµјКїЄ·ў№эіМЦРУцµЅµДјёёціЈјыОКМвЈ¬ІўМṩБЛТ»ЦЦ»т¶аЦЦЅвѕц·Ѕ°ёЈ¬°ьАЁґъАнµДК№УГЈ¬А№ЅШдЇААЖчЗлЗуЈ¬ЕАИЎ Ajax ЗлЗуµИµИЎЈКµјщіцХжЦЄЈ¬НЁ№эТ»ПµБРОКМвµДМбіцЈ¬µЅСРѕїЈ¬µЅЅвѕцЈ¬ОТС§П°µЅБЛ·ЗіЈ¶аµД¶«ОчЎЈІ»ЅцТвК¶µЅЦЄК¶№г¶ИµДЦШТЄРФЈ¬¶шЗТёьЦШТЄµДКЗЦЄК¶µДѕЫєПєНИЫБ¶ЎЈОТТ»Ц±ИПОЄЦЄК¶µД№г¶И±ИЙо¶ИёьЦШТЄЈ¬Ц»УРД㶮µДФЅ¶аЈ¬ДгІЕУРїЙДЬЅУґҐёь¶аµД¶«ОчЈ¬ДгµДЛјВ·ІЕёь·ЕµГїЄЈ»Йо¶И№МИ»ТІЦШТЄЈ¬µ«НщНщ»бИГИЛѕЦПЮУЪЧФјєµДдцОРЦ®ЦРЎЈµ«ЦЄК¶µД№г¶ИІ»КЗМмВнРРїХЈ¬РиТЄІ»¶ПµДЧЬЅбМбБ¶Ј¬ИЪ»б№бНЁЈ¬РОіЙЧФјєµДЦЄК¶МеПµЈ¬ХвСщІЕІ»ЦБУЪ±»·±¶аµДЦЄК¶µгЛщА§ИЕЎЈ
ЎЎЎЎБнНвЈ¬ОТТІТвК¶µЅФД¶БПоДїОДµµµДЦШТЄРФЈ¬РДЖЅЖшєНµДЅ«ПоДїОДµµґУН·µЅОІФД¶БТ»±йЈ¬УцµЅІ»¶®µДЈ¬ѕНИҐІйХТЧКБПЈ¬¶шІ»КЗЦ»МфЧФјєЦЄµА»тёРРЛИ¤µДЈ¬ХвСщ»бµГµЅТвПлІ»µЅµДКХ»сЎЈ
ЎЎЎЎ±ѕОДЛщУРФґВл¶јФЪОТµД GitHub ЙПЈ¬ДгїЙТФґУ ХвАп ІйїґНкХыФґВлЎЈ±ѕИЛДЬБ¦УРПЮЈ¬ОДЦРИзУРґнО󣬻¶Уё«ХэЈ¬НыІ»БЯґНЅМЎЈИзУРєГµДПл·ЁєНОКМвЈ¬ТІ»¶УБфСФЖАВЫЎЈ
ЙПОДДЪИЭІ»УГУЪЙМТµДїµДЈ¬ИзЙжј°ЦЄК¶ІъИЁОКМвЈ¬ЗлИЁАыИЛБЄПµІ©ОЄ·еРЎ±а(021-64471599-8017)Ј¬ОТГЗЅ«Бўјґґ¦АнЎЈ












