

多进程优势:单个进程的崩溃,不会影响其它进程
随之而来的问题是,进程之间,资源不共享,信息不共享,所以进程通讯的问题,是实现多进程协作,必须解决的问题
为解决进程间的通讯,人们常用的方法是 --> 创建一个中间人(队列),作为他们交流的中介...
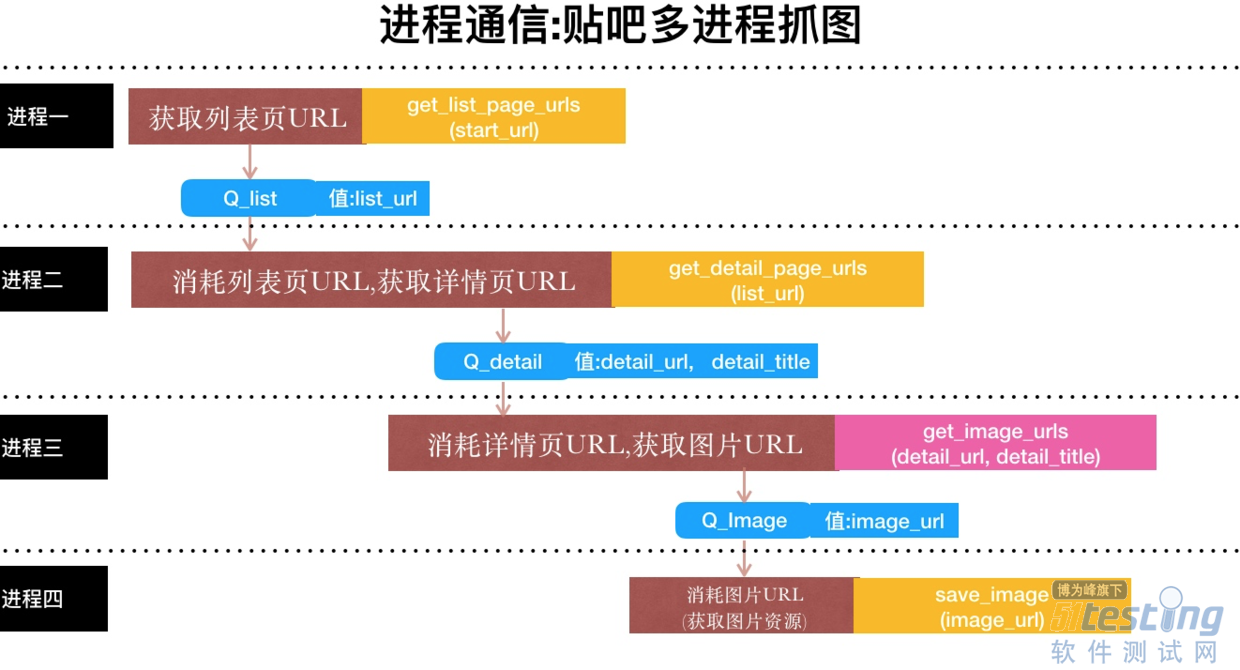
以爬取某贴吧帖子中的所有图片为例:
大致需要四步
一. 获取所有的 帖子的目录
二. 根据帖子的目录,获取 帖子详情页
三. 根据 帖子详情页 的源码,获取内嵌的 图片url信息
四. 根据 图片url信息,下载图片到本地
通信图
动图_脚本运行效果
运行中
from multiprocessing import Process, Queue import time from time import sleep import requests from lxml import etree import os, sys import re class BaiduTb(object): def __init__(self, tb_name): self.start_url = "https://tieba.baidu.com/f?ie=utf-8&kw=" + tb_name self.q_list = Queue() self.q_detail = Queue() self.q_image = Queue() self.headers = { "User-Agent": "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0) " } self.p1 = None self.p2 = None self.p3 = None self.p4 = None # 获取响应内容 def get_response_content(self, url): response = requests.get(url, headers = self.headers) print("-->",response) return response.content # 获取下一个网页url def get_next_url(self, now_url): content = self.get_response_content(now_url) # 将响应信息转换为element对象 html = etree.HTML(content) # 通过xpath获取下一页的链接 next_url = "http:" + html.xpath('//a[@class="next pagination-item "]/@href')[0] return next_url def get_list_page_urls(self, q_list): while True: try: sleep(1) q_list.put(self.start_url) self.start_url = self.get_next_url(self.start_url) except: print("主程序..") def get_detail_page_urls(self, q_list, q_detail): while True: sleep(1) try: if not q_list.empty(): list_url = q_list.get(True) else: continue except: print("第二进程已完成..") content = self.get_response_content(list_url) # 将响应信息转换为element对象 html = etree.HTML(content) # 获取 标题 和url 列表 detail_titles_list = html.xpath('//*[@id="thread_list"]//div/div[2]/div[1]/div[1]/a/text()') detail_urls_list = html.xpath('//*[@id="thread_list"]//div/div[2]/div[1]/div[1]/a/@href') # 将"标题"和 url 增加到 详情页队列中 for i in range(len(detail_titles_list)): detail_title = detail_titles_list[i] detail_url = "https://tieba.baidu.com" + detail_urls_list[i] temp_tuple = (detail_title, detail_url) q_detail.put(temp_tuple) def get_image_urls (self, q_detail, q_image): while True: sleep(3) try: detail = q_detail.get() detail_title = detail[0] detail_url = detail[1] except Exception as e: print("第三进程已完成") # 获取详情页所有图片的url content = self.get_response_content(detail_url) # 将响应信息转换为element对象 html = etree.HTML(content) # 通过xpath获取下一页的链接 image_urls = html.xpath('//cc//img/@src') for i in range(len(image_urls)): image_url = image_urls[i] temp_image_info = (detail_title, image_url) q_image.put(temp_image_info) def save_image(self, q_image): while True: sleep(3) try: if not q_image.empty(): image_info = q_image.get() image_name = re.match(r".*(.{10})", image_info[1]).group(1) print("图片名称为:", image_name, "图片地址为:", image_info[1], "帖子标题为:", image_info[0]) # 尝试根据帖子名称,创建新文件夹 try: os.mkdir("./%s"%(image_info[0])) except: pass new_file_path = "./%s/%s"%(image_info[0],image_name) with open(new_file_path, "wb") as f: data = self.get_response_content(image_info[1]) f.write(data) if (self.q_list.empty()) and (self.q_detail.empty()) and (self.q_image.empty()): exit() except: print("第四进程已完成") def run(self): print("开始执行") self.p1 = Process(target = self.get_list_page_urls, args=(self.q_list,)) self.p2 = Process(target = self.get_detail_page_urls, args=(self.q_list, self.q_detail,)) self.p3 = Process(target = self.get_image_urls, args=(self.q_detail, self.q_image,)) self.p4 = Process(target = self.save_image, args=(self.q_image,)) self.p1.start() self.p2.start() self.p3.start() self.p4.start() self.p1.join() self.p2.join() self.p3.join() self.p4.join() def main(): name = input("请输入贴吧名称:") beautiful_girl = BaiduTb(name) beautiful_girl.run() if __name__ == '__main__': main() |












