

下面这张图也是这个意思:

具体来说,input data会被Hadoop切割为固定大小的input splits,Hadoop 会为每个split creates一个map task,map task会对split中的每一个record运行user-defined map function. 对于大部分job来说,a good split size是一个HDFS block,128MB。Hadoop尽量通过data locality optimization来让map task运行在存有input data的节点上。如果不行,就选择同一个rack上的其它node,如果还不行,就选择旁边rack上的node。
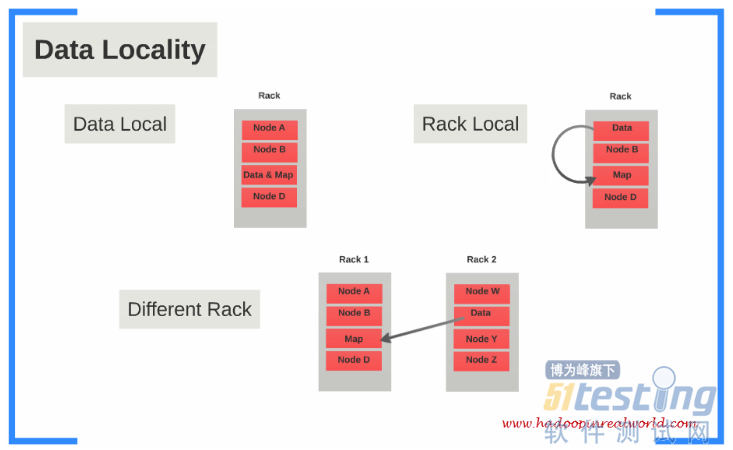
reduce就没有data locality一说了,input都是通过网络传过去的。这中间还会有一个shuffle&&sort的过程,通常就是通过一个hash function来把相同的key放在一起,保证对于每一个given key来说,所有的records都在一个partition里。所以当reducer处理的时候可以保证input data都是按照key sorting好的了。
Hadoop Streaming
首先,说说distributed cache, 比如你有个文件需要在运算的时候用到如何传给map/reduce task呢?答,是通过-files/-archives/-libjars 传过去的,比如-files mapper.py, reducer.py, some_file.txt, 此时some_file.txt会被传到需要的node上,每个node只需要一个copy,注意some_files.txt是read only的,所以可以被tasks共享。 archives是打包传输,libjars是传jar格式。
following method 可以创建archive文件:
tar -cf pack.tar a.txt b.txt c.txt
读的时候就用如下path:
pack.tar/a.txt,pack.tar/b.txt, pack.tar/c.txt
其次,说说environment variable, hadoop streaming可以通过-D some_var="some value"的方式把变量传给nodes。
第三,从task的角度可以通过reporter:status: 的方式把report传回去。
下面举个word count的实际例子,比如统计wikipedia的word count:
mapper.py #!/usr/bin/python import sys import re reload(sys) sys.setdefaultencoding('utf-8') # required to convert to unicode for line in sys.stdin: try: article_id, text = unicode(line.strip()).split('\t', 1) except ValueError as e: continue words = re.split("\W*\s+\W*", text, flags=re.UNICODE) for word in words: print "%s\t%d" % (word.lower(), 1) reducer.py #!/usr/bin/python import sys current_key = None word_sum = 0 for line in sys.stdin: try: key, count = line.strip().split('\t', 1) count = int(count) except ValueError as e: continue if current_key != key: if current_key: print "%s\t%d" % (current_key, word_sum) word_sum = 0 current_key = key word_sum += count if current_key: print "%s\t%d" % (current_key, word_sum) |
本机运行:
cat wiki.txt | ./mapper.py | sort | ./reducer.py Hadoop streaming: OUT_DIR="wiki_wordcount_result_"$(date +"%s%6N") NUM_REDUCERS=8 hdfs dfs -rm -r -skipTrash ${OUT_DIR} > /dev/null yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapred.jab.name="Streaming wordCount" \ -D mapreduce.job.reduces=${NUM_REDUCERS} \ -files mapper.py,reducer.py \ -mapper "python mapper.py" \ -combiner "python reducer.py" \ -reducer "python reducer.py" \ -input /wiki/en_articles_part \ -output ${OUT_DIR} > /dev/null |
好了,今天就写到这~
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












