

爬虫主要流程
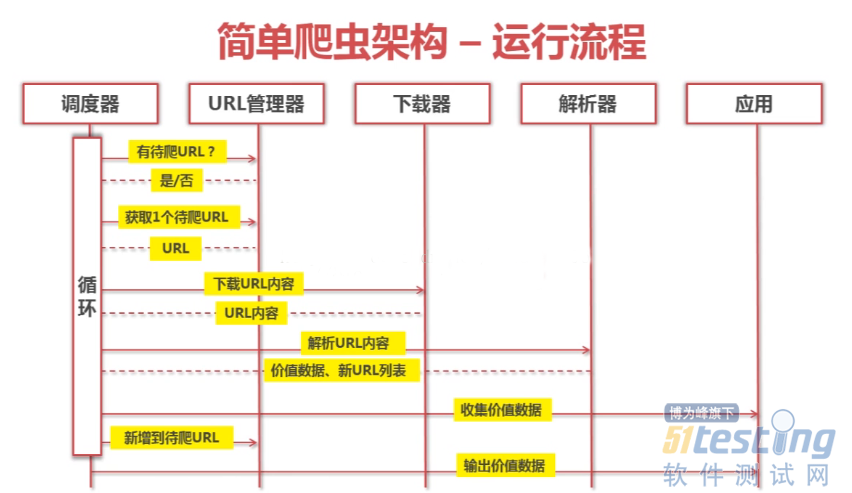
调度器
主调度程序主要是管理上图中其余几个模块的,然后循环的执行这几个模块进行爬取信息,直到条件达到(爬取够一定数量)跳出循环。
URL管理器
每爬取一个网页的有用信息后,并把有用的URL爬取下来放入URL管理器中,等下次循环的爬取可以直接从这个管理器中获取URL
网页下载器
这里用到下载网页的库是urllib2,通过库把url指定的网页的html源代码下载下来,存入urllib2对象
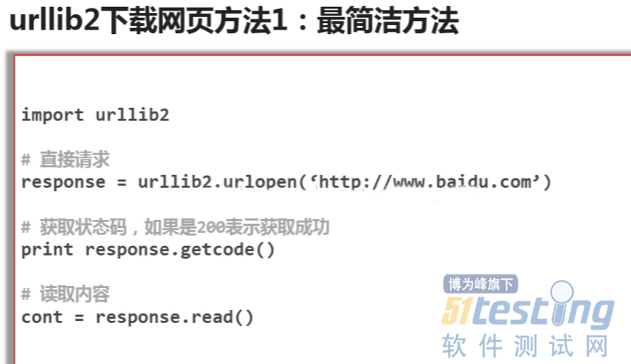
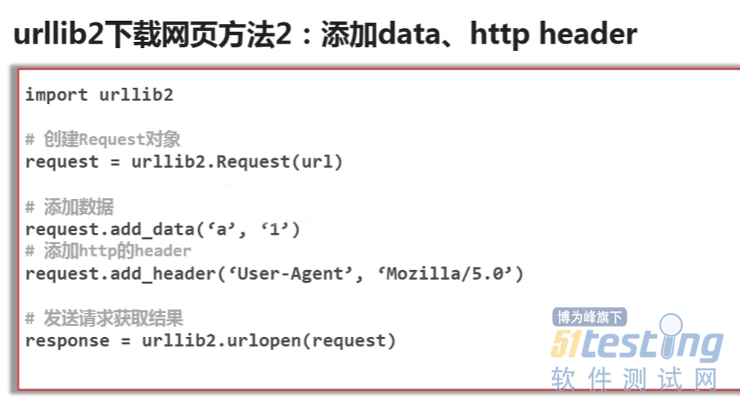
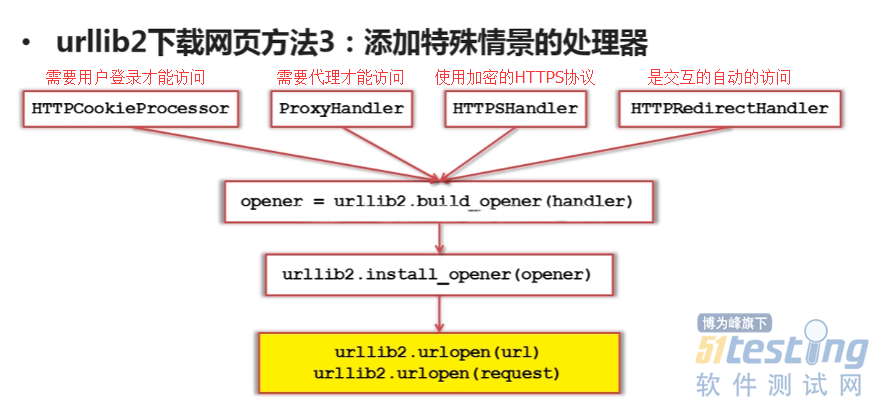
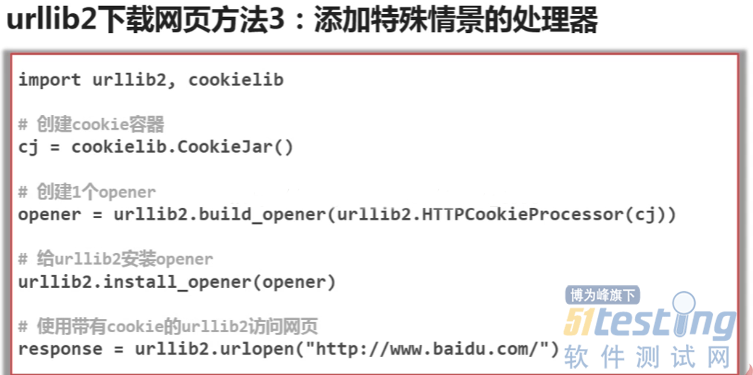
以下是几种简单的下载网页方式
●代码演示
#!/usr/bin/env python # -*_coding:utf8-*- import urllib2 #下载网页的库 import cookielib url = 'http://www.baidu.com' print '第一种方法' response1 = urllib2.urlopen(url) print response1.getcode() #请求状态码 print len(response1.read()) #read爬取网页信息 print '第二种方法,添加头部信息,模拟浏览器访问' request = urllib2.Request(url) #生成一个请求对象 request.add_header('user-agent','Mozilla/5.0') #在请求对象里添加请求头部信息 response2 = urllib2.urlopen(request) print response2.getcode() #请求状态码 print len(response2.read()) #read爬取网页信息 print '第三种方法,有的浏览器需要登录,需添加cookie处理功能' cj = cookielib.CookieJar() #创建一个cookie容器对象 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) #创建一个具有HTTPcookieProcessor方法的opener对象 urllib2.install_opener(opener) #给urllib2安装这个opener,urllib2就有了cookie处理的能力 response3 = urllib2.urlopen(url) print response3.getcode() #请求状态码 print response3.read() #read爬取网页信息 |
解析器
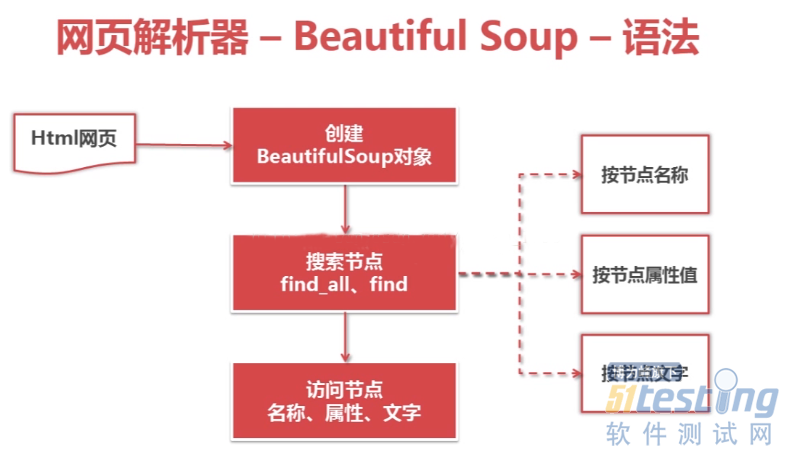
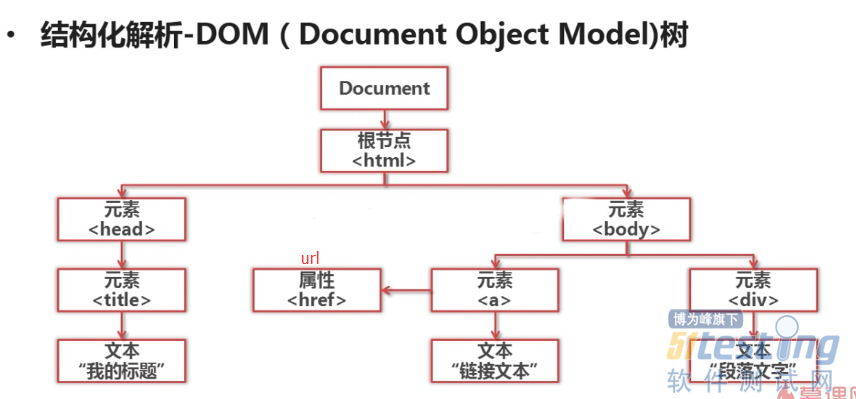
●解析器的功能是用来解析下载下来的网页,这里解析网页主要用到的第三方库就是BeautifulSoup,通过这个库然后根据html的标签爬取我们想要的信息。
