

作为渗透测试人员,仅仅利用漏洞攻击目标然后获得一个Shell是远远不够的。尽管拿到Shell是一件很好的事情(毕竟这是我们渗透测试中非常重要的一部分),但是对客户来说真正的价值是证明有效的风险来自于对漏洞的成功利用。为了回答这个问题,我准备调查分析被攻破的系统数据,试图弄清楚什么是可用的以及数据的泄露对我的客户意味着什么。
通常,我会在SQL数据库中查看大量数据。这可能是一个本地的SQL数据库(通常是MSSQL,SQLite3,MySQL,Oracle等),但有时它是我通过导入CSV文件,JSON数据或其他数据格式创建的数据库。作为一名前DBA(很久很久以前的事情了),看到SQL>提示我会感到非常的舒服。在本文中,我将提供有关从数据库中获取有用数据的一些快速提示。
我将使用一个神奇宝贝Pokedex SQLite3数据库作为我的数据源示例。这个数据库是Eevee创建的工程。特别感谢Eevee提供了这个复杂的数据库。
数据结构
使用.schema命令确定表,索引和其他对象的结构:
sqlite> .schema CREATE TABLE item_pockets ( id INTEGER NOT NULL, identifier VARCHAR(79) NOT NULL, PRIMARY KEY (id) ); CREATE TABLE pokeathlon_stats ( id INTEGER NOT NULL, identifier VARCHAR(79) NOT NULL, PRIMARY KEY (id) ); ... |
这个数据库有几个表。如果你想查看单个表的结构,请指定一个表:
sqlite> .schema pokemon CREATE TABLE pokemon ( id INTEGER NOT NULL, identifier VARCHAR(79) NOT NULL, species_id INTEGER, height INTEGER NOT NULL, weight INTEGER NOT NULL, base_experience INTEGER NOT NULL, "order" INTEGER NOT NULL, is_default BOOLEAN NOT NULL, PRIMARY KEY (id), FOREIGN KEY(species_id) REFERENCES pokemon_species (id), CHECK (is_default IN (0, 1)) ); CREATE INDEX ix_pokemon_order ON pokemon ("order"); CREATE INDEX ix_pokemon_is_default ON pokemon (is_default); |
请注意,.schema命令是 SQLite特定的命令。其他数据库可以使用SHOW TABLES,DESC tablename。本文中显示的大多数其他命令都可以通用于其他任何数据库。
检索部分或全部
我们使用SQL SELECT语句从数据库中检索数据:
sqlite> select * from pokemon; id|identifier|species_id|height|weight|base_experience|order|is_default 1|bulbasaur|1|7|69|64|1|1 2|ivysaur|2|10|130|142|2|1 3|venusaur|3|20|1000|236|3|1 4|charmander|4|6|85|62|5|1 5|charmeleon|5|11|190|142|6|1 6|charizard|6|17|905|240|7|1 7|squirtle|7|5|90|63|10|1 8|wartortle|8|10|225|142|11|1 9|blastoise|9|16|855|239|12|1 10|caterpie|10|3|29|39|14|1 ... |
通过指定*,我们注意到我们想要检索所有的列。如果你只想要几个特定的列,请按照你希望显示的顺序按名称指定所需的列:
sqlite> select id, identifier, weight, height from pokemon; id|identifier|weight|height 1|bulbasaur|69|7 2|ivysaur|130|10 3|venusaur|1000|20 4|charmander|85|6 5|charmeleon|190|11 6|charizard|905|17 7|squirtle|90|5 8|wartortle|225|10 9|blastoise|855|16 10|caterpie|29|3 ... |
该pokemon表有很多记录。如果你只想要前5条记录,请在查询语句的末尾添加LIMIT 5:
sqlite> select id, identifier, weight, height, "order" from pokemon limit 5; id|identifier|weight|height|order 1|bulbasaur|69|7|1 2|ivysaur|130|10|2 3|venusaur|1000|20|3 4|charmander|85|6|5 5|charmeleon|190|11|6 |
独特的数据
个别数据行往往会有重复的值。我们可以通过在查询中使用修饰符DISTINCT来获得唯一的值列表。例如,Pokedex contest_type_names表的结构:
sqlite> .schema contest_type_names CREATE TABLE contest_type_names ( contest_type_id INTEGER NOT NULL, local_language_id INTEGER NOT NULL, name VARCHAR(79), flavor TEXT, color TEXT, PRIMARY KEY (contest_type_id, local_language_id), FOREIGN KEY(contest_type_id) REFERENCES contest_types (id), FOREIGN KEY(local_language_id) REFERENCES languages (id) ); CREATE INDEX ix_contest_type_names_name ON contest_type_names (name); sqlite> select * from contest_type_names; contest_type_id|local_language_id|name|flavor|color 1|5|Sang-froid|épicé|Rouge 1|9|Cool|Spicy|Red 2|5|Beauté|Sec|Bleu 2|9|Beauty|Dry|Blue 3|5|Gr'ce|Sucré|Rose 3|9|Cute|Sweet|Pink 4|5|Intelligence|Amère|Vert 4|9|Smart|Bitter|Green 5|5|Robustesse|Acide|Jaune 5|9|Tough|Sour|Yellow 1|10||Ostrá| 5|10|Síla|| 2|10|Krása|Suchá| |
返回的数据集相当小,但我们可以进一步查看一下。如果我们只对给予 contest type
的独特颜色分配感兴趣,我们该如何操作呢?
