

九.数据管理
1.数据块
HDFS的应用场景是大的数据集下,且数据只需要写一次但是要读取一到多次并且支持流速读取数据。一般情况下一个块大小为128MB,因此一个文件被切割成128MB的大块,且每个快可能分布在不同的DataNode。
2.复制管道
当客户端在复制系数是3的条件下写数据时,NameNode通过目标选择算法收到副本要写入的DataNode的集合,第1个DataNode开始一部分一部分的获取数据,把每个部分存储到本地并转发给第2个DataNode,第2个DataNode同样的把每个部分存储到本地并转发给第3个DataNode,第3个DataNode将数据存储到本地,这就是管道复制。
十.可访问性
HDFS提供了多种访问方式,比如FileSystem Java API、C language wrapper for this Java API和REST API,而且还支持浏览器直接浏览。通过使用NFS gateway,客户端可以在本地文件系统上安装HDFS。
1.FSShell
HDFS使用目录和文件的方式管理数据,并提供了叫做FS shell的命令行接口,下面有一些简单的命令:

FS shell sample
2.DFSAdmin
DFSAdmin命令集合用于管理HDFS集群,这些命令只有集群管理员可以使用,下面有一些简单的命令:

DFSAdmin sample
3.浏览器接口
正常的HDFS安装都会配置一个web服务,通过可配的TCP端口对外暴露命名空间,从而使得用户可以通过web浏览器查看文件内容。
十一.空间垃圾回收
1.文件删除与恢复
如果垃圾回收配置打开,通过FS shell移除的文件不会立刻删除,而是会移动到一个垃圾文件专用的目录(/user/<username>/.Trash),类似回收站,只要文件还存在于那个目录下,则随时可以被回复。绝大多数最近删除的文件都被移动到了垃圾目录(/user/<username>/.Trash/Current),并且HDFS每个一段时间在这个目录下创建一个检查点用于删除已经过期的旧的检查点,详情见expunge command of FS shell。在垃圾目录中的文件过期后,NameNode会删除这个文件,文件删除会引起这个文件的所有块的空间空闲,需要注意的是在文件被删除之后和HDFS的可用空间变多之间会有一些时间延迟(个人认为是垃圾回收机制占用的时间)。下面是一些简单的理解删除文件的例子:
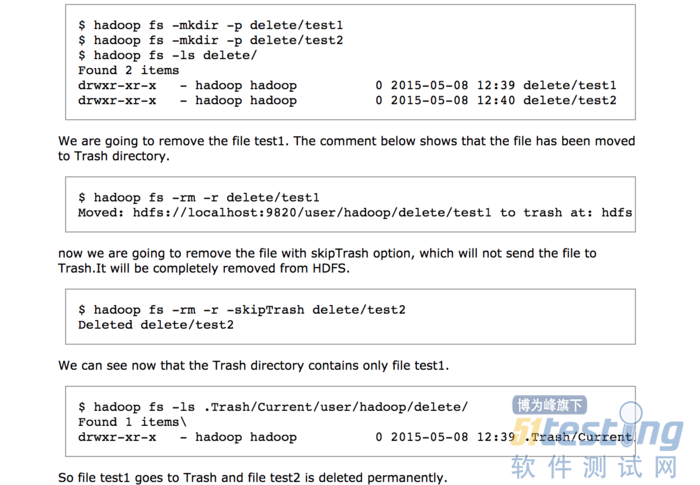
FS shell delete sample
2.减小复制系数
当文件复制系数减小时,NameNode会选择多余的需要删除的副本,在收到心跳包时将删除信息发送给DataNode。和上面一样,这个删除操作也是需要一些时间后,才能在集群上展现空闲空间的增加。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。