●代码演示
#!/usr/bin/env python #-*-coding=utf8-*- from bs4 import BeautifulSoup import re html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <div class="para" label-module="para">在计算机科学中<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and </div><a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ #创建解析html的soup对象 soup = BeautifulSoup( html_doc, #HTML文档 'html.parser', #HTML解释器 from_encoding='utf-8' #HTML文档使用的编码 ) # 搜索节点标签方法 find_all/find(name,attrs,string) #node = soup.find_all('a',class_='abc',string='python') #class加下划线是为了区别关键字 #node.name #获取你标签名字 #name['href']#以字典的形式访问href属性的值 #node.get_text()#获取节点中的链接文字 print '获取所有链接' node = soup.find_all('a') print 'node',node for link in node: print link.name, link['href'], link.get_text() print '获取指定url链接' node_link = soup.find('a', class_='sister') print node_link.name, node_link['href'], node_link.get_text() print '使用正则表达进行模糊匹配' node = soup.find('div', class_='para').find_all('a', href=re.compile('exa')) for node_link in node: print node_link.name, node_link['href'], node_link.get_text() #1、compile() #编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。) #格式: #re.compile(pattern,flags=0) #pattern: 编译时用的表达式字符串。 #flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的 |
应用
●最后就可以把解释器解释出来的数据写入相应的文件中,提供一定的作用。
github源代码
https://github.com/TerryZjl/Python/tree/master/example
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