sqlite> select distinct(color) from contest_type_names; Rouge Red Bleu Blue Rose Pink Vert Green Jaune Yellow |
条件表达式
通常你会想用条件表达式来过滤返回的数据,这种情况你可以用一个WHERE子句表示。使用WHERE子句允许你指定要返回的数据的性质,将一个或多个列与指定的值相匹配。例如,如果我们只想在pokemon表中看到关于皮卡丘的信息呢?
sqlite> .schema pokemon CREATE TABLE pokemon ( id INTEGER NOT NULL, identifier VARCHAR(79) NOT NULL, species_id INTEGER, height INTEGER NOT NULL, weight INTEGER NOT NULL, base_experience INTEGER NOT NULL, "order" INTEGER NOT NULL, is_default BOOLEAN NOT NULL, PRIMARY KEY (id), FOREIGN KEY(species_id) REFERENCES pokemon_species (id), CHECK (is_default IN (0, 1)) ); CREATE INDEX ix_pokemon_order ON pokemon ("order"); CREATE INDEX ix_pokemon_is_default ON pokemon (is_default); sqlite> select * from pokemon where identifier = "pikachu"; id|identifier|species_id|height|weight|base_experience|order|is_default 25|pikachu|25|4|60|112|32|1 |
除了使用匹配表达式之外,SQLite3还支持通用的比较运算符,如下表所示:
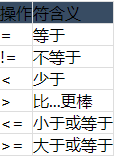
我们用这个来找出是否有比皮卡丘还小的神奇宝贝(从前面的查询来看,它是4分米):
sqlite> select identifier from pokemon where height < 4; caterpie weedle pidgey rattata spearow paras ... |
我们也可以把多个WHERE表达式结合起来。例如,神奇宝贝比皮卡丘还高,但重量较轻?(请注意,在这里我按Enter键来开始一个新行,提示SQLite3产生一个连续提示…>。)
sqlite> select identifier, height, weight from pokemon ...> where height < 4 and weight > 190; klink|3|210 durant|3|330 |
通配符
SQL允许你在你的WHERE子句指定通配符,使用关键字LIKE和_可以匹配任何单个字符,或LIKE和%匹配一组字符。使用这个pokemon_species_name表,我们可以确定所有的genus的值以Dr开始匹配的行:
sqlite> .schema pokemon_species_names CREATE TABLE pokemon_species_names ( pokemon_species_id INTEGER NOT NULL, local_language_id INTEGER NOT NULL, name VARCHAR(79), genus TEXT, PRIMARY KEY (pokemon_species_id, local_language_id), FOREIGN KEY(pokemon_species_id) REFERENCES pokemon_species (id), FOREIGN KEY(local_language_id) REFERENCES languages (id) ); CREATE INDEX ix_pokemon_species_names_name ON pokemon_species_names (name); sqlite> select name, genus from pokemon_species_names where genus like 'Dr%'; name|genus Nidoqueen|Drill Nidoking|Drill Rhydon|Drill Hypotrempe|Dragon Seeper|Drache Horsea|Dragón Horsea|Drago Horsea|Dragon ... Simipour|Drenaje Munna|Dream Eater Musharna|Drowsing Muplodocus|Dragon Viscogon|Drache Goodra|Dragón ... |
请注意,一些genus类型是Dragon和Dragón。如果我们想匹配这两者中的任何一个,我们可以使用_修饰符来匹配o和ó字符:
sqlite> select name, genus from pokemon_species_names where genus like 'Drag_n'; name|genus Hypotrempe|Dragon Horsea|Dragón Horsea|Dragon Hypocéan|Dragon Seadra|Dragón Seadra|Dragon Minidraco|Dragon Dratini|Dragón Dratini|Dragon Draco|Dragon ... |
你也可以通过添加%到表达式的开头和结尾来搜索匹配字符串的中间部分。例如,我们可以用eat这个词搜索任何一个genus:
sqlite> select name, genus from pokemon_species_names ...> where genus like '%eat%'; name|genus Castform|Weather Munchlax|Big Eater Munna|Dream Eater Heatmor|Anteater |
虽然它没有显示在这个输出结果中,但%eat%会匹配开始或结束是eat的值(例如,不需要在前面或后面的字符作为匹配)。
数据排序
有时候你想改变返回的数据的顺序。没问题,你只需要输入ORDER BY并指定你想使用的列。你也可以在ORDER BY子句中添加多个逗号分隔的列。默认情况下,值是按升序排列的,但可以通过将关键字添加DESCENDING到ORDER BY表达式的末尾来修改排序方式。
例如,神奇宝贝数据库中的abilities表公开了标识符信息,默认使用该id字段排序。如果要将排序顺序更改为generation_id列,请添加一个ORDER BY子句:
sqlite> .schema abilities CREATE TABLE abilities ( id INTEGER NOT NULL, identifier VARCHAR(79) NOT NULL, generation_id INTEGER NOT NULL, is_main_series BOOLEAN NOT NULL, PRIMARY KEY (id), FOREIGN KEY(generation_id) REFERENCES generations (id), CHECK (is_main_series IN (0, 1)) ); CREATE INDEX ix_abilities_is_main_series ON abilities (is_main_series); sqlite> select * from abilities order by generation_id; id|identifier|generation_id|is_main_series 1|stench|3|1 2|drizzle|3|1 3|speed-boost|3|1 4|battle-armor|3|1 5|sturdy|3|1 6|damp|3|1 7|limber|3|1 ... 162|victory-star|5|1 163|turboblaze|5|1 164|teravolt|5|1 10001|mountaineer|5|0 10002|wave-rider|5|0 10003|skater|5|0 10004|thrust|5|0 10005|perception|5|0 ... 189|primordial-sea|6|1 190|desolate-land|6|1 191|delta-stream|6|1 |
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












